1. 引言
我国开始步入老龄化社会,老年人数量众多。老人因为身体机能下降而容易发生摔倒的情况,如果不及时发现并进行救护,可能会导致一些严重的后果。
目前,检测摔倒的技术主要有两种方式:通过随身穿戴设备的传感器检测摔倒和通过摄像头的视频检测摔倒。通过穿戴设备检测的方法,需要人随身带着设备,例如手机、手环、腰带等。通过这些设备上的加速度计、陀螺仪等传感器采集的重心变化数据运用机器学习算法进行摔倒检测 [1]。该检测方法虽然简单有效,但对于一些老人来说,他们会忘记或者不喜欢佩戴这些设备。通过摄像头的视频图像检测的方法则不需要人随身携带设备,但因图像数据本身就相对较大,处理起来较慢,所以检测算法的计算量较大,检测速度也会较慢。如何优化关于视频图像摔倒检测方法的速度是非常值得研究的一个方向。
通过视频图像检测摔倒的方法有很多种,例如基于边缘轮廓 [2] [3]、基于密集光流 [4] [5]、基于人体姿态估计 [6] [7]、基于三维时空卷积网络(C3D) [8] [9] 等。其中,基于人体姿态估计的方法不止可以用于实现摔倒检测,还可以用于实现其他动作识别、动作分析、人机交互等算法,相对于其他方法来说扩展性更强。此外,该方法不需要考虑环境背景干扰的问题,检测准确率会比其他方法相对较高。但该方法因人体姿态估计算法本身的计算量较大,检测速度相比其他方法较慢,难以达到实时检测的效果,所以本文提出一种基于轻量级人体姿态估计的摔倒实时检测方法。
本文的主要贡献如下:
(1) 提出了一种基于目标检测的两阶段轻量级人体姿态估计模型来优化整体摔倒检测的速度;
(2) 通过消融实验对比分析该人体姿态估计模型各阶段的Loss与精度,验证该模型优化方法的有效性;
(3) 采用规模缩小后的图卷积网络来提高模型速度和摔倒识别的准确率;
(4) 在NTU-D-RGB-120和UR Fall Detection Dataset这两个数据集上进行实验,实验结果表明本文方法的优化有效。
2. 相关工作
基于人体姿态估计的摔倒检测方法主要分两个检测阶段。第一个阶段是人体关节点检测,即人体姿态估计。第二个阶段就是根据检测出来的关节点进行摔倒检测,即分类问题。无论第二阶段使用哪种方法,因为人体姿态估计涉及十几个关节点的识别与处理,整个模型的计算量大部分在人体姿态估计算法这块,所以为了达到实时效果,检测方法的优化重点在于人体姿态估计模型的性能。
2.1. 人体姿态估计
人体姿态估计算法的设计思路主要有两种:自顶向下和自底向上。自顶向下的方法分为两阶段,首先通过目标检测算法检测出人体检测框,然后再从人体检测框内检测关节点,代表算法有G-RMI [10]、AlphaPose [11]、CPN [12] 等。自底向上的方法也是分为两阶段,首先检测出图像中所有的关节点,然后再把全部关节点按一定的策略组合成每个人的姿态,代表算法有Openpose [13]、PifPaf [14]、DeeperCut [15] 等。一般自底向上的方法会比自顶向下的方法快。因为自底向上的方法只需要一次性识别出图像中所有的关节点,而自顶向下的方法检测关节点的次数随着图像中人数的增加而增加,所以一般轻量级的人体姿态估计会采用自底向上的方法。例如,Intel公司的Osokin在OpenPose的基础上,提出OpenPose的轻量级版本Lightweight OpenPose [16]。Osokin把Openpose的特征提取网络VGG-19换成MobileNet,并把5个修正预测的精炼阶段减少到1个。虽然该模型的精度下降了,但模型的速度却提高了不少。除此之外,Sekii [17] 也是使用自底向上的方法思路提出一种基于YOLO [18] 目标检测网格级别的轻量级人体姿态估计模型,把像素级别的热力图预测换成网格级别的目标检测来预测关节点,从而大幅度地提升关节点检测的速度。使用轻量级的人体姿态估计模型,因其关节点的检测精度降低,从而导致后续整个摔倒检测的判断结果会有一定的影响。
2.2. 摔倒检测
摔倒检测一般会使用长短期记忆网络(Long Short-Term Memory, LSTM) [19] [20]、支持向量机(Support Vector Machine, SVM) [2]、随机森林(Random Forest, RF)等方法,但这些方法不一定能学到区分关节点的一些运动特征,误判率较高,例如躺在床上、坐在地上、蹲下、摔倒等行为的区分。所以Yan等人 [21] 提出一种基于人体关节点的时空图卷积网络ST-GCN进行动作识别,该模型能更好地学习到一些隐藏的人体关节点运动的特征,泛化能力更强。所以本文方法中第二阶段的摔倒检测会采用比传统判别算法泛化能力更强的图卷积网络来进行摔倒判断,从而提高摔倒检测的准确率。
3. 方法设计
基于轻量级的人体姿态估计和图卷积的摔倒实时检测方法的整体算法流程如图1所示。首先把实时的视频提取关键帧,然后把提取的关键帧图片输入到人体姿态估计模型中进行关节点检测。同时,根据检测出来的关节点生成目标跟踪框来进行目标追踪。然后,把同个跟踪ID的人的带有时序的关节点坐标序列输入到时空图卷积网络中。时空图卷积网络利用每个动作带有时序的坐标序列的前后变化特征进行动作分类,从而进行摔倒检测警告。

