1. 引言
随着网络的快速发展,用户和商品数量不断增加,信息过载的问题越加显著,因此,推荐系统应运而生。协同过滤算法 [1] [2] 是推荐系统中最常用的推荐算法。此外,传统的协同过滤存在数据稀疏、冷启动、推荐结果准确率低等问题。针对上述不足,许多学者都对协同过滤算法进行了改进。唐泽坤 [3] 等在传统canopy聚类算法的基础上做了改进,较好地解决了用户聚类的问题。郑杰 [4] 等对人工蜂群算法进行改进,再将其与K均值算法有效地结合,最后证明了改进算法的有效性。向晓东 [5] 等通过项目相似度筛选出待预测评分项目的近邻用户集,在计算项目间偏差值时引入用户相似度,从而有效地提高了评分预测的可靠性。本文依据上述学者的思路,提出一种基于改进K-means聚类与融合用户属性特征的协同过滤推荐算法,该算法通过建立混合聚类模型进行聚类,接着将修正余弦相似度与用户属性特征进行融合形成一种新的相似度计算算法,最后给出推荐,进行实证分析,验证该算法的推荐效果。
2. 相关工作
2.1. Canopy聚类算法
Canopy是一种“粗”聚类算法 [6],相比其他聚类算法,它的优点在于得到簇的速度很快,抗噪能力强,简单易实现,但是精度较低,分类结果不稳定,可以结合K-means算法一起使用。
Canopy聚类算法步骤如下:
输入:n个对象的数据集D
1) 确定两个初始距离阈值t1、t2 (t1 > t2)。
2) 从数据集D中随机选取一个数据Q,计算这个数据Q到所有canopy的距离。
3) 如果当前没有canopy,则直接将Q作为canopy中心点,并将其从D中删除。
4) 如果Q与某个canopy的距离小于t1,则将Q标上弱标记并添加到这个Canopy中,同时需要把Q从D中删除(这个数据可以作为新的canopy来计算其他数据到这个点的距离)。
5) 如果与某个Canopy距离小于t1,大于t2,同样将Q加入到这个Canopy,但不将其从D中删除。
6) 如果Q与某个canopy的距离小于t2,则将Q标上强标记并添加到这个Canopy中,同时需要把Q从D中删除。此时认为这个数据点距离该canopy已经足够近了,不需要形成新的canopy。
7) 循环步骤2)~6),直至数据集D中没有数据。
输出:k个聚类中心。
2.2. K-Means聚类算法
K-means聚类算法 [7] 简单易实现,聚类效果好具体算法流程如下:
输入:原始数据样本集合X
1) 随机选取k个点作为为初始聚类中心。
2) 分别计算每个对象到聚类中心的距离,根据最小距离原则分配到最近的聚类簇中,并更新聚类中心。
3) 重新计算k个新聚类中心。
4) 若当前中心点和原中心点之间的距离小于设置的阈值,即可认为聚类已达到所期望的结果,算法终止。
5) 否则需要重复步骤2)~步骤4)直到聚类中心不再发生变化。
输出:k个簇的集合。
2.3. 修正余弦相似度
(1)
其中
是用户u和用户v的共同评分项目集,
和
分别表示用户u和用户v对项目i的评分,
是用户u的平均评分,
是用户v的平均评分。
3. 基于改进聚类的协同过滤算法
3.1. 改进K-Means聚类算法描述
先由Canopy算法进行粗聚类得到k个聚类中心,为了改进K-means算法初始点选取的随机性,本文引入“最大最小距离积法”对其进行优化,用来提升准确度,它的优点是算法所需参数少,使用最大最小距离乘积能选取到密度较大的点,稀疏初始点分布,并且大概率地可以避免出现区域内点密度相差很大而两个距离积相等的情况,同时点与点之间的差异可以用乘积来放大,使得选取的过程更具区分度。克服原始算法初始化的随机性。避免初始中心的选取过于稠密,从而出现聚类冲突的现象,并利用更新公式进行迭代寻优。再用K-means算法进行聚类。
