1. 引言
汉语复句关系词的识别对汉语复句语义的识别至关重要,关系词在句中出现形式灵活、词性多变及其搭配多样,有些词在某类复句中充当关系词,在另一类复句中又不是关系词,给关系词的自动识别带来了一定的难度 [1] [2]。
目前对关系词进行自动识别的主要方法是使用基于规则的方法,用是否满足规则中的约束条件来识别关系词。已知的字面特征为12种,另外,根据依存树库中关系词在复句中的依存关系提取出7条约束条件,在关系词字面特征的约束条件基础上加入关系词依存约束条件,共19种约束条件用于识别汉语复句关系词 [3]。
关联规则挖掘包括单层关联规则挖掘和多层关联规则挖掘,单层规则挖掘算法包括Apriori、AprioriTid、AIS、SETM以及在Apriori算法基础上进行改进的FP-tree算法 [4],就这些算法的运行速度来说,对于大的数据集,SETM运行时间要比Apriori慢一个数量级;对于不大的数据集,Apriori的性能要比AIS好;对于小的数据集,AprioriTid和Apriori的性能差不多;但对于大的数据集,AprioriTid要比Apriori慢2倍左右;无论数据集的大小如何,相对于需要多次扫描数据集的Apriori来说,只需要扫描两次数据集的FP-tree算法性能更好 [5]。
本文在依存树库与现有规则库的基础上,使用FP-tree算法对复句关系词的依存关系规则进行自动挖掘,旨在挖掘更多潜在规则。
2. 研究现状
目前用于识别汉语复句关系词的约束条件共19种,其中基于字面特征的约束条件12种,基于依存关系的约束条件7种,编号从13~19。本文使用FP-tree算法对依存关系规则进行自动挖掘,对这7个约束条件在挖掘语料库中的表示形式规定如表1所示:

Table 1. Representation of dependency constraints
表1. 依存关系约束条件表示形式
表1中expression一列即是依存关系在挖掘语料中的表示形式,在expression中关系词的依存关系类型和依存关系之间采用:type-content,用i (依次取
)表示复句中的第i个关系词,不同约束类型之间用“,”隔开。
以例句(1)为例说明expression中的表示形式:
例句(1)高国胜想,既然能赚钱又不麻烦,就答应下来。《人民日报》1995年06月02日09版次
其依存分析如图1所示:
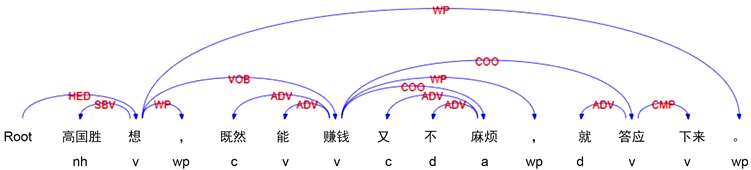
Figure 1. Dependency syntax analysis diagram of example 1
图1. 例句1的依存句法分析图
根据表1中expression中规定的表达形式,其依存关系可以表示为:131-v,132-a,141-ADV,142-ADV,15-1,161-0,162-0,17-0,18-1,19-COO。
FP-tree算法是在经典规则挖掘算法Apriori的基础上改进得到的 [6],Apriori算法最大的缺点是每计算一次候选项集就要扫描一次事物数据库,FP-tree则只需要扫描两次事物数据库,在不生成候选项的情况下,把事务数据库压缩到一棵只存储频繁项的树结构中 [7],从而实现Apriori算法的功能。
3. FP-Tree算法自动挖掘事务数据库中规则
本文的研究基于CCCS (CCCS语料库由华中师范大学语言研究所创建,包含65万余条汉语复句语料)汉语复句语料库,利用哈尔滨工业大学的LTP平台对语料库中的复句进行依存句法分析,构建依存树库,提取依存树中关系词的依存关系,并形式化表示为7种约束条件,在此约束条件基础上本文利用FP-tree算法挖掘语料库中频繁出现的依存关系规则。
下面用一个简单的例子阐明算法中涉及到的概念:
设事务数据库如表2所示:
项目:如表2中的“a”、“e”、“f”等表示一个项目;
事务:表2中每行表示一个事务,事务由若干个互不相同的项目构成,表中共五个事务;
模式:任意几个项目的组合称为一个模式,用{}包含一个模式中的项目;
支持数:指事务数据库中某个模式的个数,表2中模式{a, f, g}的支持数为3;
支持度:模式的支持数占数据库中事务的比例,计算公式如下:
(公式2.1)
表示事务数据库中所有模式的和,也即是挖掘语料中复句的总和,NUM(sameConstrains)表示模式的支持数 [8],也即是挖掘语料中包含某种频繁模式的复句总和,如模式{a, f, g}的支持度为3/5;
