1. 引言
食用不新鲜的瓜果蔬菜是导致食品安全问题的一个重要因素,因此,为了更好的对新鲜果蔬进行管理,我们提出一个可以实现对各模块内存储的果蔬进行变质预警告这一功能的设备。首先应该将放入的水果和蔬菜进行识别,判断其种类是什么。通过对比选择深度学习对当前获取图像进行识别,可以达到一个较高的准确率,为了进一步提高图像识别的准确率,我们在Xception模型的基础上建立了一个池化层,三个全连接层,两个卷积层,调用了ReLU激活函数(一种人工神经网络中常用的激活函数,通常指代以斜坡函数及其变种为代表的非线性函数)、RMSProp优化器(也叫均方根算法,该优化器没有采用传统暴力直接的累加平方梯度,而是加了一个衰减系数来控制历史信息的获取多少),以及采用Dropout函数防止其过拟合。Xception是Inception-V3的极端情况(见图2),通过使用该模型结构,我们对测试集内的12种不同种类果蔬识别准确率最终高达91%。
2. 研究现状分析
上世纪八十年代,计算机视觉技术开始应用于果蔬识别范畴,1981年Graf等人 [1] 通过从苹果叶片形态的研究,实现了最大概率分类来检验苹果的损伤程度。1996年,Bolle等人 [2] 通过提取图像中果蔬的颜色,纹理等特征,第一次实现了对随意堆叠与摆放的水果蔬菜的识别与归类。2012年,Fabio等人 [3] 提出通过整合多种低成本分类器来识别目标果蔬,推动了超市果蔬自动销售系统的发展。2014年,陶华伟等人 [4] 采用结合颜色完全局部二值模式与颜色特征的方法获取目标纹理的特征,提高了果蔬智能识别系统的准确率。2016年,庄路路 [5] 提出基于改进的SURF算法对特征点进行检测和匹配,以实现对水果进行识别。
通过以上分析结果不难发现,研究人员在果蔬的识别检测领域展开了大量的研究工作,当然也不难发现,以上研究很多是根据统计模式的识别方法,基本都是人工设计算法来提取果蔬颜色、形状等特征。该方法实现较为单一,换用不同的果蔬又得重新设计算法,因此深度学习成了这方面的不二之选。在2012年的ImageNet图像分类大赛上,Hinton组采用了深度学习的方法一举夺魁 [6],且此方法准确率超第二名10%以上,突然之间这也掀起了深度学习的热潮。从经典的LeNet-5网络模型,到基于ReLU激活函数的卷积神经网络,再发展至基于随机Dropout的CNN网络,图像识别的精度越来越高 [7]。本文亦采用深度学习,通过搭建以下图1卷积神经网络模型来提高果蔬图像识别的准确率。利用该卷积神经网络模型,我们对果蔬图像的判断准确度较传统模型更高,这也意味着对果蔬种类的定位更精确,这也使得接下来对不同模块中存放的果蔬判断更准确。
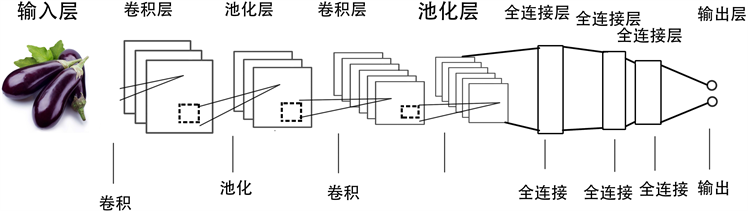
Figure 1. Fruit and vegetable recognition structure map of convolutional neural network based on Xception model
图1. 基于Xception模型的卷积神经网络的果蔬识别结构图
3. 方法
3.1. Xception
在Inception中,特征可以通过1 × 1卷积,3 × 3卷积,5 × 5卷积,pooling等进行提取,Inception特征类型的选择由网络进行训练,即一个输入同时输入到多个特征提取方法中,然后做concat。Inception-v3的结构图2如下。

