1. 引言
磁共振成像(MRI)是临床实践中广泛使用的医学成像工具,通常用于一些疾病的诊断和治疗。空间分辨率是MR最重要的成像参数之一,清晰的磁共振成像图像可以提供丰富的结构细节信息,便于早期准确的诊断。但MR图像的分辨率受多种环境因素限制,想要更高的空间分辨率往往需要依靠减少SNR或者增加扫描时间的方式来实现 [1],由于诊所的成像系统、成像环境和人为因素不同,导致低分辨率和高噪声的磁共振图像的产生无法避免。
因此我们对图像进行超分辨率重建技术的研究,来提高医疗核磁共振图像的分辨率和质量。经典超分辨率算法可以分为三类:基于插值的方法 [2],基于重建的方法 [3],以及基于学习的方法 [4]。
基于插值的方法主要包括线性插值与非线性插值,如最近邻插值(NN),双线性插值(双线性)和双立方插值(双立方)。将插值像素插入到原始图像中,然后得到相应的放大图像。这种算法复杂度较低,但由于效果一般,所以适用性并不广泛。
基于重建的方法是利用信号和系统来解决成像问题的逆向过程,其中主要处理高频率信息,缺点是计算复杂性非常高。虽然这些传统的超分辨方法可以在一定程度上重建高分辨率图像,仍然存在一些问题需要进一步进行研究,如光滑边缘和纹理细节。
近年来,随着机器学习特别是深度学习的发展,在超分辨重建问题上体现出极大的价值。基于学习的理念,这种方法学习了低分辨率图像与高分辨率图像之间的映射关系,用来重建高分辨率图像。
深度学习已在超分辨领域获得显著的效果,从最初仅包含三个卷积层的超分辨率重建卷积神经网络(SRCNN) [5],其速度上有极大提升的加速图像超分辨率卷积神经网络(FSRCNN) [6]。何凯明在2015年提出的深度残差神经网络(ResNet) [7] 解决了之前网络结构比较深时无法训练的问题,性能也得到了提升,残差网络结构(residual network)被应用在了大量的工作中,超分辨领域提出了对应的深度残差超分辨率重建网络(SRResNet) [8]。作为其衍生的深度全局残差学习网络(VDSR) [9],运用学习残差的结构,对结果进一步提升。
图像超级分辨深度递归卷积网络(DRCN) [10] 第一次将之前已有的递归神经网络结构应用在超分辨率处理中,同时利用残差学习的思想,加深了网络结构(16个递归),增强网络的感受野,从而达到提升性能的效果。深度递归残差图像超分辨网络(DRRN) [11] 受到ResNet、VDSR和DRCN的启发,采用递归结构使得网络模块的参数共享,并且采用了更深的网络结构来获取性能的提升。密集卷积网络(DenseNet) [12] 是CVPR2017的最佳获奖论文,DenseNet在密集模块(dense block)中将每一层的特征都输入给之后的所有层,使所有层的特征都串联起来,而不是像ResNet那样直接短路径添加,这样的结构给整个网络带来了减轻梯度消失问题、加强特征传播、支持特征复用、减少参数数量的优点。作为其衍生,超分辨领域提出了相应的密集卷积图像超分辨网络(SRDenseNet) [13],以及将残差模块(Residual block)和密集模块(Dense Block)相结合的残差密集深度网络(RDN) [14],还有引入了注意力机制的残差通道注意力网络(RCAN) [15]。
一般的超分辨网络中鲜少运用到模型先验信息,超分辨网络也很少运用到多尺度信息。本文提出的算法有以下三点贡献:1) 在损失函数中添加全变分正则化项来降低生成图像的噪声;2) 网络结构中添加多尺度残差模块,在后续网络层结构中补充更多图像的高频特征;3) 本算法的结构相对于先前的网络在性能上有显著提升。