最小支持度(minSupport):提前设置好的,根据各项目在事务数据库中出现的次数设置最佳的
minSupport,本文设置最小支持度为
,
表示挖掘语料中复句的总和;
频繁模式:支持数大于阈值minSupport的模式称为频繁模式;
置信度:计算公式如下为
(公式2.2)
在上述公式中若NUM(sameConstrains)表示某模式α的支持数,即挖掘语料中包含某种频繁模式的复句总和,那么NUM(sameConstraintsAndsameResult)就表示包含模式α的β模式的支持数,即包含上述频繁模式的另一频繁模式的复句总和。例如模式{f, g}的支持数为4,支持度为4/5,{a}的支持数为3,支持度为3/5,那么{f, g} => {a}的置信度为,{a, f, g}的支持数除以{f, g}的支持数,结果为3/4,本文设置置信
度为
,即0.51。
FP-tree:首先建立一棵以NULL为根节点的树,然后统计事务数据库中各项的支持度,并将其按照降序排列,再依次插入到这棵树中,同时将每个项的支持度和树中相应的结点链接起来 [9],即可得到一棵FP-tree。
条件模式基(CPB):是指在一棵FP-tree树中出现在某一频繁项(结点)之前的所有祖先结点的集合 [10]。比如a在事务中一共出现了3次,那么a的条件模式基就是其祖先路径{f,g:3(频度为3)}。
条件树(PostModel):根据上述FP-Tree的形成步骤,把条件模式基构造成的一棵新的FP-tree,初始值为空。
FP-tree算法的四个关键步骤如下:
1) 构造项头表:扫描事务数据库,在表中记录频繁项集合F,将F根据支持度递减在表中排序 [11],得到项头表L。
2) 构造原始FP-tree:根据频繁项在项头表中的排序,重新排序事务数据库中每条事物的频繁项。并构造以NULL为根节点的FP-tree,将重排后的事务数据库中的每个事物的每个频繁项插入树中 [12]。插入频繁项时应遵循两个原则:① 若该频繁项节点在FP-tree中已存在,则将其节点的支持度加1;② 若该节点不存在,则创建支持度为1的节点,并把该节点链接到项头表中 [13]。
3) 调用FP-growth(Tree, null)进行挖掘。伪代码如下:
Procedure FP_growth(Tree,PostModel)
If Tree含单个路径P then{
For路径P中结点的每个组合(记做b)产生模式bUPostModel,其支持度
support=b中结点的最小支持度;
}
else{
for each在Tree的头部(按照支持度由低到高顺序进行扫描){
产生一个模式b=UPostModel,其支持度support=.support;
构造b的条件模式基,然后构造b的条件数tree-b;
If tree-b不为空 then
调用FP_growth(tree-b,b);
}
}
4) 递归调用FP-growth(新的CPB,新的PostModel),直到发现新的CPB为空时退出。
4. 数据预处理
本文在依存树库与现有规则库的基础上,使用FP-tree算法对关系词的依存规则进行自动挖掘,规则挖掘的内容包括两部分:一是挖掘规则库中不存在的关系词搭配;二是挖掘规则库中已有的关系词搭配的其他潜在规则,根据这两个挖掘需求对依存树库进行数据预处理,得到挖掘规则所需要的原始数据库。
4.1. 规则库中不存在的关系词搭配
首先介绍数据预处理用到的两个表的结构,分别是用于存储挖掘的新规则的表mining和用来存储规则库中不存在的关系词搭配的原始数据库result-1,result-1的结构和图2中依存树库的结构相同,表mining的结构如表3。
图2. 依存树库
Table 3. Structure of table mining
表3. 表mining的结构
表3中ID表示新的关系词搭配在表中的序号,根据写入表中的先后顺序对ID进行编号,从1开始,Keymarks表示新的关系词搭配,和原来的规则库中表示方法相同,dpType和dpconstrains分别表示挖掘出的新规则的依存约束类型和依存约束条件的形式化表示,result是关系词的判别结果,remarks里存储备注内容。
