1. 引言
射频指纹(Radio Frequency Fingerprint, RFF)特征由电子元件容差产生,具有唯一性,可用于辐射源个体识别(Specific Emitter identification, SEI),在军事(如敌我识别)和商业(如无线网络安全)领域得到广泛应用,其特征提取、分析成为研究的焦点。
Hall等 [1] 首次定义了RFF概念,提出可将瞬时幅度、小波频率、相位等参数作为指纹特征。文献 [2] 指出将原始数据去除杂波、截断处理后变换到时域、频域、小波域以提取RFF特征,即降维变换特征提取。文献 [3] 指出除降维变换方法外,可直接针对接收信号时间序列提取RFF特征,即直接测量法。文献 [4] 指出制造容差是RFF特征的重要组成因素,引发的相位波动与设备密切相关,因此可通过瞬时相位作为RFF特征参数进行SEI设备识别。文献 [5] 指出韩洁等人 [6] 设计的希尔伯特黄变换和多尺度分形特征的RFF识别方法,在低信噪比和训练样本数量较小的情况下性能较为突出。文献 [7] 提出将瞬态信号二阶谱功率谱密度和互功率谱密度作为RFF特征、基于概率神经网络进行分类的方法。文献 [8] 基于Relief和PCA算法,提出小波系数降维特征识别方法。文献 [9] 对近年来的射频指纹识别、分类技术进行了归纳总结。
但上述研究存在以下不足:一是所识别的终端设备数量较少(考虑最多的终端数为4个),终端之间区分度高,设备增加时特征间隔减小,SEI识别度降低,因此识别模型不具备普适性;二是分类器以神经网络、机器学习为主,方法较为成熟,但对硬件要求较高、数据冗余度高、处理时间长;三是各终端采集数量较大,采样周期较长,无法实现某些辐射源的快速识别(如航空设备)。
针对上述问题,论文以实际中监测的100架某航空设备辐射信号为数据基础,设计特征参数标准数据库建立、RFF分类、优化等模块联合射频指纹识别模型。为提高运算效率、降低数据冗余度,在分析小波系数、瞬时相位、希尔伯特黄变换能量谱、相关系数等特征参数的基础上,基于相关度和阈值理念,在分析单特征分类效果的基础上,定义联合分类流程规则,以达到SEI的目的。
2. 实际问题描述
将天津中国民航产业化基地作为信号采集地点,选择航空广播式自动相关监视系统ADS-B的辐射信号作为数据来源,使用软件定义的无线电平台SM200B作为采集设备。对采集的ADS-B原始数据信号降采样、报头搜索、信息解码、CRC校验、截取,并用相应的飞机唯一标识符标注ADS-B信号,通过归一化以及去除ID信息段的预处理方法,得到用于RFF特征提取与SEI的高质量无线电信号数据集,数据集由相同地点采集的100架某民航客机的信号数据组成,结果见表1和图1所示。

Table 1. High quality dataset of wireless signal
表1. 高质量无线电信号数据集合
