1. 引言
道路交通设施在保障行车与行人安全、充分发挥道路功能中扮演着不可或缺的角色。作为道路交通设施的一部分,交通标志通过其文字或符号传递交通指示信息,在保证道路交通安全、顺畅方面起着重要作用。交通标志从设立到运行阶段,需要进行合格验收及不间断的监测与维护,以防止因其标记模糊、损坏而导致的交通问题。针对上述问题,基于图像的高精度交通标志检测和分类的方法层出不穷,但是检测结果缺少几何信息,无法对交通标志进行精准的绝对定位,也不能对其设置的合理性进行监测与评价。因此,对交通标志的检测、分类和几何定位显得至关重要。
随着自动驾驶技术和驾驶辅助系统的发展,对于道路交通标志的识别技术要求也相应提高。以图像为数据源进行交通标志检测与分类方法众多,其中基于图像的颜色特征和形状特征 [1] 等低层的视觉特征传统方法由于天气、光照条件、图像形变等原因而导致不理想的识别结果。基于机器学习的方法(如随机森林 [2],Kd树 [3] 和支持向量机 [4] 等)则由于特征设计具有分类针对性,需要大量的实验测试,在时效性上低于预期。而近年来出现的卷积神经网络在交通标志的检测和分类方面表现出非常好的性能优势。用于识别交通标志的最常见的卷积神经网络方法包括:多尺度操作和深度智能可分卷积 [5]、改进的Lenet-5 [6]、多尺度Cap-Net [7] 和级联R-CNN [8]。为了提升算法对于交通标志尺寸变化的鲁棒性,Zhang等 [9] 通过双线性插值将符号大小调整为36 × 36图像;同时为了减少数据量,他们在交通标志识别网络架构的卷积层中使用了Gabor滤波器内核,在每个卷积层之后添加了一个归一化层。Chen等 [7] 认为道路上的交通标志在采集过程中会发生倾斜、旋转和模糊现象,因此提出了一种改进的可保留位姿等细节信息的胶囊网络用于交通标志识别,相比于卷积神经网络,胶囊网络在空间位置上具有更好的学习能力。上述深度学习算法处理能力取决于其训练程度,进而需要庞大的图像数据集 [10]。通常,训练阶段海量标记数据和大量神经元连接以及反复试验是一个耗时且劳动密集的过程。增加训练数据集的大小往往需要更大的存储空间,并且需要高端图形处理单元(Graphics Processing Unit, GPU),但提供如此大的数据集来识别符号较为困难,因此,所有交通标志检测和识别方法一般仅适用于某些国家的交通标志图像数据库 [11]。
以点云为数据源进行交通标志检测与分类方法由于点云处理的代价较图像大而少于基于图像的方法。Soilan等 [12] 利用点云的几何信息进行交通标志的分割与提取,结合影像对提取结果进行基于机器学习的分类,但是该方法具有场景依赖性且点云处理较复杂,对于大场景数据处理的效率不高。Balali等 [13] 基于手机拍摄的影像将方向梯度直方图(Histogram of Oriented Gradients, HOG)和颜色特征描述子输入支持向量机(Support Vector Machine, SVM)进行线下训练从而对交通标志进行检测和分类,最后利用运动恢复结构(Structure from Motion, SfM)重建得到交通标志的位置特征并进行可视化。杨凯等 [14] 提出一种利用全景影像光谱特征与形状特征定位,并利用机器学习算法SVM分类器分析纹理特征从而识别交通标志类型的方法,识别正确率93.27%,但对于发生遮挡的情况无法取得较好的结果。翁升霞等 [15] 和吴爽等 [16] 综合运用基于分割和特征识别以及基于反射强度的方法对点云中的交通标志进行检测但未进行语义信息的识别。刘力荣等 [17] 基于全景影像、激光点云和导航等多源数据,采用改进的卷积神经网络对目标进行检测,点云生成深度图以建立和全景影像的对应关系,从而将影像中检测到的目标位置映射到三维地理空间中实现交通标志的地理定位和矢量化。
