1. 引言
汽油是小型客货车的主要燃料,而汽油燃烧过程中不可避免产生的尾气,则对大气环境有着重要的影响,是雾霾的主要来源之一。
S-Zorb具有辛烷值(RON)损失少,抗爆指数损失小,液体收率高,脱硫率高,设备投资低,不消耗氧气,吸附剂价格低以及最终产品含硫量低的特点,能够生产出满足国VI以及其他国家高标准的汽油,成为目前工业化应用中最为广泛的清洁汽油生产工艺 [1]。
辛烷值(RON)是衡量和反映汽油燃烧性能的最重要的指标,主要用来衡量汽油在汽缸燃烧时的抗爆震燃烧能力。当辛烷值略不达标时,虽然此时的发动机能正常运动,但是由于燃料释放的能量不足,使得发动机的工作低于正常的压缩比,从而造成汽车怠速不稳定,以及燃油的浪费。因此,我们可以知道,辛烷值的多少直接决定了燃料的利用效率,从而对汽车的能量利用产生重大影响。辛烷值的多少直接作为汽油的商品牌号。
综上所述,如果在对汽油进行催化裂化脱硫处理时,尽可能地保留汽油的辛烷值,将会对我国石油化工行业,交通运输行业产生巨大的经济效益。
2. 我们的方法
化工过程的模型建立方法,总的来说可以划分为两大类:第一类是通过数据关联或机理建模的方法建立集总的动力学模型 [2],第二类则是采用数据驱动的方式来进行建模 [3]。由于炼油工艺复杂、设备多样,且操作变量存在复杂的线性或非线性关系,采用传统的基于机理和关联的建模方法,具有较大的局限。因此本文基于数据挖掘的方法,采用多种关联算法(随机森林、PCA分析,多元线性回归、互信息法、皮尔逊特征)处理操作变量,挖掘变量之间的相互关系,对比选择影响最大的操作变量;接着使用多种机器学习算法(多元线性回归,随机森林,XGBoost)对数据进行学习和优化,从而得到操作变量的最优解。本文将分五个步骤建模。
3. 数据预处理
3.1. 分析
本步骤属于数据挖掘过程中的数据预处理部分,又称为数据清洗。由于数据获取,存储,转移,读取的过程中,不可避免地存在各种噪声干扰,使得数据一般情况下不会是完美的,可以直接利用的。数据预处理和数据清洗的目的就在于解决数据的各种问题。通过检测数据判断数据是否存在缺失,是否存在错误,是否存在重复,数据单位格式是否符合要求,数据是否没有歧义。
3.2. 我们的方法
在给定数据集之中,大部分的变量数据正常,部分的数据存在空值和丢失。对于残缺值较多的列,采用直接删除的方法处理,对于仅有部分残缺值的列,本次工作中采用的是平均值填补。
对于奇异值的判断,采用两种方法处理。第一种为上下限过滤法,第二种为拉依达准则判定法。
拉依达准则 [4] 首先假定需要判断的样本数据符合正态或近似正态分布,且测量的次数应该是充分多的。同时假定该检测数据只存在随机误差,通过计算改组数据的标准差,按一定的概率确定一个区间,认为超过这个区间的误差,就不属于随机误差而是奇异值,应该予以删除。为了保证其中标准差的计算采用贝塞尔公式。贝塞尔公式如下:
4. 数据挖掘
4.1. 分析