其中数据矩阵D中,4000、4800、2分别表示4000行、4800列、I/Q两路信号,标签矩阵Y表征100架飞机编号,且训练集和测试集中每种类别的样本数量是相同的。对于每架飞机而言,数据样本为40条,样本数相对较少,RFF特征提取较为困难。此时面临的实际问题是:在该样本数据受限的情况下,如何通过对数据的分析与处理,提取RFF特征,设计SEI识别模型,并获得设备平均识别率。
3. 问题分析
实际问题中提供了100架某民航客机信号训练集中的数据矩阵D,通过提取区分不同飞机的RFF特征,依据特征参数将采集的信号与100架民航飞机一一对应,达到区分SEI的目的。在此基础上,将识别结果与标签矩阵Y对比,可测试模型的平均识别率,因此上述问题可视为分类问题,即将数据矩阵D分为特定的100类,满足一定的识别率即可。但是与常规分类问题不同的是,该数据矩阵D中,RFF特征参数“是什么”、“有几个”等设备信息未知,因此首先必须通过数据矩阵D估计具有一定区分度的特征参数,将所提取的特征参数或特征参数的组合构建特定特征向量作为识别飞机的参数标准数据库,而后利用采集数据与之对比,将与参数标准数据库中契合度最高的一行对应标签值赋予采集样本,实现数据矩阵的分类或标签的标定。因此问题可通过“数据分析/处理→特征参数标准数据库建立→分类→优化”等过程加以解决。
4. 模型的建立与分析
4.1. 模型假设
1) 不考虑飞机的多普勒效应;
2) 假设数据采集环境相对稳定;
3) 假设样本满足可容性条件;
4) 假设每架飞机的样本数据不具有强相关。
4.2. 模型建立
根据问题分析可知,识别模型总体结构应包括四部分,如图2所示。
数据分析/处理方面,完成奇异数据或冗余数据的过滤(即数据处理),而后分析剩余纯净样本的变化规律,为后续确定能够表征不同设备的RFF特征奠定基础(即数据分析)。文献 [2] 指出系统采集信号后,根据RFF特征提取要求,在尽可能避免引入噪声的前提下,对信号进行下变频、相位补偿、归一化等预处理,该过程已通过无线电平台SM200B完成。在此基础上需进一步分析I/Q数据的规律,以提炼特征参数。
特征参数标准数据库建立方面,通过特征参数选择模块确定能够区分纯净样本数据的RFF特征,构建单个特征值或联合特征向量,合理选择样本,构建与之对应的数据库。其中特征参数可通过主成分分析法、独立分量分析、窗口Fourier变换等理论统计方法获得,也可通过RFF区分度获得。前者侧重理论性,后者侧重实践,论文拟采用后者进行RFF特征提取。如前所述,RFF特征可通过数据降维变换或直接测量方法建立特征参数标准数据库,由于后者未对样本作任何处理,特征信息无丢失,精度较高,在此采用直接测量方法建立特征数据库。目前广泛用于SEI的RFF特征参数包括小波系数、时域包络、频谱特征、调制域特征、频率偏移、分形维数、程序时间、相位偏移、分布函数等多个特征值 [2],本节在分析上述特征可用性基础上,提取能够区分飞机的RFF特征,并建立与之对应的数据库。
