1. 引言
我国土地广大,物产丰富,陆地面积居世界第三,拥有丰富的农业资源。实际生活中,人工识别农作物病害不仅耗费人力,还会造成识别不准确用药错误等情况。因此借助计算机和互联网技术 [1] 实现对农作物病害的准确快速识别尤为重要。随着深度学习 [2] 在机器学习领域中不断发展,如今使用卷积神经网络 [3] 来解决图像分类中的问题逐渐成为主要手段 [4]。近年来更是不断的应用在目标检测 [5]、图像识别 [6] 等方面。Srdjan等 [7] 利用卷积神经网络模型对13种病害进行识别,该模型拥有分辨植物叶片与其周围环境的能力,且模型识别率较高。龙满生等 [8] 研究员将迁移学习应用在卷积神经网络中,实现了对油茶的五种病害图像的识别,该研究为其他植物叶片病害智能诊断提供了参考价值。上述研究均是对农作物病害进行识别,和人工识别方法相比,卷积神经网络的特殊之处在于实现了自动化的区分和提取特征并直接得出预测结果,这样的操作过程简单透明,且拥有强大的泛化性能。
本文利用残差网络能有效的解决梯度弥散、避免信息丢失等问题的优点,提出一种基于迁移学习和残差网络的模型对农作物病害图像进行识别,并对模型进行参数微调,提高农作物病害图像的识别分类的性能,实现快速有效的识别。
2. 实验数据
2.1. 病害图像数据集
本文的研究对象为苹果、马铃薯、葡萄、玉米、辣椒和草莓这6种农作物所患的19种病害叶片图像,收集以上种类的病害图像作为本文的数据集样本,图像采集主要采用的方法是通过互联网搜索植物村(plant village)、美国植物病例协会(APS Net)等植物病害网站,在网站中下载需要的病害图像。利用OpenCV对数据集进行预处理来规范数据集,预处理主要由筛选图像、统一格式和尺寸名称以及确认分类等步骤组成。筛选的主要工作内容为:将重复的图像去除;将某农作物病害类别中不是该类的农作物病害图像找到所属的类别然后重新分类;将病害图像分辨率过低或是清晰度过低的删除。本文为了试验方便,统一将所有非JPG格式图像转换为JPG格式。为了方便试验,将所有手机的图片统一为一个尺寸即299 × 299像素。文件夹以及图像的名称均以该农作物病害种类及其患病程度的英文名称命名。初步归类完成后请教相关专业的技术员帮忙进行进一步确认,以确保正确性。
将预处理后的病害图像人工分为19种类别,分别用0~18表示对应的类别标签。
2.2. 图像数据增强
网络模型的性能极大一部分由数据集的大小决定,拥有充足的数据集是模型拥有强大的泛化能力的大前提。然而病害图像相比于其他的数据集来说,收集难度更大。因此采用数据增强技术对数据集进行扩充。
本文通过使用数据增强技术,将数据集中的每张图像都生成了大量不同的样本。本文主要对样本采用四种增强方式:随机剪裁,翻折,图像调亮,随机翻转(60˚、90˚、180˚、270˚)。一定程度上缓解了模型训练数据不足的情况,避免训练时因数据过少而产生过拟合,从根本上提升了模型整体性能(图1)。
3. 实验方法
3.1. 残差网络结构
残差网络中的残差块结构图如图2所示。
假设残差单元的神经网络的输入为
,期望输出为
,由于残差网络结构是输入与输出直接相连,输出的初始结果即输入值,所以学习目标为
,即残差。残差块中将输入连到输出端的支线被称为捷径连接。这种连接实现了信息的直接相连,降低了残差网络的复杂性,使得深度网络更快的被训练。残差单元可以定义为:
(1)
式中:
和
分别为第
个残差单元的输入和输出,
为待学习的残差映射,
为卷积核,
为激活函数,采用线性整流函数(Rectified Linearunit, ReLU),其公式为:
(2)
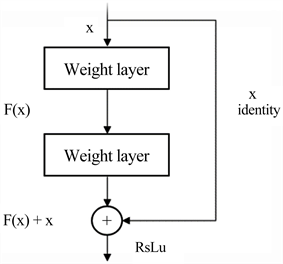
Figure 2. Schematic diagram of residual unit
图2. 残差块示意图
3.2. 迁移学习
深度学习的发展,带来了更多复杂的模型 [9]。而模型学习是建立在大量训练样本的基础上,如果没有大量样本数据,将会无法开展很多深度学习的研究与应用。现实中收到诸多因素的影响,能够获得的有标签数据量非常少,无法支撑深度神经网络的训练。为了解决这些问题,研究者们提出来迁移学习这一概念,主要方法是首先将识别模在大型数据集上训练,然后将训练好的模型直接应用在数据集样本较少的研究识别任务中。这种迁移学习的方法可以提高模型性能,减少资源损耗 [10]。
本文选用迁移学习的方法进行农作物病害识别研究,首先在ImageNet [11] 数据集上训练ResNet_50模型,并将训练得到的参数作为农作物病害识别模型的初始参数,继而将训练好的ResNet_50模型在农作物病害数据集上进行训练,根据训练的结果对模型进行微调。迁移学习方法流程图如图3所示,由于预训练的ResNet_50模型是1000类ImageNet分类器,因此我们将其全连接的最后一层替换为识别任务中所包含农作物病害类别数的分类器。