2. 模型的建立
2.1. 图像超分辨重建网络框架
网络框架见图1整体网络框架,和传统的超分辨网络基础框架类似,它具有三个主要组成部分,分别为特征提取、非线性映射和图像重建。特征提取部分将输入的低分辨图像x提取出浅层特征,这些浅层特征接着传输进非线性映射部分,非线性映射部分由一系列模块构成,最后将收集到的层次特征输入图像重建部分,来生成整个模型的高分辨图像y。
2.1.1. 特征提取
如图1所示,用x和y分别代变网络的输入和输出图像,使用两层卷积网络来提取浅层的特征,第一层卷积网络从输入的x提取出特征
。
这里采用参数化纠正线性单元PReLU作为每个卷积层后的激活函数,来代替常用的修正线性单元ReLU [6] [16] 激活函数,PReLU引入了一个可学习的参数,可以避免ReLU中零梯度造成后续特征不可被激活的情况。PRELU被定义为:
(1)
其中
是第
层卷积层的输入,而
是负部分的系数,当
时PReLU就退化为ReLU。
(2)
其中
表示特征提取部分中的第一层卷积操作,第一个卷积层有128个滤波器,使用
的卷积核,步长为1,生成的特征图通道数为128,
表示PReLU激活函数。
将输出的浅层特征
输入进第二层卷积层
(3)
其中
表示特征提取部分中的第二层卷积操作,第二个卷积层有128个滤波器,使用
的卷积核,步长为1,生成的特征图通道数为128,
表示PReLU激活函数,其输出的特征为
。
2.1.2. 非线性映射
非线性映射层是超分辨重建中的关键步骤,其映射的高维矢量代表了相应的高分辨率部分 [6]。由多个组合的多尺度残差模块堆叠而成,来实施非线性映射。将
输入进第一个模块,同时引入局部残差学习的方法将
通过短连接的方式加到每一个模块后,从而改善信息流,提高网络表现能力,以此产生更好的性能。
(4)
其中
代表第一个多尺度残差模块的复合函数操作,包括了一系列卷积和激活函数,输出的特征
继续输入进后面的模块
(5)
(6)
其中
,
表示第
个模块的复合函数操作,
和
分别表示第
个模块的输入和输出,当
取到
时,得到整个线性映射部分的输出
。
2.1.3. 图像重建
在提取完局部与全局特征后,将
输入
的卷积层进行图像重建,生成的特征图通道数设为1,步长设为1,使用PReLU作为激活函数,其输出为图像
(7)
其中
表示卷积操作,
表示PReLU激活函数,其输出为图像
,接着利用全局残差学习来获得特征图,整体网络的输入图像
通过残差学习短连接的方式对图像
进行补充,输出高分辨图像
(8)
2.2. 多尺度残差模块
图2展示了非线性映射部分的多尺度残差模块的细节,普通的残差网络是将每个残差单元短连接来构建深度比较大的网络。在本模块中将输入图像进行多尺度的卷积操作后,利用残差方式短连接到输入图像,可以补充更多丰富的高频信息,来有效地进行局部残差学习。此外,这种多尺度短连接可以携带更多的高频信息进入到更深的网络。
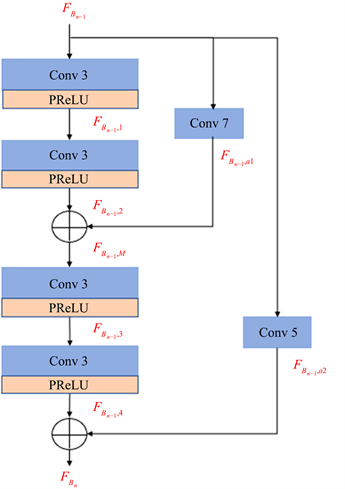
Figure 2. Multi-scale residual module structure diagram
图2. 多尺度残差模块结构图
模块的输入为
,将其进行两层
卷积与PReLU激活
(9)
(10)
其中
和
表示卷积操作,卷积层滤波器个数均为128,
表示PReLU激活函数。
使用
的卷积核提取
高频的图像信息用短连接的形式添加在
上
(11)
(12)
其中
表示