分类方面,在定义分类规则的基础上,合理选择分类器或定义分类规则,对采集数据进行标签标的,实现数据与飞机的一一对应。常见分类器包括贝叶斯分类器、最近邻分类器、二元分类树、神经网络等广泛应用的统计决策分类器,和SVM为基础的统计学习理论分类器 [5]。前者在训练样本比较大时方可接近最优分类性能,后者可针对有限的训练样本在复杂度和学习能力之间进行折中,但二者对硬件要求较高。论文另辟蹊径,在提取特征参数和定义分类规则的前提下,基于采样数据的相关度(或相关系数),合理设定阈值,进行数据分类。阈值设定方面,可通过手工调整参数或优化算法实现,为简化分析,在此采用前者。
优化过程为权值调节过程,该过程将采用手工设定参数的方式进行。
4.3. 特征参数分析
4.3.1. 小波系数区分度分析
小波变换包括连续小波变换和离散小波变换,在此采用后者,表达式为
在小波函数
基中,db1函数是紧支撑标准正交小波,比其它小波效率更高,在此采用db1进行小波变换 [10]。离散小波变换获得D1、A1、D2、A2四个小波系数,将小波系数作为RFF特征参数可通过四种方式实现:一是选择某些小波系数作为特征,信号进行小波变换后,小波系数已经完整表达了原始数据信息,若将全部小波系数打包作为RFF特征,则徒增计算复杂度,可选择分类效果较好的某些系数作为特征;二是选择小波系数的统计值作为RFF特征,如高/低频系数平均值、绝对平均值等,维数降低,分类速度较快;三是对小波系数作线性或非线性变换,降低噪声影响,但频段内时间信息丢失;四是分尺度平均能量、模极大值等其它方法 [11]。本节采用第一种方式,避免采样信号的频域成分丢失,降低计算复杂度。
对于给定数字序列
,其包络曲线为
,幅值为
。通过分析I/Q数据的包络和幅值小波系数可知,对各飞机而言,幅值没有区分度,时域
包络存在一定差别,为此对包络作小波变换,部分结果如图3所示。结果表明,A1、A2小波系数变化规律一致,D1、D2基本无法区分各飞机信号,因此后面将A1作为特征参数之一用于分类识别。
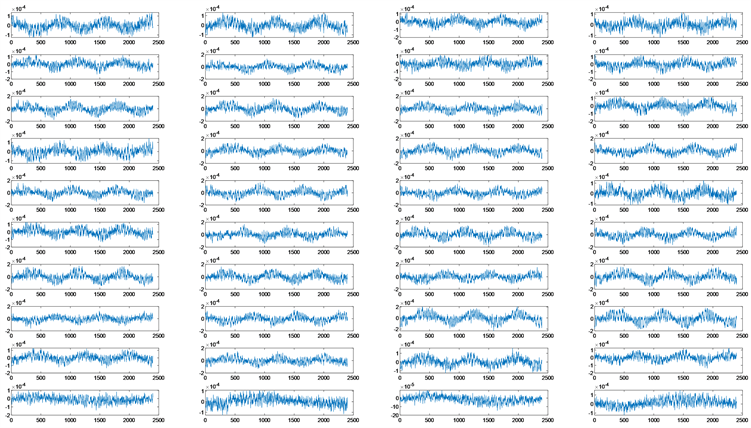

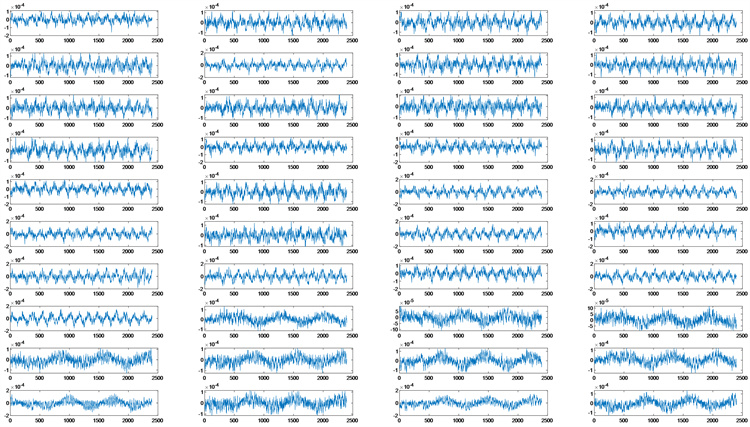
Figure 3. Comparison chart of wavelet coefficient from first three aircrafts
图3. 前3架飞机小波系数A1对比图
那么下一步面临着特征值A1的构建问题。对于该问题,由于小波系数A1在任意时刻为随机变量,那么任意飞机A1系数的集合为随机过程,且该随机过程并非具有平稳特征。由随机过程可知,其特征值包括均值、方差、相关系数等。对于问题中的采样数据而言,多架飞机存在均值为零的情况,若采用均值作为特征值,无疑数据区分度降低,方差亦如此,因此本节直接选取任意飞机的M行数据的A1系数作为特征值数据库,尽可能避免RFF特征丢失。
4.3.2. 瞬时相位区分度分析
对于同一个飞机设备而言,制造容差引发的相位波动是存在区间限制的,那么在此区间内所采集数据的相位特性具有一定的相关性。正是基于该实际,文献 [1] 指出可通过瞬时相位作为RFF特征参数,以识别SEI设备,其中相位表达式为