步骤二就是在步骤一的基础上,对集进行挖掘,找出数据之间潜在的线性和非线性的关系。目前的数据集中,存在7个原料性质、2个待生吸附性质、2个再生吸附性质、2个产品性质等变量以及354个操作变量。我们需要从这个367个变量中利用机器学习方法,寻找影响辛烷值降低的最主要的因素。这样做有利于忽略次要因素,发现这367个变量中其主要作用的变量。通过步骤二,可以在保证模型精确度的情况下大幅度减少计算规模,减少计算时间。尤其是对于拥有海量数据的建模和优化问题,能够节省计算时间,减少无关项干扰,使得模型不高度依赖于海量计算资源,更具现实意义。
4.2. 我们的方法
降维是数据挖掘中常用的数据处理方法,目的是在尽量保证模型准确性的情况下降低数据的维度,从而大幅度减少计算资源,提高模型计算时间。本文采用互信息法、随机森林、多元线性回归。
4.2.1. 互信息法
在概率论和信息论中,我们可以通过两个随机变量之间的相互信息(Mutual Information)和转移信息(Trans-information)来度量两者之间的相互关系 [5]。互信息法可以检测到每个特征与标签之间的任意关系,包括线性和非线性的关系。互信息法可以用做回归模型的相关性检验,也可以用于分类模型的相关性检验。并且检测结果的返回值是0~1之间的数值,越接近1,表示相关性越大。
4.2.2. Pearson (皮尔森)系数
皮尔森系数也称为积差相关,是英国统计学家皮尔逊提出的计算两个数据之间直线相关性的方法,是余弦相似度在纬度值缺失情况下的一种改进。
4.2.3. 随机森林寻找特征
随机森林又称随机决策森林,是一种集成学习方法,可以用作分类、回归和其他的任务。随机森林的方法同样可以用来做特征选择。它的基本思想是,假设某个特征时重要的,那么如果在这个特征中引入额外的噪声,重新进行随机森林训练,那么此时的模型性能会有巨大的变化(明显的变差),反之,如果这个特征并不重要,则引噪声之后对模型的影响不大。算法过程如下:
Step1:针对每一颗决策树,选择相应的bag外数据,计算相应的误差;
Step2:随机对bag外数据所有样本的特征加入噪声干扰,并重新计算相应的误差;
Step3:用下式计算特征x的重要性:
Step4:将所有重要性排序,寻找最重要一些特征。
4.3. 特征选择
每组数据训练时,均使用K-Fold交叉验证方法,将数据集随机划分为训练集和测试集,其中训练集数据量占总数据量的70%,测试集数据量占总数据量的30%。在随机森林产生的特征中充分训练了12个模型,后面两组产生的特征只充分训练了前10个模型。
本文的工作用上述特征选择方法对数据进行分析,使用了随机森林、多元线性回归和互信息法的特征选择结构。最终随机森林效果最好,我们采用随机森林来特征选择。
随机森林模型特征选择结果
如图1展示采用随机森林模型选择出的重要特征。
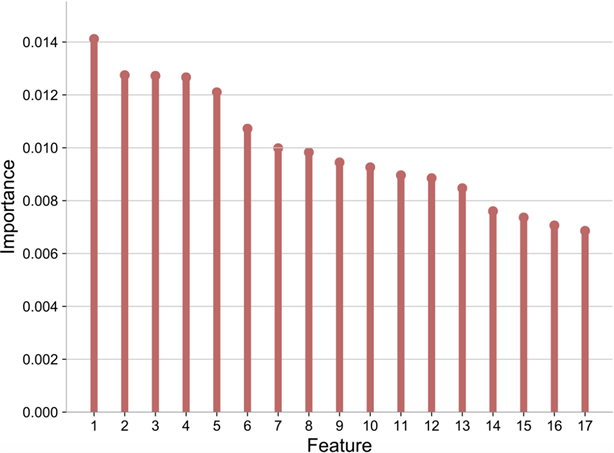
Figure 1. Model importance of random forest selection
图1. 随机森林选择的模型重要程度