上述方法在影像或点云中检测和识别交通标志的精度有限且效率不高,而成熟的深度学习目标检测方法可以在图像中准确高效地识别交通标志,本文借助YOLOv3网络对城市场景下全景影像中的交通标志进行检测和识别,并利用已有的配准融合工作实现交通标志点云快速定位和粗提取,在此基础上完成标志点云的精确提取工作。具体创新性如下:
1) 利用基于深度学习的二维图像目标检测方法,通过点云和影像的对应关系确定兴趣区域,减小交通标志牌搜索空间,提升了检测效率和精度;
2) 利用二维图像中的目标检测结果对因扫描仪视角限制和遮挡造成的缺失交通标志牌进行补全,提升交通标志牌提取的几何完整性。
2. 方法
本文提出了一种基于图像的纹理、颜色、语义辅助的交通标志提取方法。首先,基于YOLOv3网络目标检测对全景影像中的交通标志进行检测识别并输出相应的包围盒、类别信息;其次,经过预处理的点云通过标定参数文件和上述标牌检测结果建立对应关系,得到标牌在点云中的感兴趣区域(RegionofInterest, ROI),在ROI范围内对标牌候选点进行聚类和筛选得到粗提取结果,投影到二维平面找到标牌的几何中心,再对标牌点云进行精确提取,具体流程图见图1 (深色圆角矩形表示输入输出数据文件,浅色圆角矩形表示中间结果文件)。
2.1. 全景影像交通标志自动检测和识别
本文利用端到端的YOLOv3网络进行全景影像交通标志的自动检测和识别。YOLOv3借鉴了残差网络结构和多尺度特征提取,在保证实时性的同时,提升了总体检测精度,特别是小物体检测效果 [18]。全景影像在输入网络之前需要进行预处理,得到前进方向和路两侧的场景影像输入网络,得到交通标志检测框位置信息和类别信息等。检测结果的表达形式为:影像名,交通标牌类别标签,检测结果得分,检测框角点像素坐标。
本文探讨的中国主交通标志主要分为三个大类:警告标志(w*)、禁令标志(p*)和指示标志(i*),多为正三角形、圆形和矩形(具体尺寸和定义见表1)其中每一个交通标志有单独的标签,有的标志如限速标志是一个类别,包含多种速度,用“pl*”表示,“*”表示一个特定的数值,如限速50则表示为“pl50”。
2.2. 车载激光点云与全景影像初始融合
本文采用三维的车载激光点云和二维的全景影像数据,通过坐标系之间的转换关系将两者进行联系和统一也即融合(见图2)。该过程中涉及三种坐标系:世界坐标系
,相机坐标系
和像平面坐标系(u,v)。二者的融合原理见图2,首先将世界坐标系中的激光观测依据
转换到相机坐标系中式(1),再根据球面成像模型,即
,将相机中的点转换到像平面上,式(2)~(5)。
(1)
(2)
(3)
(4)
(5)
其中,R和T分别为旋转矩阵和平移向量。Φ和θ分别表示空间中某一点和相机坐标系中心的连线与Zc坐标轴的夹角、该连线在XcOcYc面上投影与Xc的夹角,imagewidth,imageheight表示对应全景影像的宽度和高度,其中imagewidth = 2*imageheight。
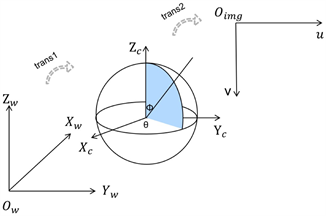
Figure 2. Illustration of the fusion model
图2. 融合模型
根据图2的
进行相机坐标系和世界坐标系的转换,同时,按照
进行相机坐标系和图像坐标系的转换。由上述转换关系可得最终三维点在图像上的二维坐标,即实现了初始融合,见图3。由于随着车载移动测量系统采集作业时间的增加,传感器之间由于振动会发生轻微移动,根据标定文件从世界坐标系到像素坐标系的转换关系仍然有误差存在。

