1. 引言
Tobit回归模型 [1] 是一种因变量受限模型,被称作样本选择模型,或者删失回归模型。Tobit回归模型被广泛应用于计量经济学等众多研究领域 [2] [3] [4],在面板数据和时间序列数据的分析中发挥着越来越重要的作用。假设
,我们可以如下定义Tobit回归模型
(1)
其中,
(
维向量)是回归系数,
是
维协变量,
是随机误差。然而,在计量经济学等领域对面板数据或者时间序列数据等分析研究中,常常会遇到数据集通常有大量的解释变量,但其中只有少数对模型有贡献。也就是说,在一个
维的回归系数中只有
(
且
未知)个分量是取非零值的,我们称之为有效变量 [5]。目前有很多方法可以用来识别有效变量,如LASSO [6] 和LARS [7] 等等。但另外需要关注的问题是,用多少样本才能既识别出有效变量,同时又能使参数估计达到预定的精度。这对于计量经济学等领域需要考虑抽样成本的研究具有重要的意义。对于线性回归模型,Wang 和Zhang (2013) [5] 提出了一种序贯压缩估计方法来识别有效变量,从而达到参数估计的精度。数值模拟结果表明,与传统的序贯抽样方法相比,序贯压缩估计不仅可以从所有变量中识别出有效变量,而且可以节省大量样本。对于Tobit回归模型,如何提出相应的序贯估计方法以及在自适应设计下给出相关性质和数据模拟有待进一步的研究。本文针对Tobit回归模型提出了一种基于自适应压缩估计(ASE)来构造有效变量的固定窗宽的置信集的序贯抽样方法,使有效变量能以最小样本量快速识别。本文将在适应性设计(adaptive design)下研究所提出的自适应压缩估计(ASE)的大样本性质,同时在自适应性设计下通过数值模拟得到了很好的模拟结果。
2. 基于Tobit模型的序贯自适应压缩估计(ASE)
2.1. 最小一乘估计(LAD)
不失一般性在模型(1)中,令
。假设随机误差
独立同分布且
,那么似然函数的形式为:
其中
和
分别为标准正态分布的概率分布函数和密度函数,
为集合
中若干元素的乘积,
为集合
中若干元素的乘积。记
使
达到最小的
被称为回归参数
的最小一乘估计 [8],记为
。我们给定假设条件:
(A1)
;
(A2) 若随机误差
的密度函数
满足
和
,那么存在
使得
。
当
满足(A1)和(A2)时,文献 [9] 给出了
的相合性和渐近正态性:
其中
是单位阵,并且
。
2.2. 自适应压缩估计(ASE)
设
,当
时,存在
和
使得
,
。下面我们给出Tobit回归模型下回归系数的自适应压缩估计的定义:
定义2.2.1 设
为模型(1)的最小一乘估计,则称
为回归系数
的自适应压缩估计(ASE),其中
是一个
维对角阵。同时可以证明
满足相合性和渐进正态性。
2.3. 序贯抽样策略
依据文献 [10] [11] 中的结论我们可以证明
是依概率一致连续的,由此可得如下定理:
定理2.3.1 设随机变量N(t)取正整数值,当
有
依概率收敛于1,且条件(A1)和(A2)成立,则当
时,
由定理2.3.1我们可以构造
的置信集和能够决定最小样本量的停止法则的序贯抽样策略。设
是最先进入研究的
个样本,用
来表示。在任意给定小正数
下,
是回归系数
基于条件
的估计量。令
对任意
,有
成立。现在定义停时法则
为
, (2)
其中
是
的最大特征值,
是置信集的预设精度。在本文的序贯估计策略中,一次只有一个新的观测进入研究直到满足(2)式的停止法则时就停止抽样,此时
的置信集为
(3)
其中
。我们所提出的序贯抽样方法致力于找到有效变量的同时忽略无效变量的影响,这是和传统序贯方法相比我们能够节省大量样本的关键,在下面的定理中我们给出停时
和置信集
的相关性质。
定理2.3.2 假定条件(A1)和(A2)都成立,设N是满足(2)式的停时,则:
i)
,a.s.;ii)
;
iii)
;iv)
,a.s.且
,
其中
是矩阵
的最大特征值。
3. 数值模拟
在固定样本量下用所提方法对随机数据集合进行分析,以此来验证所提出的序贯压缩估计方法的性能。按照停止法则的定义,当抽样停止时,最终的置信集将满足预设精度和覆盖概率,因此我们可以比较分别基于LAD和ASE的序贯抽样方法的平均停时。由于序贯压缩估计方法忽略无效变量的影响,故理论上平均所需停时应该显著小于不考虑变量选择的序贯方法。如果事先已知有效变量为
个同时无无效变量,那么只使用这