如图1所示,其中1~17分别代表17种特征:1——对流室出口温度,2——R-101顶反应产物出口管温度,3——E-101壳程入口总管温度,4——反应器上部温度,5——预热器出口空气温度,6——净化风进装置压力,7——蒸汽进装置流量,8——ME-109过滤器差压,9——S_ZORB AT-0008,10——再生吸附焦炭,11——非净化风进装置压力,12——S_ZORB AT-0007,13——R-101床层下部温度,14——代生吸附剂S,15——产品溴值,16——非净化风进装置流量,17——产品辛烷值RON。
5. 建立和优化预测模型
5.1. 分析
步骤三对应的数据挖掘中的预测模型的建立和优化过程。我们建立不同的算法模型,并用步骤二的不同的特征数据集进行交叉组合训练,并对结果进行对比。
我们建立的机器学习回归预测模型包括:线性回归、决策树回归、支持向量机、k近邻、随机森林回归、AdaBoost回归、梯度提升回归(GBDT)、bagging回归、极限树(Extra Tree)回归、LightGBM回归、MLP、XGBoost。
5.2. 模型建立对比
5.2.1. 交叉验证
在实际的训练中,在训练集上得到很好的预测结果,但在实际的测试集上却效果很差,这一现象被称为过拟合。为了解决这一问题,我们引入统计学中的交叉验证方法。交叉验证的思想是通过某种方法,将原始数据集进行分组,一部分作为训练集,一部分作为测试集。测试集是与训练集完全独立的数据,测试集不参与训练,只用于最终模型的评估。
在每一个具体的模型算法实现中,均采用K-Fold交叉验证方法,消除过拟合,优化模型性能。该方法将原始数据分为K组,称为K-Fold。每个子集数据分别做一次验证集,其余的k-1组作为训练组,分别进行训练和验证。产生的K个模型和模型误差,做均方误差(MSE)的加和平均,其结果作为评价模型表现的指标。交叉验证有效的利用了有限的数据集,使最终模型做出的预测更能贴近真实值。
均方误差MSE是通用的用来检测模型的预测值和真实值之间的偏差。
训练集定义为:
测试集定义为:
训练模型为:
预测值为:
则均方误差MSE的计算公式为:
均方根误差RMSE定义为:
K-Fold交叉验证评估公式为:
5.2.2. 线性回归
此处使用的线性回归模型是多元线性回归,即多个自变量共同作用下影响标签值,在前文的特征选择中,已经使用过该模型。模型训练使用梯度下降法,并通过使用K-Fold交叉验证防止模型过拟合。
5.2.3. 决策树回归
决策树是一种非参数的有监督学习方法,它能够从一系列有标签的特征中挖掘出决策规则,并用二叉树的结构来表示这些规则,从而解决分类和回归的问题。决策树一般用于分类问题的求解,而决策树中的CART方法,既可以做回归树也可以做分类树。CART方法是在ID3的基础上进行优化的决策树,当它采用GINI值作为节点分裂的依据时,是分类树;当它采用样本的最小方差MSE作为节点分裂时变成了回归树,做回归树时,也可以使用费尔德曼均方误差或者绝对平均误差MAE来作为判断节点。
5.2.4. 随机森林回归
随机森林是一种建立在决策树之上的集成学习算法。集成学习本身并不是一个独立的机器学习算法,而是通过在数据上构建多个算法,根据这些算法的共同结果来估算模型的整个结果。多个模型集成而产生的模型被称为做集成评估器,组成集成评估器的每个模型都称为基评估器。常用的集成方法有三种:bagging,boosting和stacking。Bagging法又被称为装袋法,其核心思想是构建多个相互独立的评估器,然后对其独立的预测结果进行平均取值或者按照多数表决的原则来处理。随机森林是典型的袋装法。随机森林是决策树构成的集成方法,决策树可以用来处理回归问题,随机森林也可以用来处理回归问题。