Figure 3. Illustration of the fusion of point clouds and panoramic images
图3. 点云和全景影像的初始融合
2.3. 交通标志信息提取
结合2.1全景影像交通标志检测包围盒(见图4左下角)和2.2初始融合结果,建立ROI提取交通标志候选点云。对于ROI内(见图4红色棱锥状内)的点,先进行欧式聚类,利用深度即聚类中心相对于曝光点的距离筛选前景点作为交通标志候选点,然后基于强度滤波进一步精化该标牌候选点。将标牌候选点投影到平面进行模板匹配得到该交通标志的三维中心位置和所包含的准确候选点,即完成交通标志的定位。结合交通标志检测中心和语义信息,对真实交通标志点进行邻域插值和赋色得到具有精细语义和完整几何信息的交通标志。

Figure 4. Illustration of region of interest in point cloud
图4. 点云中ROI示意图
2.3.1. 感兴趣区域计算及局部投影
根据2.2构建的初始融合模型,以及2.1确定的交通标志包围盒和类别信息,计算该标志的中心像素坐标(uc,vc),在中心像素的基础上增加缓冲区以建立ROI窗口。
将候选标牌三维点由原始坐标系转换到该标牌二维检测结果源图像文件对应曝光点为视点的局部坐标系c-xyz下,相机坐标系的定义如下:以主成分分析(Principal Component Analysis, PCA)计算出来的法向作为z轴并指定朝曝光点方向为正,指定原始北东高坐标系的高方向作为x轴,与xoz面垂直的方向为第三轴,按照右手法则建立直角坐标系c-xyz。经过坐标转换后,ROI内的每个交通标志候选点均被转换到以该点云块质心c为原点的局部坐标系下,将ROI内所有点平面投影到xoy面上,并设置每单位的点距对应像素值
,得到二维投影图像。公式(6)和(7)将点云从世界坐标系转换到局部坐标系c-xyz,(8)和(9)将点云从局部坐标系投影到xoy平面上:
(6)
(7)
(8)
(9)
其中
是点在原始坐标系下的坐标,
是局部坐标系下的坐标,u和v为图像坐标系下的像素坐标。
为ROI候选点云PCA计算得到的法向量,
为指定方向即原始点云中交通标志的立面方向,
则是通过右手法则确定的第三个方向。所有候选点投影到像平面后,得到灰度图Imgi。
2.3.2. 基于能量优化的交通标志信息提取
根据现行关于城市道路交通标志的国家标准 [19],交通标志按其作用分为主标志和辅标志两大类,其中主标志包括禁令标志、警告标志、指示标志等。本文主要研究城市道路出现频率较多的交通标志,标志版面尺寸标准和设计速度关系见表1。

Table 1. The relationship between traffic sign size and road velocity
表1. 标志版面尺寸与设计速度的关系
根据表1中的标志版面尺寸与城市道路速度的关系制定相应交通标志尺寸模板
,首先,对投影Imgi图像进行膨胀处理,再提取该标牌的中心。本文采用模板匹配的方法实现交通标志中心检测。将Imgi栅格化为图像(见图5(a)),采用膨胀操作实现图像增强(见图5(b)),使用Laplacian边缘检测算法获得梯度图像(见图5(c)),使用构建的面状模板
作为卷积核与图像进行卷积操作,当模板刚好覆盖标牌时,强度值最大(见图5(d))。由于初始融合精度问题,相邻标牌缓冲区内点云存在混杂情况,仅使用总强度值难以准确检测中心。在此基础上,构建边缘模板
检测边缘梯度值,当边缘模板
和标牌投影边缘重叠最大即梯度值最大(见图5(e))表示模板范围最可能为标牌的边界,可以有效排除缓冲区范围内多个标牌点云混杂导致总强度值最大的错误情况。据此,本文设计包含强度和梯度两部分的能量函数,当能量函数最大时,得到最终的中心检测结果(见图5(f))。