Figure 1. Flow chart of the overall algorithm of fall detection
图1. 摔倒检测整体算法流程图
3.1. 轻量级人体姿态估计
为了整体算法模型能达到实时效果,需要将计算量较大的人体姿态估计模型进行优化,以达到实时检测的效果。本文参考文献 [13] [16] [17],提出一种基于目标检测的两阶段轻量级人体姿态估计模型Lightweight Pose Detection Network。如图2所示,该模型基于目标检测的思想,先把统一尺寸后的图像分为
个网格,然后用CNN网络来预测每个网格的候选的关节点和其连接的肢体,接着对候选框进行非极大值抑制(NMS)操作,最后利用Hungarian Algorithm [22] 算法生成每个人的姿态。

Figure 2. Flow chart of human pose estimation
图2. 人姿态估计算法流程图
其中,CNN网络有两个预测阶段,第一阶段网络主要预测细粒度的关节点,第二阶段网络是为了修正预测粗粒度的肢体连接,如图3所示。网络采用MobilenetV2 [23] 作为特征提取网络,然后经过两个3 × 3和一个1 × 1的卷积操作之后输出第一阶段局部特征的关节点预测结果与粗略的肢体连接预测结果。第二阶段为了修正属于全局特征的肢体连接预测,在特征网络输出的后面加入一层空洞卷积来增强感受野,并融合上一个阶段的关节点与肢体预测结果。特征融合之后,再经过两个3 × 3和一个1 × 1的卷积操作输出第二阶段修正的肢体预测结果。
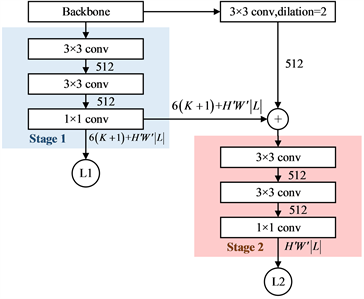
Figure 3. The network structure of the Lightweight Pose Detection Network
图3. Lightweight Pose Detection Network的网络结构
CNN网络第一阶段的输出为
个通道。其中,
为关节点预测信息,K为要预测的关节点种类,6为每个预测关节点所包含的信息数量。关节点预测包含的信息由公式(1)所示:
(1)
其中,
为第i个网格预测关节点k的概率;
为第i个网格预测关节点k的预测框与真实值的IoU;
为第i个网格预测关节点k的中心坐标相对于网格边界的距离;
为第i个网格预测关节点k的预测框的宽和高,如图4所示。
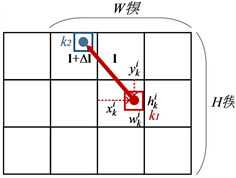
Figure 4. Schematic diagram of key points and limb prediction
图4. 关节点与肢体预测示意图
其次,
为肢体预测的信息,其中,
为肢体的种类,
为两个关节点连接的肢体范围,如图4所示。预测肢体连接的概率由公式(2)所示:
(2)
其中,
的范围为
。
CNN网络的第二阶段主要是为了修正粗粒度的肢体连接预测结果,所以网络输出的只有肢体预测的信息,输出通道为
。
整体网络的损失函数为:
(3)
(4)
(5)
其中,
表示该网格是否存在k关节点;
为每个损失的权重。
最后CNN网络最终输出的预测结果只使用第一阶段的关节点预测信息和第二阶段的肢体预测信息。
CNN网络输出关节点与肢体预测结果后,根据关节点的置信度
和肢体连接的置信度
,通过匈牙利算法(Hungarian Algorithm) [22] 用最大权重二分匹配来进行关节点连接,从而生成每个人的姿态,如图5所示。