随机森林使用bootstrap采样从输入训练数据集中采集多个不同的子训练数据集来依次训练多个不同决策树;在预测阶段,随机森林将内部多个决策树的预测结果取平均得到最终的结果。随机森林回归需要使用的分差节点计算公式如下:
5.2.5. Boost类方法
本节介绍的则是另一种类型的集成学习方法:boost方法族,包括XGBoost,AdaBoost,GBDT,LightGBM等方法。与随机森林的bagging方法不同,boost方法中基评估器是相关的,是按照顺序一一构建二次。该族算法的工作机制为,先从初始训练集中训练出一个基学习器,再根据这个基学习器的表现对样本分布进行相应的调整,直到基学习器的表现达到要求。然后构建下一个基学习器,直到最终构成整个的强评估器。
5.3. 我们的方法
本部分的工作是利用上面介绍的机器学习方法,利用步骤二筛选出来的特征变量建立辛烷值(RON)损失预测模型。由于不同的特征选择方法在对特征的重要性进行计算时有不同的侧重点,所以算法选择出来的特征并不相同。考虑到不同的机器学习算法针对不同的数据值,有不同的性能差异。我们选取了12种机器学习算法进行建模,每种均进行K-Fold交叉验证,最后对比选择出最优的模型。12类方法分别为:线性回归模型、决策树回归模型、支持向量机回归模型、K近邻模型、随机森林模型、自适应提升树模型、梯度提升树模型、bagging模型、极限树模型、LightGBM模型、多层感知器模型、XGBoost模型 [6]。
拟合结果通过MAPE (平均绝对百分比误差)和RMSE (均方差根误差)进行衡量。这两个指标是应用最广泛的误差判断指标。两者的计算公式分别如下:
均方根误差(RMSE, Root Mean Square Error),本质上就是对均方误差MSE做了取根号的运算。该误差取值范围为
,当预测值与真实值完全吻合时,该值等于0,误差越大,该值越大。
平均绝对百分比误差(Mean Absolute Percentage Error),取值范围
,为0时表示与真实值之间没有偏差。
5.3.1. 随机森林特征集
本节将随机森林方法选取的特征作为特征集,放到12种机器学习模型之中进行计算,并通过K-Fold交叉验证方法避免过拟合,提高模型准确率。计算结果汇总成图2:
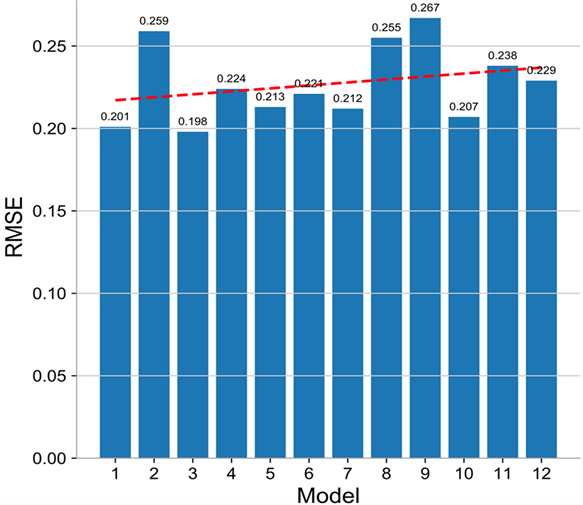
Figure 2. Root error of mean square deviation of each model based on random forest characteristics
图2. 基于随机森林特征的各模型均方差根误差
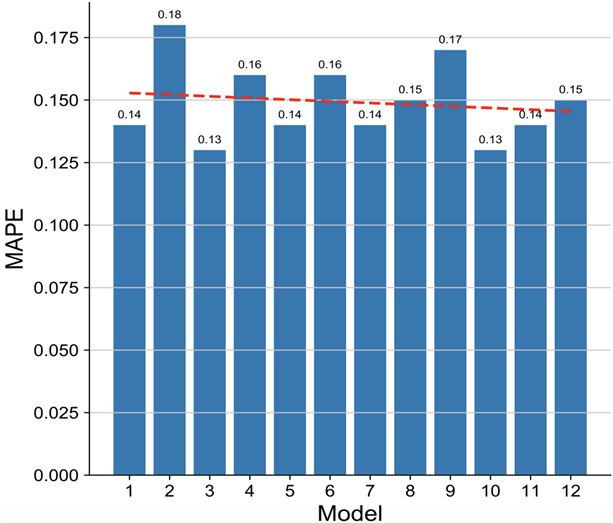