(10)
第一项强度项中M1为第i个标牌增强图像与对应面状模板
的卷积结果,N1为
的总强度值,第二梯度项中M2为第i个标牌增强图像与对应边缘模板
的卷积结果,N2为
的总强度值,w1和w2分别是二者的权重且
,取能量函数最大值对应的中心作为中心检测结果。
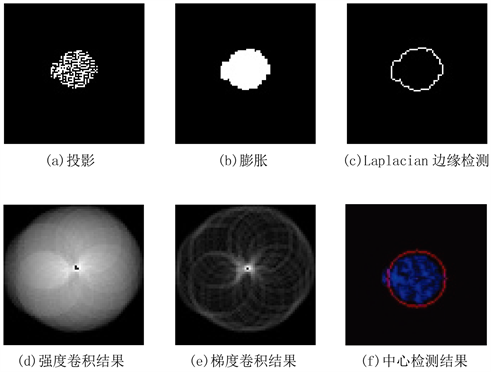
Figure 5. Illustration of 2D point cloud projection processing intermediate result
图5. 二维点云投影图像的中间处理结果
由于在点云分块预处理过程中对数据进行了下采样,故2.3.2小节提取模板内的标牌点云较稀疏且存在由于ROI划分误差导致的部分残缺,直接进行赋色效果不佳。本文为了提高点云中交通标志的观感,基于每个标牌的拟合中心结果及对应的真实交通标志点进行邻域插值得到相对完整和密集的标牌点云,利用相应的交通标志二维模板对每个物点进行颜色赋值,得到具有真实色彩的交通标志。
3. 实验结果与分析
3.1. 实验数据
实验所用设备为由Rigel VUX-1激光扫描系统、NOVATEL SPAN-FSAS定位定姿系统及iStreet高清全景采集系统组成的车载激光扫描系统。该设备最大观测距离为920 m,测距精度可达5 mm,单个相机像素3600万,拼接后像素7200万。实验所用数据为武汉市内两份不同场景的街景数据。其中一份是淮海路(图6) 3.0公里街道车载点云、对应的203张全景影像以及相机标定文件,第二份是建设大道3.2公里街道车载点云数据,对应211张全景影像。实验区域1是视野相对开阔的双车道城市路段,交通标志较单一;区域2场景包含双向四车道以及单向两车道、立交桥等较复杂的城市路段,具有类型丰富的交通标志。按照城市道路交通标志出现频率,本文主要讨论以下三种类型:警告标志(3.1%)、禁令标志(57.7%)和指示标志(39.2%)。
3.2. 参数设置
实验中数据处理参数取值见表2。对于2.3 ROI内的点进行聚类时,选择容差距离1 m,最小聚类点50和最大聚类点4000,聚类后筛选前景聚类结果作为标牌候选点,同时对于候选点的反射强度也进行限制,以剔除错误前景点。将标牌点云进行正投影的单位米转换成为100像素。

 (a) 淮海路
(a) 淮海路
 (b) 建设大道
(b) 建设大道
Figure 6. Illustration of experiment area and MLS point clouds data
图6. 实验区域及车载点云数据
3.3. 评价指标
由于车载激光扫描仪的安装位置和扫描角度限制,部分位于车辆顶部的悬臂式交通标志未被采集,所以本文在进行点云交通标志检测结果的时候对于未被采集的交通标志不计入真值统计。
对于实验使用的两个数据,本文利用精确度(Precision = TP/(TP + FP))和召回率(Recall = TP/(TP + FN))对点云交通标志提取结果进行质量评价,其中,TP、FP和FN分别为识别正确的目标个数、错误识别的目标个数和漏识别的目标个数。召回率越高,说明本方法对正样本的标注性能越好;精确度越高,说明本方法对负样本的区分能力越强。
3.4. 点云交通标志提取
本文利用YOLOv3对上述实验区域的全景影像进行交通标志识别,得到影像中每一个交通标志的包围盒、类别,识别统计结果如下所示。
Table 3. Result of panoramic images traffic sign recognition in test area
表3. 实验区域全景影像交通标志识别结果(个)