Figure 5. Schematic diagram of connection join points
图5. 关节点连接示意图
3.2. 目标跟踪
虽然人体姿态估计采用的是自底向上的方法,没有生成人体检测框,但可以根据检测出来的关节点来生成目标追踪的检测框。遍历每个人的关节点坐标,找出最左、最右、最上和最下的坐标生成检测框。得出检测框后,用轻量级的Sort目标跟踪算法进行跟踪。Sort算法 [24] 利用上下帧中的框重合度IoU和框内关节点的距离作为评判是否为同一个ID的标准,进而存储不同ID的连续关节点序列。因本文的人体姿态估计模型速度约35 FPS,为了整体模型达到实时检测效果,设定暂存的阈值为30帧。然后使用卡尔曼滤波(Kalman filtering)对关节点形成的检测框以及运动规则的预测进行位置的评估优化,为生成下一帧追踪的特征提供更好的条件,从而形成稳定的追踪。最后,利用匈牙利算法(Hungarian Algorithm) [22] 将追踪到的ID对图像中的关节点进行分配,分别存储帧中提取的不同的关节点数据。
3.3. 图神经网络摔倒识别
时空图卷积网络通过学习摔倒动作的带有时序的关节点坐标序列的前后变化特征来对摔倒进行分类识别。参考ST-GCN [21] 模型,把每帧全部关节点作为数据流,输入到模拟关节点沿空间和时间维度的结构化信息的时空图神经网络中,图6为所构建的时空关节点图数据流示意图,橙色线连接为空间维度,蓝色线连接为时间维度。
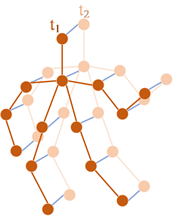
Figure 6. Spatio-temporal joint point graph data flow
图6. 时空关节点图数据流
网络结构如图7所示。首先,摔倒动作的特征对比其他动作会相对较简单,所以仅采用30帧的连续关节点数据作为网络的输入并对其位置特征进行归一化。然后,相应地把模型规模缩小,特征提取模块只使用6层:前2层为低维特征64通道数;中间2层为128通道数;后2层为高维特征256通道数。在特征模块中,ATT是注意力模块,负责针对不同层的GCN提取的语义特征的作用,GCN负责学习空间中相邻关节的特征,TCN负责学习时间维度中关节点变化的特征。最后,输出部分进行池化后使用FC全连接层输出结果。
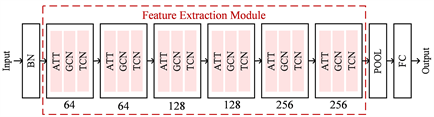
Figure 7. Spatio-temporal graph convolutional network
图7. 时空图卷积网络结构
4. 实验
本文实验环境使用Intel Core i7-6700 3.4 GHz处理器与GTX1060Ti 6 GB独立显卡的笔记本电脑作为测试设备,使用GTX1080Ti 11G独立显卡作为训练设备。
4.1. 实验数据与处理
人体姿态估计模型因为较轻量级,所以数据集采用MPII数据集。MPII数据集一共包含4 × 104个人,25000张图片。使用官方划分训练与验证数据集。
摔倒识别的图神经网络使用NTU-D-RGB-120和UR Fall Detection Dataset数据集。NTU-D-RGB-120数据集中截取A9 standing up、A8 sitting down、A43 falling、A59 walking towards each other和A60 walking apart from each other这5个动作分类样本作为数据集,在训练时需要手动筛选并分成多个30帧的可用数据集,去除Z坐标并换成1置信度。UR Fall Detection Dataset数据集中截取standing up 、sitdown、 falling、waliking 、standing、sitting、lying这7个动作分类样本作为数据集。其中,UR Fall Detection Dataset数据集是没有关节点的标签,所以使用精度较高的AlphaPose人体姿态估计模型来输出制作视频数据集里的关节点标签。另外,由于使用的是二维的人体关节点,头部、肩部、臀部和腿部的运动特征对比其他关节点更能作为摔倒的判断依据,因此在数据预处理中需要筛选这些关节点训练的置信度,直接置为1。过滤掉一些无效的视频数据后,整体图神经网络的数据集一共有2300个视频,其中训练集有1600个视频,验证集700个视频,每个类别平均分布。
4.2. 人体姿态估计分析
人体姿态估计模型训练输入的图片尺寸为384 × 384,批次大小为32,初始学习率设置为5 × 10−4,训练150轮,使用SDG随机梯度下降,冲量为0.9,权重衰减5 × 10−4。损失函数的loss权重设置为。采用迭代训练的方式进行训练,先用COCO数据集训练特征提取网络,然后加上第一阶段网络用MPII数据集继续训练,最后加上第二阶段网络用MPII数据集一起训练。训练完成后,模型与其他模型的精度与速度的对比,如图8和表1所示。
为验证第一个阶段输出关节点和肢体连接预测与第二个阶段输出肢体连接预测的模型优化方法是有效的,设计消融实验进行验证。消融实验为使用第一阶段直接输出关节点与肢体预测结果与第二阶段直接输出关节点与肢体预测作对比,使用训练了150轮之后损失函数中输出的
、
、
、
、
与mAP作为评价指标,如表2所示。
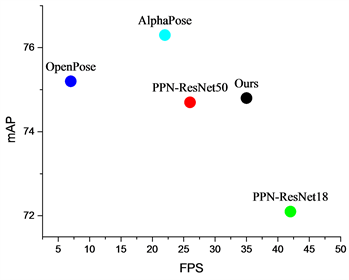
Figure 8. Comparison of accuracy and speed of different algorithms
图8. 不同算法精度与速度对比