Figure 3. Average absolute percentage error of each model based on random forest characteristics
图3. 基于随机森林特征的各模型平均绝对百分比误差
如图2和图3所示,其中1~12分别表示为12种模型:线性回归模型,决策树回归模型,支持向量机模型,K邻近模型,随机森林模型,自适应提升树模型,梯度提升树模型,bagging模型,极限树模型,LightGBM模型,多层感知器模型,XGBoost模型。
根据图2和图3汇总的计算结果,可以知道当特征集为随机森林选择的特征时,预测效果最好的为支持向量机模型。
5.3.2. 模型确认
通过上述实验可以发现,针对辛烷值(RON)损失预测的问题。综合考虑模型精确度,求解速度,所使用的特征变量数量,所选择的最好的机器学习模型是支持向量机回归,最好的特征选择方法是随机森林。通过随机森林选择影响辛烷值的特征,通过支持向量机回归预测辛烷值损耗,在十二种机器学习算法中效果最好,所用特征变量数最少。
6. 优化
6.1. 分析
步骤四要求进行主要变量操作方案的优化,而优化的前提是保证产品硫含量不大于5 μg/g,所以首先通过所给附件选择出了需要的数据样本,然后在所选的样本中,利用我们的预测模型,将RON损失值降幅达到30%以上。
对于目标值的优化方法有很多,包括贪婪算法、模拟退火算法、粒子群算法、遗传算法等等,我们使用粒子群优化算法找出了主要变量优化后的操作条件 [7]。
6.2. 粒子群的算法介绍
在我们上文中构建的模型中,属于复杂优化问题。因为各个变量之间存在着非线性关系,强耦合联系,优化起来相当复杂。这些复杂优化问题涉及的决策变量不断增加,问题规模不断增大 [8]。对于这种问题,传统的优化问题往往很难得到有效的求解。
粒子群优化算法(PSO:Particle swarm optimization)是一种进化计算技术,是通过群体中个体之间的协作和信息共享来寻找最优解。
粒子群算法的基本公式
PSO初始化为一群随机粒子(随机解)。然后通过迭代找到最优解。在每一次的迭代中,粒子通过跟踪两个“极值”来更新自己的速度和位置。在找到这两个最优值后,粒子通过下面的公式来更新自己的速度和位置。
公式(1):
。
公式(2):
。
在公式(1)、(2)中,
,N是此群中粒子的总数。
:是粒子的速度。
:介于(0,1)之间的随机数。
:粒子的当前位置。
和
:是学习因子,通常
。
的最大值
(大于0),如果
大于
,则
。
公式(1)、(2)为PSO的标准形式。公式(1)的第一部分称为“记忆项”,表示上次速度和方向的影响;公式(1)的第二部分称为“自认知项”,是从当前点指向粒子自身最好点的一个矢量,表示粒子的动作来源于自己经验的部分;公式(1)的第三部分称为“群体认知项”,是一个从当前点指向种群最好点的矢量,反映了粒子间的协同合作和知识共享。粒子就是通过自己的经验和同伴中最好的经验来决定下一步的运动。以上面两个公式为基础,形成了PSO的标准形式。
公式(3):
。
:叫做惯性因子,其值为非负。
其值较大,全局寻优能力强,局部寻优能力弱;其值较小,全局寻优能力弱,局部寻优能力强。