采集数据对应的瞬时相位仿真结果如图4所示。从结果中不难看出,任意样本的瞬时相位均为随机变量,那么任意飞机的瞬时相位集合也为随机过程,且该相位并非具有平稳特征。与小波系数类似,为简化计算,特征参数统一,在此选择任意飞机的Q行数据的瞬时相位作为特征值数据库。
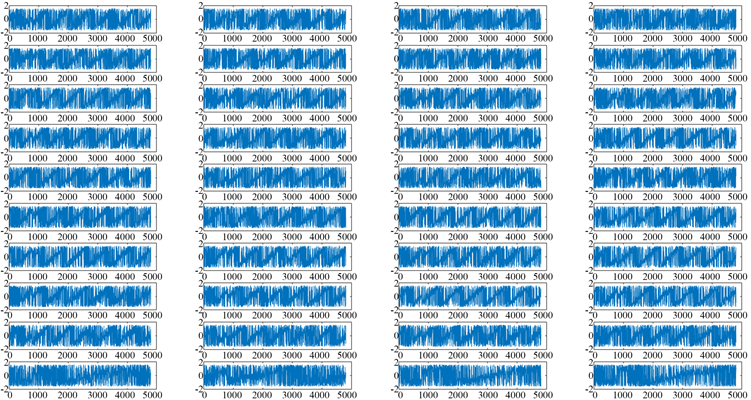
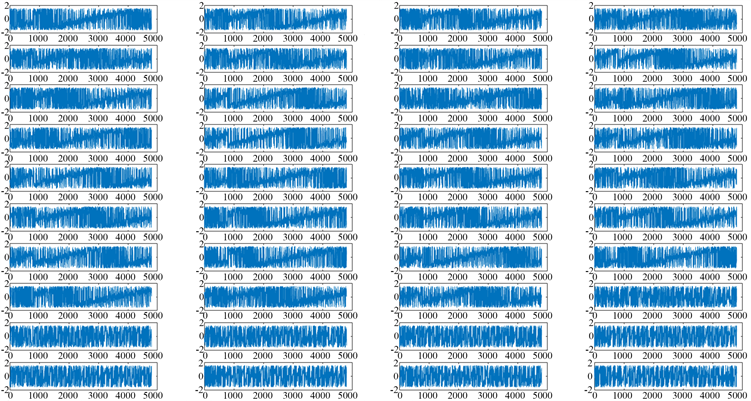
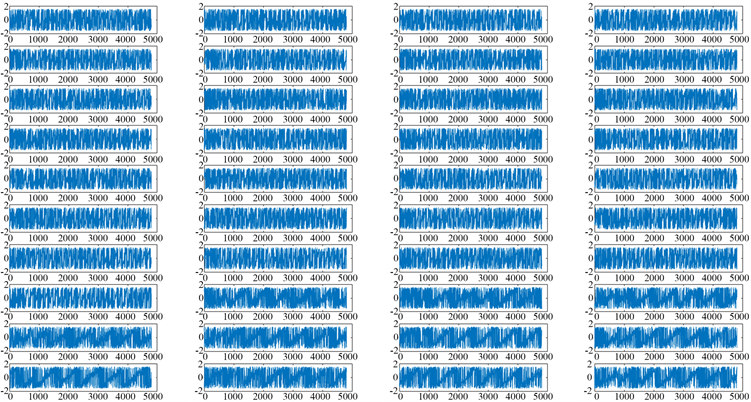
Figure 4. Comparison chart of instant phase from first three aircrafts
图4. 前3架飞机瞬时相位对比图
4.3.3. 希尔伯特黄变换能量谱区分度分析
希尔伯特黄变换和多尺度分形特征在低信噪比和训练样本数量较小的情况下识别性能尤其突出,因此有必要分析希尔伯特黄变换谱。3D-Hilbert能量谱定义如下:对于输入信号
,可依据EMD模型分解为固有模态函数IMF与残余函数
之和,即
对每一个IMF作希尔伯特变换
其中
式中
表示瞬时幅度,
表示瞬时相位,
表示瞬时频率。于是希尔伯特变换能量谱表示为
即为希尔伯特黄变换能量谱。以第一行数据为例,EMD分解、Hilbert Huang变换谱、边际谱、3D-Hilbert能量谱如图5所示。结果表明,
对应的各能量谱没有明显区别,那么便无法引入差分盒维数和多重分形等特征参数。由于HHT在训练样本较少的情况下具有明显优势,为了尽可能保留HHT谱信息,需继续提取HHT特征。进一步分析结果可知,
经过EMD分解后的IMF瞬时频率能量集中于IMF1、IMF2和IMF3三个波形,且对于不同飞机而言,三者对应的HHT谱分量之间存在差异。同时不同飞机三个参数对应的HHT变换结果差异性并不相同,差异性最大的是IMF2,其次为IMF1和IMF3,那么须对三者进行加权处理,权值分别为
、
和
(可通过优化算法搜索,为简化分析,在此另
),加权后的结果H作为
的一个特征参数,即
。与小波系数和瞬时相位相同的是,特征参数H也是一个随机过程的一次实现,在此同样取X行数据对应的HHT能量谱作为特征参数,用于后续分类。
4.3.4. 相关系数区分度分析
从4.3.1~4.3.3不难看出,特征参数求解涉及相关系数计算,后者可通过欧式距离、pearson相关性系数、cosine相似度等算法进行计算,三者在一定条件下具有等价关系。由于pearson相关性系数在计算向量之间相关系数时,进行了中心化处理,训练精度较高,因此本节采用pearson相关性系数,其定义为
相关系数具有两个功能:一是用于计算小波系数、瞬时相位、希尔伯特能量谱等特征参数;二是作排他处理,即样本与特征参数对比分类时,若上述三个参数计算结果相同,那么利用样本与特征数据的时域数据直接做相关性计算,将其归为相关系数较大的一类。对于训练数据而言,各飞机训练数据相关系数结果如图6所示。结果表明,大多数飞机的采集数据相互之间不具有相关性,因而该参数可作为区分飞机的RFF之一,也验证了依靠4.3.1~4.3.3节特征参数的相关系数可以实现不同飞机的分类。
