1. 引言
自从改革开放政策实施以来,我国社会经济呈现出高速增长的态势,国民收入水平显著上升,旅游日益成为人们现代化进行休闲、娱乐活动的主要途径之一。目前,我国的国内旅游业是发展潜力最大的旅游市场,在经济的发展中具有重要的地位 [1]。所以,对旅游人数进行较为准确的预测分析,为当地旅游业相关部门制定发展战略决策和其他相关政策措施提供一定的理论基础和技术支撑,从而有效地推动旅游行业的健康发展。主要的预测方法有两大类:定性分析与定量分析。其中,定性分析主要是根据人的主观判断和已有经验进行大致趋势和范围的分析;定量分析通过建立统计数学模型得到具体的一个数值。如:Seetanah等人通过VAR模型研究相对平均费用、旅游基础设施、旅游行业发展水平等相关因素对旅游市场具有长期影响 [2]。Pai等人提出了一种新型预测旅游人数模型,建立模糊聚类和支持向量回归的组合模型,该方法得到的预测精度优于传统的方法 [3]。E. Hadavandi等人首次把遗传模糊系统方法应用到旅游需求预测的问题中 [4]。Fong-Lin Chu建立基于分段线性的方法对澳门旅游需求预测 [5]。陈萍萍根据游客量、客运量和旅游航班数的数据,建立了三种模型,分别是指数平滑模型、季节ARMA模型和Elman模型,得到Elman模型预测效果最好,并且三种模型的组合预测效果最优 [6]。廖治学等人通过建立以GMDH非线性叠加对季节性ARMA模型和神经网络模型的组合模型来进行预测,组合模型的预测精度最优 [7]。
本文首先将灰色理论和神经网络模型进行结合,建立灰色神经网络模型,为得到最优的初始参数,采用遗传算法对模型进行优化。由于模型预测误差较大,为提高模型预测精度,对影响因素进行变量筛选,将影响程度大的因素留下,删除掉影响程度小的因素。为了增强模型的对比性,用两种方法对变量进行筛选,即分别建立基于灰色关联度和平均值影响法两种方法的变量筛选模型,对旅游人数进行预测。
2. 算法介绍
2.1. 灰色神经网络模型
灰色理论可以解决样本少、信息少和不确定性的问题,其通过在已有的信息的基础上充分提取有用的信息后对未知的信息进行合理推测。灰色神经网络将样本数据经过一次累加处理后转化成微分方程的形式,利用已知的相关信息,对微分方程的系数进行求解,从而得到微分方程的表达式。首先将原始数据
进行一次累加处理后得到
,然后建立微分方程如下:
其中,
为输入数据,
为输出数据,
为方程系数。
求解微分方程,可得预测结果为
:
令
将m代入上述
中,最终可以化简得到:
将
映射到BP神经网络模型中就可以得到了一个网络结构为n个输入数据和1个输出数据的灰色神经网络模型 [8]。
2.2. 遗传算法
遗传算法(Genetic Algorithm)是通过模拟自然界中自然选择和遗传机制中的选择、交叉、变异的现象,得到具有适应能力的个体,使得种群不断进化,最终得到适应能力最优的个体,同时也就得到了对应问题的最佳解。遗传算法以个体适应度函数为标准,通过模拟自然选择和遗传原则来寻求最佳参数 [8]。其中,基本的操作步骤如下:
选择:根据个体适应度值的大小,按照一定的概率在当前种群中选择基因优良的个体到下一代中。
交叉:从种群中任意选择两个染色体,以一定概率选择一处或多处的位置交换两者的染色体,从而得到新的优良个体。
变异:从群体中任意选择一个染色体,以一定的概率随机改变该染色体上某一处的值,从而产生新个体。
2.3. 变量筛选
灰色关联度法通过计算影响因素的关联度来评价因素的相关程度。关联度绝对值越大表明因素之间的关联性越强 [9]。具体步骤为:首先将原始数据进行预处理,消除单位量纲化的影响;选择参考序列
,t表示时刻,n个比较序列
,
,比较序列对参考序列的关联系数为:
其中
为分辨系数,
和
分别为两级最小差和两级最大差。关联度为:
平均影响值法(MIV)可以用来评价输入变量对输出变量的影响程度,其正负号代表相关性的方向,绝对值大小代表影响程度大小。该方法可以用于筛选变量,留取影响程度大的变量,剔除影响程度小的变量。具体计算步骤为:首先使用原始数据训练神经网络,使网络达到稳定;将原始数据的每一个输入变量分别加减10%,得到新样本P1,P2;分别将P1和P2代入到已训练好的模型中,得到输出结果Q1和Q2,计算Q1和Q2的差值即可得到输入变量对输出变量的影响变化值,最后将该值按照样本个数进行平均得到MIV值 [8]。
3. 实证分析
3.1. 数据来源与预处理