Figure 3. Migration learning method flow
图3. 迁移学习方法流程
3.3. 学习率优化算法
卷积神经网络的核心问题之一是如何调整参数来最小化损失函数,损失值越小意味着模型对数据的拟合程度越好,然而神经网络模型非常复杂,通过直接求解最优参数的方式并不可行,因此研究人员提出了各种基于梯度下降的优化算法进行迭代求解。常见的优化算法包括固定学习率的SGD算法和自适应梯度的Adagrad,RMSprop,Adam [12],AdaDelta算法。Adam作为自适应梯度算法中的一种,是由Kingma于2014年提出的一种梯度更新方法。它集合了RMSProp和AdaGrad算法最优的性能,与其他学习率算法相比,Adam算法拥有较高的计算效率,所以收敛速度更快,内存占有低,并且在一定程度上能避免出现局部最优解的情况。
本文使用Adam算法,通过对梯度的均值和梯度的未中心化的方差进行综合计算来调整学习率。梯度的均值
的表达式为:
(3)
梯度的未中心化的方差
的表达式为:
(4)
在t时刻对应参数的梯度
表达式为:
(5)
表达式中:
为梯度的均值的指数衰减率,默认为0.9;
为梯度的未中心化的方差的指数衰减率,默认为0.999;下标
为当前时刻;下标
为前一时刻。
由于
、
初始化均为0向量,对其进行偏差纠正来避免对训练初期的影响:
(6)
(7)
更新参数:
(8)
式中:
为学习率,设为0.001;
为避免除数为零设为10−8。
3.4. 交叉熵损失函数
在卷积神经网络模型来识别图像,识别的结果则是模型的预测值,而识别的目标是真实的,所以预测值和真实值之间必有一定的差距,为了评价这个差距的程度,就有了损失函数,也就是说损失函数就是用来评价模型的预测值与真实值的差距。损失函数越好,那么差距越小,说明模型的性能越好。卷积神经网络拥有各种不同的模型,不同的模型适用的损失函数一般情况下均不同。比较常见的损失函数有对数损失函数(logloss)、指数损失函数(exponential loss)、Hinge 损失函数、感知损失函数(perceptron loss)、交叉熵损失函数(Cross-entropy loss function)等。交叉熵损失函数(Cross-entropy loss function)的本质其实也是一种对数似然函数,在模型的激活函数为sigmoid函数的时候,模型通常使用交叉熵损失函数,因为交叉熵损失函数在模型训练误差较大时可以很快的更新权重,误差小时则更新慢。交叉熵损失函数的表达式为;
(9)
式中:
为训练损失;
为期望的类别概率;
为批次训练样本;
为预测的类别概率;类别概率由Softmax计算。
4. 识别环境及实验结果
4.1. 实验环境与过程
本文的试验所用的处理器为Inter(R) Core(TM)i7-6700HQ 2.6 GHz,显卡为NVIDIA GeForce GTX1060,内存为16 GB,操作系统为Windows64位系统,CUDA 9.0,CUDNN 7.0,深度学习框架TensorFlow-GPU 1.8.0,编程语言Python 3.6,集成开发环境PyCharm 2018,绘图工具为Matplotlib 1.5.1。
本文试验均在Tensorflow深度学习框架下通过GPU加速完成。经过一系列的对比测试试验,本文最终的参数设置为:批次样本数量设置为16、迭代步数为30,000步、初始学习率设为0.01、学习率的优化算法采用Adam算法、激活函数均为Relu函数、模型分类器均选用SoftMax分类器。为了更好的评估真实值和预测值之间的差距,均选用交叉熵损失函数。
4.2. 实验结果与分析
实验结果如图4所示,其中(a)表示准确率在训练集和验证集的变化,图中曲线变化可以看出在10,000之前涨幅较大,迭代次数达到10,000之后呈缓慢增长的趋势,并随着迭代次数的增长逐渐平稳,在训练结束时训练集的准确率达到91.24%,测试集的准确率达到88.67%。图4(b)表示交叉熵损失函数的变化过程,从图中曲线变化可以看出在10,000之前降幅较大,在迭代次数达到10,000步之后,损失值呈缓慢下降的趋势并逐渐趋于平稳,在训练结束时训练集的损失值为0.93,测试集的损失值为1.12。实验结果表明,本文模型的准确率和收敛效果较好,识别性能达到预期目标。
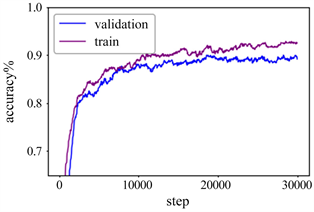 (a) 训练集和测试集的准确率