4.3.5. 其它参数区分度
同理可对时域包络、FFT谱、概率密度函数、暂态时间等参数进行区分度分析。分析结果表明,前三者基本没有明显的特征,无法对不同飞机的采集数据进行区分,而暂态时间可以作简单分类,但是暂态时间变化规律为随机过程,不便于数学描述与分析,因此后面将不对其作为特征参数进行SEI识别分析。
4.4. 特征参数标准数据库建立
根据4.3节数据分析结果可知,特征参数标准数据库由A1、P、H、
四个参数组成的向量构成,即对M行数据提取小波系数、Q行数据提取瞬时相位、X行数据计算HHT三个IMF分量能量谱、Z行数据计算相关系数,所得结果即为特征参数标准数据库。值得注意的是,参数
是对
与M行样本作相关计算,在构建数据库时,尚不清楚
实测数据,因此
未知,在此用Z行数据代替
,以备后续
值计算,于是对应的特征参数标准数据库模型如图7所示。
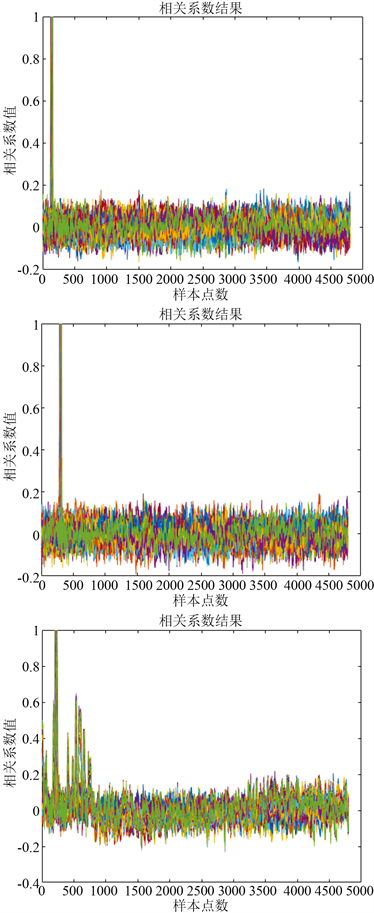
Figure 6. Results of relative coefficient from first three aircrafts
图6. 前3架飞机相关系数结果
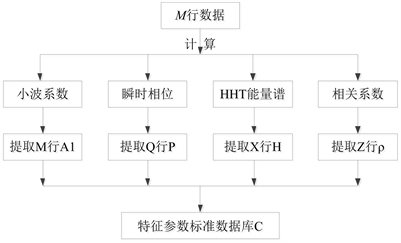
Figure 7. Flow chart of standard feature parameter database
图7. 特征参数标准数据库模型示意图
4.5. 分类规则
4.5.1. 小波系数分类规则
对于采集数据
,小波系数A1与A1对应特征值数据库作相关运算,相关系数最大的飞机标号即为
的标签,实现数据分类。最大值存在三种形式:一是对
小波系数A1与特征参数标准数据库中任意飞机的M行A1系数作相关,所得相关系数的绝对值之和求最大值即为飞机标签;二是
的小波系数A1与数据库中所有飞机的A1系数作相关运算,最大值位置对应的飞机标号即为
的标签;三是
的小波系数A1与数据库中所有飞机的A1系数作相关运算,结果大于阈值Threshold的飞机标签赋值给
,该值可能为多个,可通过其它特征值进一步筛选确定。在此采用第二种,表达式为
(1)
式中
为采集数据
对应的A1系数向量,
表示选取的第i行样本对应的A1系数向量,coef为pearson相关系数函数。由于WA表征的是实测数据与样本数据的相关性,其值越大,相关性越高,被标记为该飞机的概率越高,反之亦然。由于正确识别率存在一定概率,将该概率仍用阈值Threshold表示。表2为Threshold为0.3、M为6时对应分类结果(结果仅粘贴前80行2架飞机识别结果,灰色奇数行为原标签,白色偶数行为识别标签,识别率为27.33%,运行时间283.51 s,未裁决数据用标签4001表示,下同)。
Table 2. Classification results via wavelet coefficient