卷积操作,卷积层滤波器个数为128。
接着将
作为输入,继续进行两层
卷积与PReLU激活
(13)
(14)
其中
和
表示卷积操作,卷积层滤波器个数均为128,
表示PReLU激活函数。
使用
的卷积核提取
高频的图像信息用短连接的形式添加在
上
(15)
(16)
其中
表示
卷积操作,卷积层滤波器个数为128。
2.3. 损失函数
在超分辨重建中,损失函数用于测量生成的高分辨SR图像与真实的高分辨HR图像之间的差异,并指导模型进行优化,正则化可以防止模型在训练中出现过拟合。
像素损失用来测量两个图像像素之间的差异,通常采用L1正则化和L2正则化。为了简化表示,将
代表模型生成的高分辨SR图像,I代表原始作为目标的高分辨HR图像,这里采用L2正则化,即最小平方误差
(17)
其中
分别是图像的长、宽和通道数。
为了抑制生成图像的噪声,我们将全变分正则化 [16] 引入此超分辨重建算法中,它能去除图像噪声,有效地保留图像边缘信息,有助于优化重建后的图像。它被定义为相邻像素之间绝对差异的总和,并测量图像中的噪声量,对于模型生成的高分辨SR图像
,全变分正则化函数定义为
(18)
模型的损失函数结合了L2正则化与全变分正则化
(19)
其中
为参数。
3. 实验与结果
3.1. 数据集
为了评估本文所提出的图像超分辨重建网络算法的性能,使用三个真实的核磁共振(MR)图像数据库。第一个真实的核磁共振图像数据集是从iSeg-2017对于6个月的婴儿大脑核磁共振图像的分割任务中获得的(http://iseg2017.web.unc.edu/)。第二个真实的核磁共振图像数据集是从大脑分割测试网站下载的ALVIN数据集 [17] (https://sites.google.com/site/brainseg/)。第三个临床数据集来自2015脑肿瘤图像分割基准BRATS数据集 [18] (https://www.smir.ch/BRATS/Start2015)。所有数据集均采用轴向平面中常用的T1维度的核磁共振图像。
3.2. 实验评价指标
在实验中,使用以下两个个指标来评估图像重建算法:1) 峰值信噪比(PSNR) [19] 2) 结构相似性(SSIM) [20]:
(20)
(21)
其中MSE表示当前图像X和参考图像Y的均方误差,n是每个像素的位数,如果每个像素都由8位二进制来表示,那么灰度图像的最大像素值为255。
和
分别代表当前图像与参考图像的像素值,H和W代表图像的长和宽。PSNR是图像评价的客观标准,PSNR数值越高,图像的失真就越小。
(22)
其中
、
和
代表亮度、对比度和图像相似性,SSIM数值越高,代表生成图像与参考图像的相似度越高。
3.3. 实验结果
将原核磁共振图像进行双三次插值Bicubic [21] 再下采样,得到与原高分辨HR图像大小相同的低分辨率LR图像作为算法的输入,并将其切片成31 × 31大小的图像,用于超分辨算法的训练,上述超分辨对比算法均在python2.7的pytorch框架上进行运算,实验的操作系统为Ubuntu16.04,CPU为Intel(R)E5-2620@2.1 GHz,GPU配置为TITAN X。本文提出的算法损失函数中的参数
取值为0.1,多尺度残差模块的个数取为4,则网络深度为19。使用Adam算法来优化模型,迭代地更新神经网络的权重,其中权重衰减(weightdecay)设为0.0001,动量(momentum)设为0.9,一次训练所选取的样本数(BatchSize)为64。训练时每30个时期(epoch)进行学习率衰减,从初始值