(a) 训练集和测试集的准确率 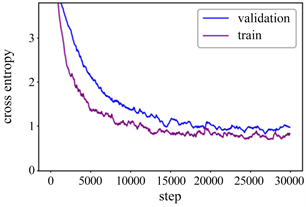 (b) 交叉熵
(b) 交叉熵
Figure 4. Experimental results of training set and test set
图4. 训练集和测试集的实验结果
为了更好的研究初始学习率、优化算法、迭代次数以及不同神经网络模型对农作物病害图像识别结果的影响,本文设计了三组对比试验。第一组对比试验为不同的初始学习率(0.001、0.005、0.01)和两组不同的学习率优化算法(SGD, Adam)组合,编号为1~6;第二组对比试验为7种不同的迭代次数,编号为7~13;第三组对比试验为6种不同卷积神经网络模型,编号为14~19。
4.2.1. 迁移学习学习率对模型性能的影响
第一组编号为1~6的实验方案分别使用SGD和Adam两种优化算法在三组不同的初始学习率下对本文模型进行参数优化试验,其中迭代步数均为30,000。实验结果如表1所示。

Table 1. Optimization algorithm and learning rate affect model performance
表1. 优化算法及学习率对模型性能影响
从表1中可以看出,相比SGD算法,Adam优化算法整体上的准确率较高,而SGD算法使训练时每次迭代的损失函数波动较大,参数有不稳定的危险。所以对本文的模型来说,Adam算法参数优化的效果更好。初始学习率的设置对模型的准确率影响较大。结合两种算法的比较,在初始学习率为0.01,优化算法为Adam算法时,模型的性能较好。
4.2.2. 不同迭代次数对模型性能的影响
第二组编号为7~13试验方案为七种不同的迭代次数,分别为5000、10,000、15,000、20,000、25,000、30,000、35,000步,其中均使用本文模型,且学习率优化算法使用Adam算法,初始学习率为0.01。实验结果如表2所示。
Table 2. The impact of training steps on model performance
表2. 迭代次数对模型性能影响
从表2可知,网络模型的收敛效果是随着迭代次数的变化而变化的。迭代次数越多的模型,其收敛效果越好。迭代次数为30,000时,准确率为91.24%;当迭代次数为35,000时,准确率为90.18%,反而降低。所以,当迭代次数达到一定程度时,模型的准确率也不再增加。甚至可能随之降低。由此可知,当模型已经达到良好的收敛效果时,迭代次数增加将不在提高模型的性能。
4.2.3. 不同网络模型对性能影响
第三组编号为14~19的试验方案为6种不同的网络模型,试验分别使用LeNet、AlexNet、VGG16、VGG19、GoogLeNet、本文模型(ResNet-50)本文模型这6种网络模型进行对比试验。其中学习率优化算法使用Adam算法,初始学习率为0.01,迭代步数为30,000。试验结果如表3所示。
Table 3. The impact of different network models on performance
表3. 不同网络模型对性能影响
由表3可以看出,LeNet模型的准确率最低,这是由于它的网络层数较浅,所以参数很少,训练时间最短,在图像分类问题里存在明显的劣势,导致模型无法在训练中学习到足够多的特征来是对病害图像进行识别。实验表明卷积神经网络的深度对于农作物病害图像识别的准确率有较大的影响。结构更深的模型对农作物病害图像特征提取的能力越好,对病害的识别能力越强。所以相比其他五种网络模型,本文模型ResNet-50拥有较高的识别性能。
5. 结论
本文将残差网络应用在农作物病害识别任务中,并使用迁移学习将在大数据集上训练得到的参数应用在本文的农作物病害数据集上对农作物病害进行识别,根据训练结果得到的具体参数上进行调参,该方法简单高效。证明了基于迁移学习的残差网络在农作物病害识别上具有良好的可用性和准确度。对试验的结果进行分析,试验表明本模型拥有较好地识别性能,并得到以下结论:
1) Adam算法可以自适应调节每次迭代学习率,这种稳定的迭代参数避免发生了过拟合,对于本文的模型,选取初始学习率为0.01和Adam算法时,模型效果较好。
2) 迭代次数的参数选择对模型性能影响较大。迭代次数过少时模型可能还未收敛,迭代次数过多时准确率反而降低。对于本文模型来讲,和迭代次数为30,000时效果最好。
3) 本文后期优化主要在两方面:一是增加可识别的农作物病害种类,扩充农作物病害图像数据集;二是搭建基于Android平台的农作物病害识别应用,在识别出病害的种类和病害程度的基础上增加病害的防治方法和防治建议,在一定程度上为农作物种植人员提供建议。