依存树库中关系词搭配的表示形式形如“一面,一面”,关系词搭配之间用“,”间隔,关系词搭配在规则库中的表示形式如“一面/一面”,关系词搭配之间用“/”隔开,对其中一种表示形式做适当变化,针对依存树库中的每一条数据都进行senmatch一列与规则库中关系词搭配一列进行比较,若senmatch中的关系词搭配在规则库中找不到相同的关系词搭配,则把新的关系词搭配存入表mining中Keymarks一列,并把依存树库中对应的一条数据存入到result-1中,得到的数据库及其格式如图3所示:
接着根据表mining中Keymarks一列中的关系词搭配对Result-1中的原始数据进行分类,得到各个关系词搭配的原始依存树库,如图4是新的关系词搭配“虽然/但因”的原始依存树库:
Figure 4. The original dependency tree library of “although/but because”
图4. “虽然/但因”的原始依存树库
得到每个关系词搭配的原始依存树库之后,通过运用复句特征分析器对复句中的依存关系进行分析,主要分析表1中的7个依存约束类型,规定分析之后的表示形式如表1中expression中所述,同时将senmatch列替换为规则库中关系词的判别结果result的表达形式,并将各个关系词的判别结果用“^”符号连接起来,则得到新的依存树库,依存树库的格式如表4所示:
Table 4. New dependency tree format
表4. 新的依存树库的格式
表4中expression是经过依存分析得到的依存约束条件的形式化表示,以关系词搭配“既然/又”为例,如图5即是得到的新的依存树库:
4.2. 规则库中已有的关系词搭配
挖掘规则库中已有的关系词搭配的潜在规则,是在之前的规则库对复句关系词的识别基础上,挖掘那些规则库不能识别的复句语料,把不能识别的复句按照关系词搭配分类,得到规则库中规则不能识别的已有关系词搭配的原始语料库,如图6所示是规则库中关于“不仅/还”关系词搭配所不能识别的原始依存树库:

Figure 6. Original dependency tree library of relational word collocation “not only/also”
图6. 关系词搭配“不仅/还”的原始依存树库
对图6中所得到的原始依存树库运用特征分析器分析其依存关系,并存入表4所示的expression列中,得到实验所需的挖掘语料,如图7即是规则库中已有关系词搭配“不仅/还”的挖掘语料:

Figure 7. Mining corpus for the collocation of relative words “not only/also”
图7. 关系词搭配“不仅/还”的挖掘语料
5. 基于FP-tree算法自动挖掘语料库中关系词依存关系规则
在本文的第2节中已经介绍了FP-tree算法如何自动挖掘规则,FP-tree算法能够挖掘出数据中的频繁模式,本节利用FP-tree算法挖掘语料库中频繁出现的规则。
如图5和图7是FP-tree算法进行挖掘所需的熟语料,主要针对熟语料库中的两列进行规则自动挖掘,分别是expression和result,expression列是关系词搭配的依存约束条件,result列是关系词搭配的判别结果,利用FP-tree算法挖掘出关系词搭配的依存约束条件与判别结果之间的频繁模式,算法的输入是经过特征分析器分析后的语料库,如针对关系词搭配“既然/又”进行规则挖掘的语料库格式如图8所示:

Figure 8. Corpus for rule mining with relational words collocation “since/again”
图8. 关系词搭配“既然/又”进行规则挖掘的语料库
图8中的每一条记录就是一条事务,读取事务时先读取expression列中的项然后读取result列中的项,两列之间的内容用“,”隔开,所有事务的集合即是要处理的数据集合,语料库中关系词搭配是“既然/又”的复句共522条,所以供挖掘的数据集合中包含522条数据,即
= 522,为保证挖掘规则的实用性,本文对最小支持度和置信度的设置采取过半原则,即只挖掘超过挖掘数据集一半的规则,因此本次
挖掘设置最小支持度minSupport =
,即minSupport = 262,置信度Confident = 0.51。
算法描述如下:
输入:语料库中的数据集合 List< List< String > > transactions;最小支持度minSupport;置信度Confident
输出:依存规则与关系词判别结果的频繁模式集合Map< List< String >,Integer >;频繁模式的频数FrequentPattens