3.2. 基于改进K-Means聚类的流程
改进K-means聚类算法步骤如下:
输入:n个对象的数据集D
1) 用Canopy算法进行聚类得到k值。
2) 从集合D中随机选取点作Z1为第一个初始点,将其加入集合Z中,并从集合D中删除。
3) 计算更新后D中所有元素到Z1的距离,选取距离Z1最大的点为Z2。
4) 将此点加入集合Z中,并从D中删除。
5) 分别计算更新后D中元素到Z中各个元素的距离并存入Temp中。
6) 计算D中每个元素对应的Temp的最大值与最小值的乘积(max (Texp) × min (Temp)),取该值最大对应点。
7) 如果选取的初始点个数 < k,则循环2)~6),直至输出包含k个初始点的集合Z。
8) 进行K-means聚类,得到最终聚类的结果。
输出:多个聚类簇
其中:D是包含所有数据的集合;k是要选取的初始点个数;Z是存储待加入的k个初始点的集合,算法开始前为空集;Temp是存储Z中各个元素到D中各个元素乘积结果的数组。
3.3. 融合用户特征相似度算法
在进行推荐时,由于性别,年龄,职业等不同,用户在选择项目时往往也不同,相同用户属性的人喜欢的项目也具有一定的相似性。传统的相似度计算方法经常会忽略不同用户属性的相似性,因此,本文将用户性别与年龄特征融入修正余弦相似度中。
1) 年龄属性相似度
用户u与用户v之间的年龄相似度如下:
(2)
式中:
取值范围为
之间,值越大,相似度越大;
为用户u的年龄;
为用户v的年龄。
2) 性别属性相似度。
用户u与用户v之间的性别相似度如下:
(3)
式中:
为用户u的性别;
为用户v的性别。
3) 用户属性相似度。综合上述年龄属性相似度、性别属性相似度,得出用户属性相似度如下:
(4)
式中
为属性的权重系数,在不同的推荐系统中,可以采用回归分析拟合对其调整。将用户属性相似度与修正余弦相似度相结合,可以得到一种新的相似度计算模型,即融合用户特征相似度计模型,如下:
(5)
式中
为权重系数。
3.4. 基于改进K-Means聚类和融合用户属性的协同过滤推荐算法
由于K-means算法聚类数和初始点的不确定性,所以先用Canopy进行粗聚类得到聚类数,这是因为Canopy聚类得到聚类簇的所用时间很短,并且抗噪能力强,接着因为最大最小距离积法能够选取密度较大的点,使初始点相隔较远,避免挨得很近过于稠密,所以引入最大最小距离积法确定初始点,接着用K-means算法对数据进行聚类。由于用修正余弦相似度计算相似度时,没有考虑用户属性之间的相似度,所以用融合用户属性的相似度计算,对目标用户未评分项目预测评分,并产生推荐。
基于改进K-means聚类和融合用户属性的协同过滤推荐算法的流程图如图1所示:
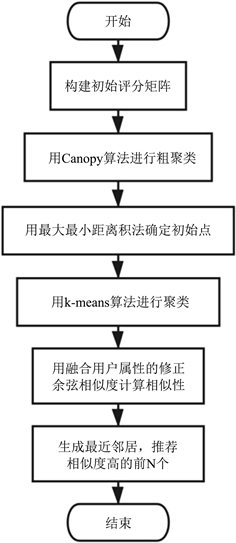
Figure 1. Collaborative filtering recommendation algorithm based on improved K-means clustering and user attribute fusion
图1. 基于改进K-means聚类和融合用户属性的协同过滤推荐算法
4. 实验数据
4.1. 实验数据集
本文使用是由明尼苏达大学Grouplens研究项目收集的Movielens-100 K数据集如表1所示。每个用户至少对20部电影进行1到5的评级。该实验使用5-折交叉验证方法实验。
4.2. 评估指标
本文在衡量推荐性能时,采用的是平均绝对误差(MAE)和均方根误差(RMSE),用来评估提出算法的预测性能 [8] [9],偏差越小推荐质量越高。
计算公式如下:
(6)
(7)
其中,T为测试集,