降低至
。
为了验证我们的方法对大脑核磁共振图像数据集的影响,将此方法与其他超分辨图像重建方法进行比较,包括了超分辨率卷积神经网络(SRCNN)、加速图像超分辨率卷积神经网络(FSRCNN)、残差通道注意力网络(RCAN)、残差密集深度网络(RDN)、深度全局残差学习网络(VDSR)、深度递归残差图像超分辨网络(DRRN)。为了保持对照实验的公平性,将网络深度较大的RCAN、RDN与DRRN中各自的模块个数减小,使其网络深度与本算法类似进行对比实验。
3.3.1. iSeg-2017数据集
我们在iSeg-2017数据集上进行实验,此数据集为临床六个月的婴儿大脑核磁共振图像。我们随机地抽取15个T1维度的核磁共振3D图像,图像大小为
,在每一个3D核磁共振图像中选取第131张到160张,也就是30张轴向平面图像用作训练。
图3展示了由不同的超分辨算法在婴儿大脑图像iSeg-2017数据集上生成的结果,本文提供的算法提供了更丰富的细节和显著的边缘,表1展示本算法获得了最佳峰值信噪比(PSNR) 36.92 dB和最佳结构相似度(SSIM) 0.9262。

Table 1. Results of different algorithms on the iSeg-2017 T1 MR Image database
表1. iSeg-2017 T1 MR图像数据库上不同算法的结果
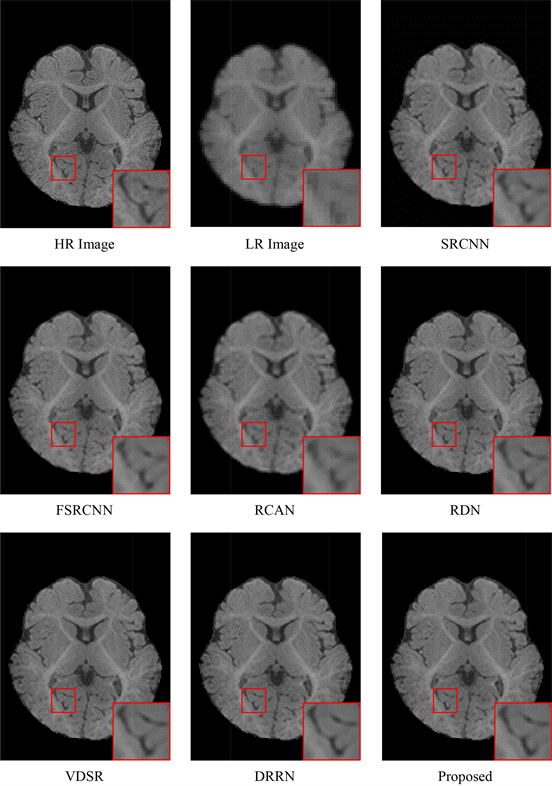
Figure 3. Results of the reconstructed HR MR image by different algorithms on an example image from the iSeg-2017 MR T1 image data
图3. iSeg-2017 MR T1数据示例图像上不同算法重建的高分辨率SR图像的结果
3.3.2. ALVIN数据集
我们在ALVIN数据集上进行实验,此数据集为临床成人大脑核磁共振图像。我们随机地抽取15个T1维度的核磁共振3D图像,图像大小为
,在每一个3D核磁共振图像中选取第131张到160张,也就是30张轴向平面图像用作训练。
图4展示了由不同的超分辨算法在在成人大脑图像ALVIN数据集上生成的结果,本文提供的算法提供了更丰富的细节,表2展示本算法获得了最佳峰值信噪比(PSNR) 38.42 dB和最佳结构相似度(SSIM) 0.9619。
Table 2. Results of different algorithms on the ALVIN T1 MR Image database
表2. ALVIN T1 MR图像数据库上不同算法的结果
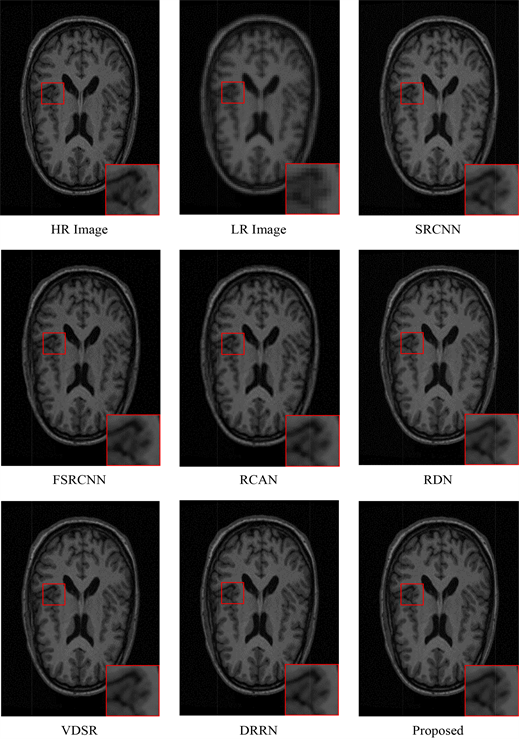
Figure 4. Results of the reconstructed HR MR image by different algorithms on an example image from the ALVIN T1 MR image data
图4. ALVIN T1 MR数据示例图像上不同算法重建的高分辨率SR图像的结果
3.3.3. BRATS数据集
我们在BRATS数据集上进行实验,此临床数据集为脑肿瘤图像。随机选择了20个T1对比增强型MRI图像与胶质母细胞瘤图像,图像大小为
,在每个3D核磁共振图像中选取第65片到第99片,也就是35个轴向平面图像。由于该图像空白处过大,将轴向平面图像截取至