初始化PostModel=[],CPB=transactions
voidFPGrowth(List< List< String > >CPB,List< String >PostModel){
If CPB为空{
return;
}
else{
统计CPB中每一个项目的计数,把计数小于最小支持数minSupport的删除掉,对于CPB中的每一条事务按项目计数降序排列。
由CPB构建FP-Tree,FP-Tree中包含了表头项headers,每一个header都指向了一链表HeaderLinkList,链表中的每个元素都是FP-Tree上的一个节点,且节点名称header.name相同。
}
For header in headers{
newPostModel=header.name+PostModel
把< newPostModel, header.count>加到FrequentPattens中。
newCPB=[]
Or TreeNode in HeaderLinkList;
得到从FP-Tree的根节点到TreeNode的全路径path,把path作为一个事务添加到newCPB中,要重复添加TreeNode.count次。
}
FPGrowth(newCPB,newPostModel);
}
根据上述FP-tree算法对“既然/又”的关系词搭配进行自动挖掘的结果如图9所示:

Figure 9. Automatic mining results of the relational word collocation of “since/again”
图9. “既然/又”的关系词搭配自动挖掘结果
从实验结果可知,由依存约束条件131-v,132-v,141-ADV,142-ADV,15-1,161-0,162-0,17-0,18-1,19-COO推出关系词搭配判别结果R (既然) = true^R (又) = true的支持度为407,置信度为1。
从上述自动挖掘结果可得一条关于关系词搭配“既然/又”的依存规则,解析:
[131-v,132-v,141-ADV,142-ADV,15-1,161-0,162-0,17-0,18-1,19-COO]->R(既然)=true^R(又)=true
可以得到“既然/又”的依存约束规则如表5所示:
Table 5. Dependency constraint rules of “Since/again”
表5. “既然/又”的依存约束规则
本节主要对复句关系词搭配的依存关系进行自动挖掘,共挖掘出87条规则,其中包括普通规则32条,连用规则20条,句式规则22条,连用句式规则13条,如图10是自动挖掘得到的普通规则ordinary-mining的部分截图:

Figure 10. Some screenshots of ordinary-mining
图10. 普通规则ordinary-mining的部分截图
将挖掘得到的规则并入到原来的规则库中,由于原来的规则库中规则包括两部分,字面特征规则和依存约束规则,本节主要对依存约束规则进行挖掘,因此,字面特征约束类型constraintType和约束条件constraints两列的值默认为空即可。
6. 总结
汉语复句关系词的依存关系是指根据依存语法研究汉语依存树库中众多树形图节点之间的支配与被支配的关系,即分析经过分词后的复句中关系词之间的支配关系,把线性的复句转化为一颗依存结构树,对树形结构我们都不陌生,依存树中同样存在根节点、中间节点和叶子节点,只是在依存树中占据每个节点的是词 [14]。
关系词的依存关系自动识别是理解复句语义层次的关键,目前对关系词自动识别的研究主要集中在字面特征和语法角度理解关系词,本文在汉语复句依存句法分析基础上,根据已有的7种依存约束条件,运用频繁项集挖掘算法FP-tree对依存树库中的隐藏规则进行自动挖掘,完善现有依存规则。自动挖掘规则的内容包括两部分,首先在依存树库中挖掘规则库中不存在的关系词搭配,然后,挖掘在规则库中已经存在的关系词搭配的其他规则,根据这两个挖掘需求,对实验语料进行依存特征分析,并将实验语料所需的依存约束条件进行形式化表示。实验共挖掘出84条依存规则。
但对于关系词自动识别的研究并不止于依存句法分析,在规则库中加入关系词所在分句的语义特征分析,根据语义相似度及相关度是关系词自动识别的下一步研究方向。