个有效变量的序贯方法无疑是效率最高的。所以,为便于比较,我们将所有(
个)变量全部为有效变量的序贯估计方法作为基准线,在此情况下所获得的样本量应该是最小的。在自适应设计下,随机模拟数据集中的
仍然由多元标准正态分布生成,
由均值为
,方差协方差矩阵为单位阵的多元正态分布生成。不失一般性,选择模型(1)中的常数
。回归系数真值取
,其中含有八个无效变量,回归系数置信集的预设精度
,取
,
,
,
。另外当用ASE方法时我们用BIC方法来确定
。
表1描述了Tobit回归模型下的序贯抽样方法的数值模拟结果。在表1中我们列出了最终样本量N (停
时),
和95%置信集的经验覆盖概率
。所有三种情况(
, ASE, LAD)下的
值都非
常接近1,并且当d不断减小时经验覆盖概率CP越来越接近95%,正如定理2.3.2描述的一样。然而,应用LAD方法所得的样本量N比应用ASE方法和
都大得多。而应用ASE的抽样策略所需的样本量和应用
的抽样策略所需样本量差不多,这说明我们所提方法在变量选择的同时效率和回归参数中只有有效变量无无效变量的情况下的效率非常接近,而比不做变量选择情况下(即LAD)的抽样效率提高很多。
表2比较了在估计Tobit回归模型的回归系数时分别应用ASE和LAD的抽样策略对识别回归系数中的有效变量和无效变量的效率。从结果可以看出应用ASE的抽样策略时不能被正确识别的零变量的平均个数几乎趋向于0,而能被正确识别的非0变量的平均个数和模型中有效变量个数的真值非常接近(2和8)。结果表明基于ASE的序贯抽样策略下
是
的优良估计。而基LAD的序贯抽样策略不能识别有效变量,因此无法获得
和
的值。此外,所有参数的估计值和它们的真值都非常接近。

Table 1. Results of sequential sampling method based on ASE, LAD with all variables and LAD with only p 0 non-zero variables for Tobit regression model
表1. Tobit回归模型下分别应用ASE,LAD和
的序贯抽样方法的结果分析
 ;
;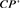 是95%置信集
是95%置信集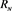 的经验覆盖概率;**经验标准差在括号内。
的经验覆盖概率;**经验标准差在括号内。
Table 2. Power of variable identification and estimation of nonzero components under sequential sampling method based on ASE and LAD with Tobit regression model
表2. Tobit回归模型下分别应用ASE和LAD的序贯抽样策略的变量识别和非零参数估计效率
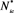 :
: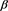 中零分量(无效变量)被错误识别的平均个数;
中零分量(无效变量)被错误识别的平均个数;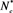 :
: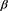 中非零分量(有效变量)被正确识别的平均个数。
中非零分量(有效变量)被正确识别的平均个数。
4. 结论
在Tobit回归模型下基于自适应压缩估计(ASE)建立的序贯抽样方法不仅能够用最少的样本识别出回归参数中的有效变量,同时可以使回归参数的估计值达到预设的精度 [12]。我们在自适应设计下对相关性质做数值模拟,结果表明和传统的序贯抽样方法相比,我们提出的方法能够节省大量样本。然而,本文中所提方法涉及到的变量维数是固定的,后期我们将研究当变量维数随样本量变化时的序贯抽样方法的相关性质。
基金项目
1) 新疆师范大学博士科研启动基金项目:“基于广义线性模型的序贯分析研究”XJNUBS1539;
2) 新疆维吾尔自治区高校科研计划项目:“基于Cox比例风险回归模型的序贯分析研究”(XJEDU2016I033)。