用作后续训练。
图5展示了由不同的超分辨算法在成人大脑肿瘤图像BRATS数据集上生成的结果,本文提供的算法提供了更丰富的细节,表3展示本算法获得了最佳峰值信噪比(PSNR) 36.35 dB和最佳结构相似度(SSIM) 0.9579。
3.4. 实验结果分析
在这项工作中,我们提出了一种新的基于多尺度残差学习和正则化的超分辨算法,用于核磁共振图像的重建。基于三个真实MR图像数据集的结果显示,本文提出的算法优于其他超分辨算法。
全局残差学习用于学习图像细节信息,在基于卷积神经网络的超分辨算法中已经得到了广泛的应用,在算法的。但是由于图像细节信息在比较深的卷积神经网络中会因退化问题而丢失,所以其性能会受到一定的限制。局部残差学习结构可以在一定程度上克服这个问题,因为局部残差学习使用的短连接传输细节信息,以此补偿某些缺失的信息。我们结合了基于浅层网络模块的局部残差学习与传统的全局残差学习,来提高算法的图像重建性能。
我们在网络中的非线性映射部分使用局部残差学习模型,该部分由多个多尺度残差模块堆叠。在多尺度残差模块中,实施浅层卷积分支与深层卷积分支的多尺度要素总和的策略。如图2多尺度残差模块结构图所示,浅分支为深分支提供了叠加的更丰富的高频特性,而深分支则将细节信息传输到较远的残留方块。为了研究多尺度残差连接对网络的影响,我们删除
与
的卷积特征提取及短连接,在ALVIN数据集上进行相同环境下的训练,实验结果显示在表4中。
大部分深度学习超分辨重建网络损失函数仅使用一项,为L1正则化或L2正则化,本文引入全变分正则化项,它能去除图像噪声,有效地保留图像边缘信息,有助于优化重建图像。为了研究全变分正则化项对网络的影响,我们在损失函数中删除此正则化项,在ALVIN数据集上进行相同环境下的训练,实验结果显示在表4。
由表4可看出多尺度残差学习对算法的实验结果有比较大的提升,更多更丰富的高频信息得以保留并传输到网络的下一层继续训练,全变分正则化降低生成噪声,当正则化项参数选取得当的情况下对训练结果有一定的提升。
Table 3. Results of different algorithms on the BRATS T1 MR Image database
表3. BRATS T1 MR图像数据库上不同算法的结果
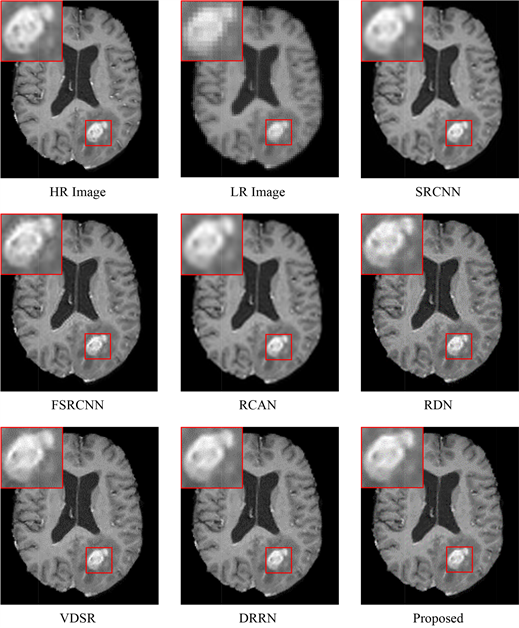
Figure 5. Results of the reconstructed HR MR image by different algorithms on an example image from the BRATS T1 MR image data
图5. BRATS T1 MR数据示例图像上不同算法重建的高分辨率SR图像的结果
Table 4. Model analysis of this method on the ALVIN image verification set
表4. ALVIN图像验证集上对此方法的模型分析
4. 总结
本文我们提出了一种改进的深度学习超分辨网络,通过使用多尺度残差模块以及正则化项的创新,来提高算法在临床大脑核磁共振图像超分辨重建任务上的准确率。此算法可以有效地重建大脑核磁共振图像的细节信息,通过在三个临床MR图像数据库上的实验结果表明,在没有增大算法复杂程度的情况下,本文提出的算法性能优越,与目前先进的超分辨算法相比有显著的提升。
基金项目
国家自然科学基金项(1197010603)。