为测试集大小,
为用户对项目的预测评分,
为用户对项目的实际评分。
4.3. 实验结果与分析
4.3.1. 参数β的确定
由于新相似度的算法是由修正的余弦相似度与用户属性相似度线性组合得到的,β的取值对最终计算结果时非常重要的,最终相似度的公式取决于β取什么值,β的取值从0.1开始,每次增加0.1,一直增加到0.9停止。观察当β取不同值时,平均绝对误差的变化,从而确定β的最佳值,进而得到融合用户属性的修正余弦相似度的公式,实验结果如图2所示:

Figure 2. The effect of the parameter β on the MAE value
图2. 参数β对MAE值的影响
参数β表示混合在一起的修正余弦相似度与用户属性相似度中,用户属性相似度所占的比重,本实验可以看出当β取0.4的时候,也就是用户属性占四成的时候,平均绝对误差最小,相似度公式的计算效果达到最佳水平。
4.3.2. t2的确定
为了得到最佳粗聚类数,图3用来验证模型在不同下的准确度情况。
t2在[5, 40]区间内,以间隔为5来观察聚类数量对实验的影响,结果如图3所示在t2为25的时候达到最佳,在t2小于25时,MAE的值呈现下降趋势,在t2大于25时,MAE值又呈现缓慢上升的趋势,说明在t2为25时,为本文算法模型的最佳状态。

Figure 3. t2 Impact on MAE and RMSE
图3. t2对MAE和RMSE的影响
4.3.3. 本文选择以下五种算法进行MAE、RMSE、两个指标的比较
1) K-means User Clu (KUC)。单侧用户聚类算法,利用K-means聚类算法对用户进行聚类。
2) K-means Item Clu (KIC)。利用K-means算法对物品进行聚类。
3) Co Clust (CoC)。双侧用户聚类算法,将用户和项目进行联合聚类。
4) Canopy K-means Clu (CKC)。该算法采用改进后的Canopy K-means对用户进行聚类。
本实验的邻居用户数选取范围为0到50,间隔值为10,观察MAE,RSME的数值变化。图4是五种不同推荐算法在同一数据集上测试的MAE指标对比图,图5是五种不同推荐算法在同一数据集上测试的RMSE指标对比图。
通过图4和图5可以看出,所有算法的平均绝对误差值,随着最近邻居个数的逐渐增加而逐渐减少,接着又逐步趋于平缓。通过观察可以发现,当最近邻居值在15和45之间,本文算法能有效改善推荐算法的预测效果,对用户进行聚类能有效地提高推荐质量和推荐精度。
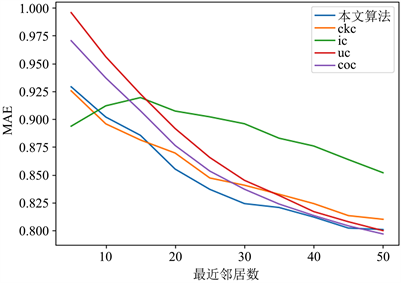
Figure 4. The influence of the number of nearest neighbors on MAE of this algorithm and other algorithms
图4. 最近邻个数对本文算法与其他算法MAE影响

Figure 5. Influence of the number of nearest neighbors on RMSE of the proposed algorithm and other algorithms
图5. 最近邻个数对本文算法与其他算法RMSE影响
5. 结论
本文提出了改进K-means聚类与用户属性相似性的协同过滤算法。将最大最小距离积法与混合聚类进行融合,同时用修正余弦相似度与用户属性相结合形成的新相似度算法计算相似性,最后进行相应的推荐。实验表明,无论在MAE指标还是在RMSE指标的比较上都获得了一定的优势,提出的算法能有效提高推荐算法的预测准确性,且有一定的实际意义。
参考文献
NOTES
*通讯作者。