表2. 小波系数分类结果
4.5.2. 瞬时相位分类规则
同样对于任意采集数据
,瞬时相位P对应的区分规则表示为
(2)
式中
为采集数据
对应的瞬时相位,
表示选取的第i行样本对应的瞬时相位向量,coef为相关系数函数,该值越大,相关性越高,被标记的概率越高,反之亦然。表3为Threshold为0.1、M为6时的分类结果,识别率为21.43%,运行时间359.51 s。
Table 3. Classification results via instant phase
表3. 瞬时相位分类结果
4.5.3. HHT能量谱分类规则
同理对于任意采集数据
,可得定义HHT能量谱的分类规则,即CH满足表达式
(3)
式中
为采集数据
进行EMD分解得到的IMF1、IMF2和IMF3加权后对应的HHT谱,
表示选取的第i行样本对应的EMD分解得到的IMF1、IMF2和IMF3加权后对应的HHT谱,coef为相关系数函数,该值越大,相位相关性越高,被标记为该飞机的概率越高,反之亦然。表4为Threshold为0.1、M为6时对应分类结果,识别率为12.93%,运行时间1686.79 s。
Table 4. Classification results via HHT
表4. HHT分类结果
4.5.4. 相关系数分类规则
同理对于任意采集数据
,可定义相关系数分类规则,即CR满足关系式
(4)
表5为Threshold为0.2、M为6时对应分类结果,识别率为32.18%,运行时间350.64 s。
Table 5. Classification results via relative coefficient
表5. 相关系数分类结果
4.5.5. 分类流程规则
在特征参数标准数据库C和分类规则的基础上,如4.3.1~4.3.4节所示,对采集的任意数据与100架飞机的C作相关性计算,需设计相应的组合规则,即分类流程规则设计问题。为降低数据冗余处理,本节作排他处理,具体规则如下。
对WA、CP、CH、
给定先后分类顺序,而后按序进行分类。对于未知序列
而言,每一步分类过程均需要为下一特征参数分类预留一定数量的采样数据,方可确保分类效果最佳,那么预留数据量如何设计,则面临着阈值设定问题。
假设存在10,000个待分类样本,基于WA规则计算相关系数后,对于第001架飞机相关系数取值(如≥0.5和<0.5两类)对应样本数量分别为4000和6000个,那么4000个样本对应的标签大概率被标的为001,其它6000个样本进入CP的判定,以此类推,直至完成判定。举例而言,假设N个样本
与WA、CP、CH、
作相关运算,结果仍为表5所示。假设WA判定阈值为0.45,即凡是相关系数大于0.4对应的飞机的标签(文中采用4001表示)即为样本
的标签,后续无需重复判定,反之认为数据无法判定,置为未裁决状态,赋予飞机标签之外的数据用于表征未裁决状态,结果如表6所示。