通过阅读文献和查阅相关资料,从《中国统计年鉴》和《中国旅游统计年鉴》中得到原始数据,首先对原始数据进行简单处理,初步得到13个影响因素:X1:总里程;X2:居民消费价格指数;X3:国内旅游收入;X4:城镇居民可支配收入;X5:旅行社个数;X6:城镇居民旅游人均花费;X7:城镇居民消费水平;X8:人均国内生产总值;X9:星级饭店个数;X10:城镇居民人口数;X11:客运量;X12:国内生产总值;X13:第三产业生产总值;被解释变量Y:国内旅游人数。
数据预处理:首先将数据分为训练集和测试集,具体如:选取1994~2019年的相关数据进行模拟,其中,将1994~2016年数据作为训练数据,2017~2019年数据作为测试数据。其次,为了消除单位量纲化的影响,将训练数据和测试数据分别进行归一化处理 [10],消除奇异数据,采用mapminmax函数对数据进行归一化处理,并运用matlab进行计算。mapminmax具体计算公式:
其中,
为数列的最小值,
为数列的最大值。
3.2. 模型预测
3.2.1. 遗传算法优化灰色神经网络模型预测(GA-GM神经网络模型)
遗传算法具有随机性、全局性和鲁棒性强的特点,故用遗传算法优化灰色神经网络模型的初始参数,得到全局最优解 [11]。首先将归一化训练数据进行一次累加处理,将其作为模型的输入变量,网络结构为1-1-14-1。经过训练,根据迭代次数和训练误差,最终确定网络的传递函数为purelin,训练函数为traincgf。经matlab运算可得,模型均方误差为9.1526,由图1可得,训练集的可决系数为0.99965,测试集可决系数为0.99844,整体的可绝系数为0.99963,说明模型的拟合效果好。预测结果如表1,可看出相对误差较高,只有一个低于5%,且绝对误差均大于2。
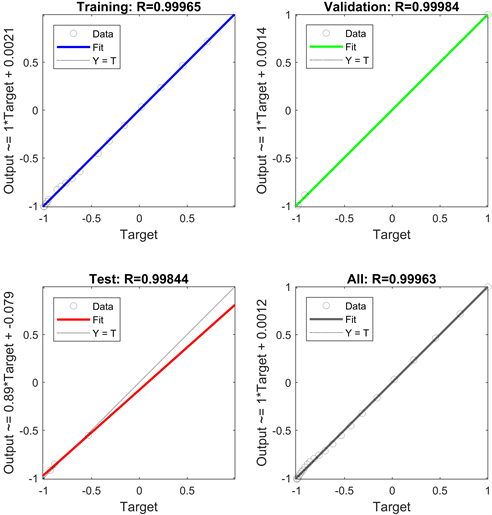
Figure 1. Regression analysis of GA-GM neural network
图1. GA-GM神经网络模型结果回归分析

Table 1. Prediction result and error of GA-GM neural network
表1. GA-GM神经网络模型预测结果及误差
由于上述的模型输入变量有13个,变量较多,为了进一步提高模型预测精度,可对变量进行筛选,将影响效果显著的变量选入模型,效果不显著的变量删除。
3.2.2. 灰色关联度法变量筛选后的GA-GM神经网络模型
首先对旅游人数影响因素进行灰色关联度计算。其中,旅游人数作为参考数列,13个影响因素作为比较序列,计算指标的关联系数,由matlab程序进行计算,在求解关联系数中,借鉴前人已有经验将分辨系数设为0.5,可得到影响旅游人数因素的关联度如表2。注:表2中的灰色关联度为关联系数的绝对值。
Table 2. Grey correlation degree of influencing factors
表2. 影响因素的灰色关联度值
通过上述结果可以得到,这13个影响因素中,由于X3和X12的灰色关联度小于0.75,故去除变量X3和X12,选取剩余的11个变量作为最终的输入变量,此时网络结构为1-1-12-1。由matlab运算可得,模型的均方误差为4.9571,由回归图2可得,测试集可决系数为0.99999,模型的拟合效果好,可解释性高。预测结果如表3,模型的相对误差均在5%以内,其预测精度显然高于未经过变量筛选的GA-GM神经网络模型。
3.2.3. 平均值影响法变量筛选后的GA-GM神经网络模型
平均值影响法(MIV)是神经网络中评价变量相关的最好指标之一,正负号代表相关性的方向,绝对值的大小代表指标的重要程度 [12]。用matlab编程分别对样本数据的13个变量求MIV值如表4。注:表4中的MIV值为其绝对值。
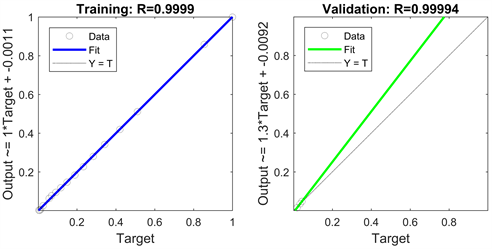
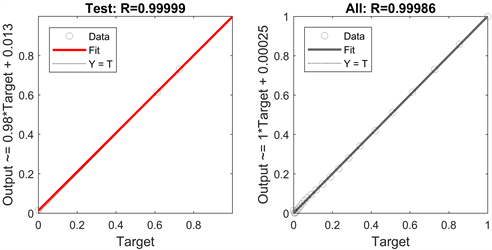
Figure 2. The regression analysis of the results after the grey relational degree screening variables
图2. 灰色关联度筛选变量后模型结果回归分析
Table 3. The prediction results and errors of the model after the grey relational degree screening variables
表3. 灰色关联度筛选变量后模型预测结果及误差