动态
能获得比固定值更好的寻优结果。可在PSO搜索过程中线性变化,也可以根据PSO性能的某个测度函数动态改变。公式(2)和公式(3)被视为标准PSO算法。
6.3. 主要变量的优化操作分析
1) 对流室出口温度
对流室出口温度的优化操作,根据PSO算法求解得出的实验结果,对流室出口温度的优化范围于390~400之间,其对RON损失值的降幅达到最优效果。
2) R-101顶反应产物出口管温度
根据算法得出的最优化操作,需要将R-101顶反应产物出口管温度优化范围为400~405之间,其对RON损失值的降幅达到最优效果。
最终,通过我们的优化操作方案,将RON损失值降幅为33%以上,取得了显著的提升效果。
7. 实验结果显示
7.1. 汽油辛烷值的变化轨迹分析
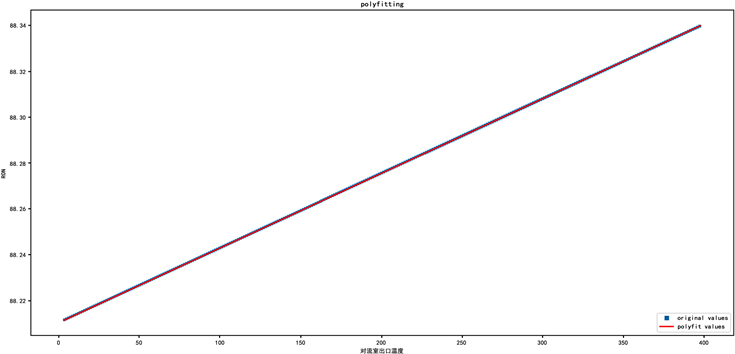
Figure 4. Influence trend of outlet temperature adjustment of convection chamber on octane
图4. 对流室出口温度的调整对于汽油辛烷值的影响趋势
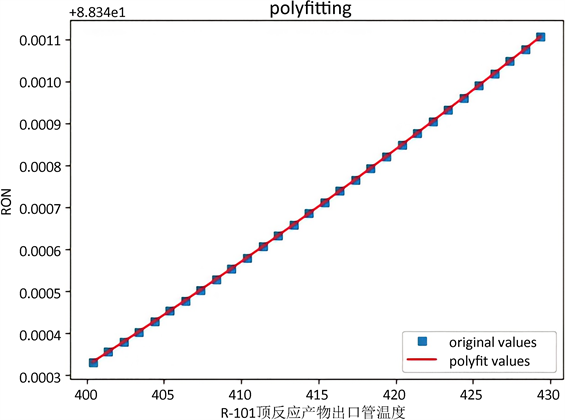
Figure 5. Effect trend of R-101 top reaction product outlet pipe temperature adjustment on octane number of gasoline
图5. R-101顶反应产物出口管温度的调整对于汽油辛烷值的影响趋势
如图4和图5所示,我们优化后的算法可以很好地拟合流室出口温度以及顶反应产物出口管温度对于汽油辛烷值的影响趋势。
7.2. 硫含量的变化轨迹分析
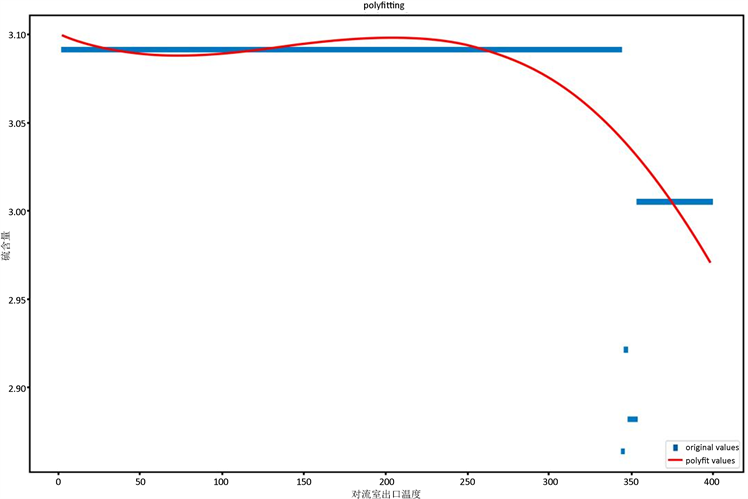
Figure 6. Influence trend of outlet temperature adjustment of convection chamber on sulfur content
图6. 对流室出口温度的调整对于硫含量的影响趋势
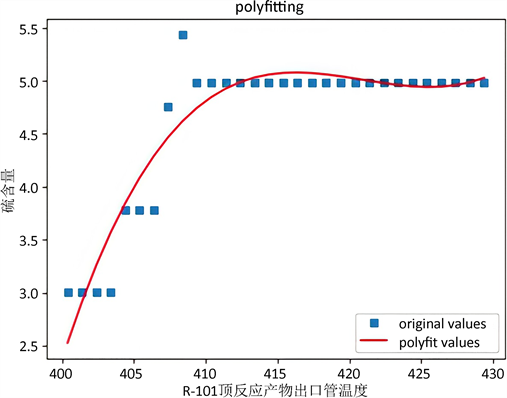
Figure 7. Influence trend of temperature adjustment of R-101 top reaction product outlet pipe on sulfur content
图7. R-101顶反应产物出口管温度的调整对于硫含量的影响趋势
如图6和如图7所示,我们的预测模型较为很好地拟合了流室出口温度和R-101顶反应产物出口管温度对于硫含量的影响趋势。
8. 总结
我们采用了三种特征选择算法进行特征抽取,然后分别对比了12种机器学习算法训练的模型结果,最后得出预测效果最好的为支持向量机模型,最好的特征选择是随机森林方法,然后我们再将建立的模型用粒子群算法优化,给出每个样本的优化操作条件,在保证汽油脱硫效果的情况下,降低汽油辛烷值的损失,成功将辛烷值损失比原工艺减少33%。
参考文献