第二次在此基础上,仅对未裁决状态的数据进行分类。例如假设CP阈值为0.7,那么将相关系数大于0.7对应的飞机标签标的为
的标签,后续无需重复判定,以此类推,直至将所有数据标的完成,所得结果即为数据标签,结果如表7所示。
规则中存在四个阈值参数的优选问题,在此暂且通过手工设定选择,后期将通过优化算法作进一步处理。
5. 仿真结果
5.1. 仿真环境
模型仿真环境包括硬件资源、软件资源和模型参数三方面,其中硬件资源提供模型所需的算力、存储、显示等功能,软件资源提供模型运行环境,模型参数提供模型的高效运行,三者设置如表8所示。
Table 8. Simulation environment and parameter value
表8. 仿真环境及参数
5.2. 仿真结果
小波系数计算复杂度为其它变量的一半,且识别率较高,因此将其置于第一顺序,通过改变WA、CP、CH、
参数顺序,得到模型识别率和运行时间如表9所示。表中取值顺序代表特征参数判定顺序(同等条件下带标签识别结果为71.8%,时间为1142 s)。
Table 9. Identification rate and running time for different parameters of the model
表9. 不同参数时模型识别率及运行时间
结果表明,第一行识别率最高,且已经接近带标签识别结果。但平均识别率依然偏低,导致该模型识别率相对较低的原因包括两方面:一是硬件资源受限,训练样本选择较少,特征向量不够精确,作相关运算时产生一定的误差;二是存在隐藏的特征参数尚未挖掘,使得该特征值识别的数据无法凸显。前者可引入高性能工作站,增加样本训练数量来解决,后者可通过主成分分析法、独立分量分析、最小二乘法等特征提取方法继续挖掘数据样本的特征参数来实现。
在此误差条件下,选择识别率最高的第一行用于标的测试数据标签,所得结果如表10所示(仅粘贴前100行),数据从1~100递增显示。
Table 10. Label assignment result for test data samples
表10. 测试数据样本标签赋值结果
6. 结论
论文针对100架民航飞机数据识别的现实问题,设计了包含数据分析/处理、特征参数标准数据库建立、分类、优化等模块的多特征值相关系数联合射频指纹识别模型。结果表明,在硬件资源受限、选择样本数偏低的情况下,该模型平均识别率为69.75%,为解决飞机数据识别的现实问题提供了一定的理论参考。但由于硬件资源受限,选择了少量样本数据用于训练,无法避免异常数据的干扰,且引入识别误差。该问题可在高性能工作站中选择更多的训练数据构建特征向量,将很大程度上提高平均识别率。同时优化过程由手工设定参数取值,并未利用遗传算法等生物学习算法,或文化算法等社会学习算法搜索最优解,因此识别率并非最优,仍有一定的改进空间。后期将针对上述问题展开研究。
基金项目
重大专项(XX2020F00003-XXX)、省部级课题(20191A010001)、大学基础理论课题(2021043、202121)。
NOTES
*通讯作者。