(漏识别:指本该识别却没有识别;误识别:本该是一种却识别成了另一种,或者把纹理特征类似的广告牌识别成交通标志)
根据对两份实验数据交通标志检测的统计结果,对YOLOv3目标检测算法精度进行分析。表3中数据1是城市双向六车道场景,道路宽敞,无高大树木遮挡,光照强度一致,视野开阔,对于出现在视野中的交通标志精确度和召回率较低,其中漏识别主要是因为视野中目标距离较远,误识别则因为有类似目标的广告牌和路向指示等30处,占误识别的76.9%。数据2主要为双向四车道,3个漏识别的标志是由于距离原因,18个误识别的主要是限高标志和警告标志,误检测的主要原因是距离较远和交通标志较小,在距离较近的影像中误识别率大大降低。
针对同一真实场景下的多帧影像,即对于同一标牌,存在远近多个检测结果,远距离使得影像较小,分辨率较低从而造成漏识别或者误识别,这是导致精确度和召回率低的根本原因。通过下文结合点云,对影像进行距离筛选,取较近的作为识别结果以提高目标检测精度,这也是本文影像结合点云的优势之一。具体参数值见表2。
由于在全景影像的某些区域存在像素级别的误差见图3,遂将该初始融合结果用作ROI建立的初始输入,在缓冲区内寻找对应的标牌点,进行滤除后投影到二维平面上寻找中心位置。基于几何中心和相应的模板尺寸参数对标牌点云进行插值,再将模板的语义信息赋值给加密后的交通标志点云,得到对应的交通标志点云信息提取结果(图7),该结果表明尽管城市道路场景复杂,光照条件不同,但依旧有效提取了各类别的交通标志。这说明该方法能够为大规模城市场景三维点云交通标志提取提供有效的解决方案。
 (a) 场景下交通标志点云
(a) 场景下交通标志点云  (b) 交通标志信息提取结果
(b) 交通标志信息提取结果
Figure 7. Illustration of original point clouds and traffic sign information extraction result
图7. 原始点云和交通标志信息提取结果
本文分别在武汉市的两个街道场景数据上试验本文提出的点云交通标志提取结果,验证了所提出方法具有较强的普适性。车载激光扫描仪的扫描时间窗口限制、角度限制、地物遮挡等缺点会造成点云缺失。对于部分缺失的标牌,本文可以利用模板匹配基于残缺的散点拟合出该标牌的中心位置,但是对于点云完全缺失的标牌,本文目前不做讨论。故本文以相机能够拍摄到且点云中存在的标牌作为真实值,对点云中标牌检测结果进行评价,对于完全缺失的点云不予统计。
Table 4. Precision on urban dataset (%)
表4. 城市场景实验精度(%)
为检测在本方法在点云中提取标牌的有效性,以手工标记的结果作为真值。实验结果见表4,提出的方法对道路交通标牌的平均提取精度达97.9%,其精度取决于全景影像标牌检测结果,将全景影像交通标牌检测识别结果映射到点云空间前,对相对于整张影像较小的检测框进行了过滤,从而大大降低了由于远距离和低分辨率造成的误识别率和漏提取率。
4. 结语
由于复杂场景中目标间的遮挡、气候条件的改变等因素影响,基于点云的交通标志牌提取是一项具有挑战性的工作,而基于全景影像提取标牌由于距离远和广告牌混杂造成的误识别问题也无法避免。本文通过点云和影像两者之间的映射关系,将两者优势互补,提升点云中交通标志的识别和定位正确率,并在此基础上以检测中心点进行精确提取,得到具有丰富语义信息和完整几何边界的交通标志,平均提取精度达97.9%,可辅助服务于基本设施施工质量验收、交通标志损坏危害评估、交通违章检测等城市管理方面。
基金项目
城市空间信息工程北京市重点实验室经费资助项目(融合车载点云与影像的城市道路高精度三维模型重建,基于机载广义点云的建筑物结构化重建),课题编号2020203,2020208。