Table 4. The MIV value of the influencing factors
表4. 影响因素的MIV值
根据表4中13个变量的MIV绝对值的大小进行排序,可得X2和X5的影响程度最小,故剔除变量X2和X5,选取剩余的11个变量作为最终的输入变量。根据回归图3可得,训练集可决系数为0.99992,测试集可决系数为0.99986,模型的可解释性高。由表5可得,模型的相对误差均低于5%,绝对误差均低于1.5。模型的均方误差为0.9470,是当前均方误差最小的模型,其预测精度高于未变量筛选的GA-GM神经网络模型和灰色关联度筛选后的模型。
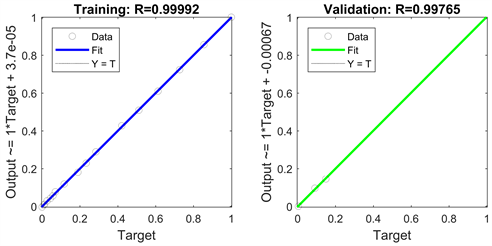

Figure 3. The regression analysis of the results after the average influence method screening variables
图3. 平均值影响法筛选变量后模型结果回归分析
Table 5. The prediction results and errors of the model after the average influence method screening variables
表5. 平均值影响法筛选变量后模型预测结果及误差
4. 结果比较分析
为了比较上述的三个模型的预测精度和拟合效果,由前面结果可得均方误差、相对误差MIN、相对误差MAX、绝对误差MIN、绝对误差MAX和测试集的可决系数。其中,均方误差是衡量估计量与被估计量之间的差异程度,均方误差越大,估计量与被估计量的差异也就越大,具体计算公式为:
,其中,
是被估计量的参数真值,
是估计量数值。相对误差是绝对误差与真值之比乘以100%所得,以百分数表示,是一个无量纲的值。绝对误差是预测值与真值之间的差值,有方向和大小,具有量纲。其中,相对误差和绝对误差越小,说明预测结果越精确。为了便于比较,将结果整理成表格的形式,如表6:
Table 6. Comparative analysis of model prediction effect
表6. 模型预测效果比较分析
由表6可得,
1) 未经过变量筛选的GA-GM模型相比经过变量筛选的模型存在较大的误差,拟合效果也较弱。
2) 比较灰色关联度法和平均值影响法,由表6可知,在均方误差、相对误差和绝对误差中,平均值影响法均低于灰色关联度法;但灰色关联度法的可决系数略高于平均值法。
3) 综合考虑上述模型,基于平均值影响法变量筛选的GA-GM神经网络模型的各种误差均最小,拟合效果好,所以确定该模型预测国内旅游人数。
为了更加直观的得到各个模型预测结果与实际值之间的关系,通过matlab画图,可以得到图4,可以发现3种模型的预测趋势均是逐年上升的,其中,MIV变量筛选后的预测值最接近实际值,预测的误差最低。
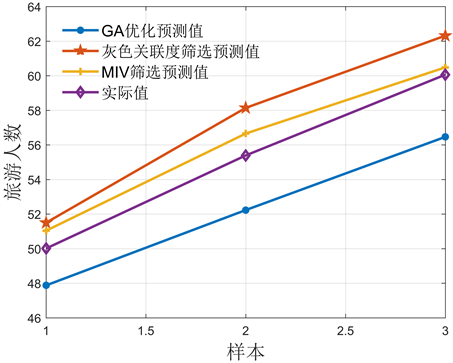
Figure 4. Comparison diagram of predicted value and actual value of each model
图4. 各个模型预测值与实际值对比图
5. 结论
由于旅游人数受到多种因素的影响,样本数据具有高维度、样本量小的特点,神经网络模型具有自学习性和自适应性的优点,故建立灰色神经网络模型,并不断对模型进行改进,最终确定基于平均值影响法变量筛选的GA-GM神经网络模型为旅游人数的预测模型。创新点在于一方面为旅游人数预测提供了新的算法,丰富了旅游人数预测方向的理论基础,拓宽了基于平均值影响法变量筛选后的GA-GM神经网络算法的应用范围;另一方面该文选取了两种变量筛选的方法,增加了模型的对比性,从而选取最优的模型进行预测。当解释变量已知时,就可以对旅游人数进行预测,有利于旅游业相关部门科学制定政策,开展旅游业相关的活动,对资源进行合理配置,促进旅游行业的健康发展。
本文搜集了1994~2019年共26年数据,所选取的样本数量太少,属于小样本,在一定程度上会影响预测值的准确性和可信性。若要进行更加准确性的研究分析,要使得样本容量尽可能地大。在模型之外的影响因素被忽略了,显然会对模型的精度造成一定程度的影响,因此所得的模型仍然需要进行优化修正,从而得到的预测效果更加接近于实际。
基金项目
本文由国家自然科学基金(61703083和61673100)和国家留学基金委(201706085041)赞助支持。