Figure 2. Structure diagram of Inception-V3
图2. Inception-v3的结构图
对Inception-v3进行简化,去除Inception-v3中的avg pool后,输入的下一步操作就都是1 × 1卷积,结构如图3所示。
提取1 × 1卷积的公共部分,结构如图4所示。
Xception (极致的Inception):先进行普通卷积操作,再对1 × 1卷积后的每个channel分别进行3 × 3卷积操作,将结果归并得到的最终Xception模型如图5所示。
3.2. RMSProp
损失函数在更新过程中摆动幅度过大,函数的收敛速度较慢。为了改善上述两个问题,RMSProp算法采用微分平方加权平均法将权重W和偏置b的梯度进行加权。以下是预计到第t轮迭代过程的公式:
(1)
(2)
(3)
(4)
上述公式中的β是一个梯度累积的指数,公式(1)中的sdw是损失函数在前面的t − 1轮迭代过程中累积的梯度,公式(2)中的sdb是sdw的梯度动量 [8]。而RMSProp算法计算了梯度微分平方的加权平均值,这是不一样的地方。此举有效解决了前面所讲的两个问题,既有助于消除摆动幅度较大的方向,对摆动幅度进行校正,降低各维度的摆动幅度,又能加快网络函数的收敛速度。分析以上公式(3)和(4),只要dW或者db中有一个值较大,当我们更新权重或偏移量时,我们将它除以之前累积的梯度的二次方根(公式(3)中的
以及公式(4)中的
),这样可以降低它的更新幅度。最后,我们在公式(4)中取一个极小的平滑值ε (该数值一般取10−8)来避免分母为0。
4. 实验
4.1. 数据集
采用python爬虫的方式从网上爬取了12类共7200张图片。由于标签原因,其中有3045张图片被清洗掉。所以最终我们的数据集总共有12类、4155张果蔬图像。这12种类别为大枣、葡萄、西瓜、火龙果、龙眼、菠萝、花生、西红柿、胡萝卜、白菜、土豆、茄子,图6展示了本文收集的部分数据集。

Figure 6. Part of the data set is presented
图6. 部分数据集展示
4.2. 实验方法
本文构建了如图5所示的Xception模型的卷积神经网络模型。输入图像尺寸为150 × 150。采用批量随机梯度下降法迭代45个批次(45 epochs),对每次epochs,每输入样本容量大小/64个样本训练后,进行反向传播并更新一次权值。本文设置初始学习率为0.1,定义优化器RMSprop (Root Mean Square Prop)。本文将爬取的4155张水果蔬菜图片按照9:1的比例划分训练集和测试集,划分后的具体图片数量如表1所示。

Table 1. Division of training set and test set
表1. 训练集和测试集的划分
4.3. 实验结果
为了验证本文模型的有效性,本文进行了实验,实验过程中迭代轮次与其精确度及损失值如表2所示,其中epoch表示迭代轮次,Train accuracy和Train loss分别表示训练过程中的精确度和损失值;Validation accuracy和Validation loss分别表示测试过程中的精确度和损失值。训练过程中准确率越高意味着后面测试过程中也会更准确。从实验结果可以看出,迭代45个批次过程中Train accuracy最高到达了0.9634,而Validation accuracy最高也达到了0.9167,这可以看出我们构建的模型的有效性。
Table 2. The iteration cycles and their accuracy and loss values during the experiment
表2. 实验过程中迭代轮次与其精确度及损失值
可视化结果如下图7所示,训练精确度和测试精确度在逐渐增加,其损失值逐渐减小。

Figure 7. Accuracy (left) and loss value (right) change results
图7. 精确度(左)及损失值(右)变化结果
5. 结束语
本文针对果蔬图像形状易分辨的特点,设计了Xception模型的卷积神经网络,该网络能高效提取果蔬形状和纹理特征,网络层之间使用线性函数ReLU,来激活神经元使其快速收敛。在随机梯度下降的情况下,引入Dropout防止训练模型出现过拟合的问题,使网络具有更优的泛化效果。在未来的研究中,我们还将继续完善网络结构,以实现更高的识别效果。从而进一步促进深度学习在果蔬识别方面的应用。
基金项目
贵州省高等学校大学生创新创业训练计划项目:基于深度学习的食品健康分析处理模块化创新设计。