Table 1. Comparison of accuracy and speed of different algorithms on the MPII data set
表1. MPII 数据集上不同算法精度与速度对比
Table 2. Analysis of ablation experiments
表2. 消融实验分析

Figure 9. Loss comparative analysis of ablation experiments
图9. 消融实验的Loss对比分析
从图9中,通过Loss损失函数的分析可以看出,第一阶段关节点相关的Loss比第二阶段小,细粒度的关节点预测更为准确;第二阶段肢体预测的Loss比第一阶段小,粗粒度的肢体预测更为准确。其次,从图10中,从两阶段网络模型输出的检测效果可以看出来,第一阶段的关节点预测会比第二阶段的更准确,第二阶段对肢体的预测会比第一阶段更加准确,所以验证了本文模型的优化方法有效。图11为优化后的人体姿态估计模型的检测效果。

Figure 10. The detection results of stage 1 and stage 2
图10. 第一和第二阶段检测效果

Figure 11. The detection results of the human pose estimatio
图11. 本文人体姿态估计模型的检测效果
4.3. 摔倒识别分析
摔倒识别的时空图卷积网络先使用NTU数据集数据进行预训练,然后使用UR数据集进行进一步训练,训练使用30帧连续的16个关节点数据,批大小为128,初始学习率为1 × 10−3,训练50轮,每10个 epoch衰减0.1,使用交叉熵损失函数以及Adam优化器。
本文采用4个评价指标,分别为精确度(Precision)、召回率(Recall)、准确率(Accuracy)和F1-measure综合性评价指标。首先,将实验样本分为四类:真正例TP、假正例FP、假反例FN和真反例TN。真正例 TP(True Position)表示正样本被正确地分类为正样本;假正例FP (False Position)表示负样本被错误地分类为正样本;假反例FN (False Negative)表示正样本被错误地分类为负样本;真反例TN (TrueNegative)表示负样本被正确地分类为负样本。
所以,精确度(Precision)表示正确地分类的摔倒样本占分类为摔倒样本的比例,如公式(6)所示。
(6)
召回率(Recall)表示模型正确地分类的摔倒样本占实际摔倒样本的比例,如公式(7)所示。
(7)
准确率(Accuracy)表示模型分类地正确(包含摔倒和非摔倒)的样本占所有样本的比例,如公式(8)所示。
(8)
F1-measure为分类常用的一个综合性评价指标,如公式(9)所示。
(9)
动作识别算法一般会使用300帧连续的关节点数据,但本文的人体姿态估计模型速度约35 FPS,为了整体模型达到实时检测效果,设置使用30帧的数据。实验结果如表3所示,设置使用30帧,整体模型的摔倒检测准确率并没有下降多少。其次,把网络的特征提模块改成6层,摔倒检测的准确率也没有下降多少。
Table 3. Analysis of the influence of the number of key frames and the number of feature extraction layers on detection
表3. 关键帧数和特征提取层数的设置对检测的影响分析
虽然使用了轻量级的人体姿态估计模型,但使用时空图卷积网络进行摔倒识别之后,整体模型的准确率并没有比使用精度较高的Alphapose人体姿态估计模型的准确率低多少。此外,对比使用SVM动作分类的方法,准确率却要高很多,如表4所示。本文方法的摔倒检测效果如图12所示。
Table 4. Comparison of accuracy and speed of fall detection
表4. 摔倒检测的准确率与速度对比

Figure 12. detection results of the fall detection
图12. 摔倒检测效果
5. 总结
为了使基于人体姿态估计的摔倒检测方法达到实时检测的效果,本文先把计算量较大的人体姿态估计模型进行优化,提出一种基于目标检测的两阶段轻量级人体姿态估计模型。同时,为了验证两阶段网络的优化方法有效,设计实验分析各阶段网络预测关节点和肢体的效果。然后,为了提高整体检测方法的准确率与检测速度,使用规模缩小后的时空图卷积网络来对关节点序列进行摔倒检测。经过实验,本文方法对比使用高精度的人体姿态估计模型,整体算法的摔倒检测准确率并没有下降很多,但速度却提升了不少。