1. 引言
随着机器学习和深度学习的不断发展,这些精度高、性能优异的复杂模型、应用场景贯穿我们生活的方方面面。数据导入到模型即可得到预测结果。我们无法知道模型是如何从数据当中捕获知识的。在一些涉及到生命健康、财产安全等较为重要的领域,我们需要对模型的决策进行解释,另外对错误结果的解释也可以反过来指导对模型的调整。因此除了模型的精度之外,模型的可解释性也非常重要。对可解释机器学习的研究有着重要的意义。
近年来,可解释机器学习在科研会议上成为关注热点,可解释机器学习主要是研究如何使黑盒子模型决策更加透明、可信,主要分为两大类:一是内在可解释机器学习,如逻辑回归;二是事后解释方法,如LIME [1]、SHAP [2] 等,通过事后辅助的归因解析去对复杂模型进行解释。本文主要在LIME的基础上进行改进,使用近年来新提出的可解释性加性模型去逼近复杂模型,而不是LIME内部使用的简单线性模型,进一步提升LIME解释复杂模型的能力。
2. 模型及原理介绍
2.1. 机器学习可解释性
机器学习可解释性是指人类对机器学习模型预测结果的理解程度大小。模型可解释性主要回答如何由输入数据得到预测结果的问题,是对输入特征和预测结果之间关系的定性理解。基本的可解释性模型主要有线性回归、浅层决策树、朴素贝叶斯、以及K近邻等。这些模型具备较强的可解释性,但令人觉得遗憾的是和复杂的机器学习模型如集成树模型以及神经网络模型相比,它们的学习能力非常有限,只能解决一些简单的问题。复杂的机器学习模型在许多目标任务上取得了良好的性能,但绝大多数是黑盒子模型,没法说明从输入到输出之间的因果关系。而在一些重要领域如金融、法律、医疗健康等,模型的可解释性非常重要,如风控借贷模型中,对一个被拒绝贷款的客户,我们有必要向其解释拒绝放贷的原因。再如机器学习模型在区分恶性肿瘤和不同类型的良性肿瘤方面是非常准确的,但是我们依然需要专家对诊断结果进行解释,解释为什么一个机器学习模型将某个患者的肿瘤归类为良性或恶性将有助于医生信任和使用机器学习模型来支持他们工作。此外有些场景下,模型的预测结果正确但原因却是错的,故为模型赋予较强的可解释性非常有必要。本小节将利用来自UCI数据库 [3] 的糖尿病人数据集Diabates和EBM [4] 模型简单阐述一下模型可解性的必要性。
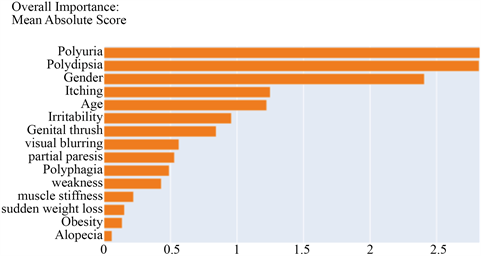
Figure 1. Feature importance of EBM
图1. EBM模型输出的全局特征重要性图

Figure 2. Feature age and label distribution
图2. 性别特征和标签分布图
EBM的预测结果达到0.969,但由图1可以看到,性别特征(gender)对最终决策的影响程度排第三,而实际上有关方面的调查显示在糖尿病患者中男女患病率之比接近1:1,因此模型预测结果正确度高但依赖的原因是不对的。对数据集的分布进一步查看发现,性别为女性的样本当中结果为阳性的占绝大多数,而性别为男性的样本中阳性阴性接近1:1 (如图2所示)。故模型决策依据错误是输入数据不合理造成的。因此可解释性是非常有必要的,它可以让我们知道模型做出相应决策的原因,并及时发现模型存在的问题,从而创造更加安全可靠的应用。
2.2. LIME模型
LIME由Marco Ribeiro等人 [1] 于2016年提出,是帮助我们解释复杂黑盒模型如何做出决策的一个工具。它是一种模型无关的机器学习可解释性方法,适用于解释所有模型包括神经网络、XGBoost、随机森林等。并且可应用于多种类型的数据,包括表格数据、文本数据、图像数据等。LIME主要有三个特点:
1) 只对模型进行局部解释,而不提供整体解释,及局部对每个样本进行解释;
2) 通过局部构建简单的可解释性模型进行预测去对重要特征进行解释;
3) 解释的是当前输入的特征和预测结果之间的关系,而不包含复杂模型训练当中产生的抽象特征。
对于要解释的黑盒模型,取要关注的样本点,在该样本点进行扰动生成新的样本,根据关注样本点的领域范围,选择在领域范围内的样本并用黑盒模型进行预测得到预测值。于是得到一个新的数据集,使用该数据集训练线性模型,得到黑盒模型较好的局部近似,利用可解释的模型可以知道黑盒模型局部的决策行为。
记
为要解释的样本,首先选出较为重要的d'维特征,x去掉不重要的分量之后变为
。
在x'附近扰动生成新的样本点z',新样本点构成新的数据集Z'。样本点添加去掉的特征分量之后恢复成样本
。定义
为扰动前后样本的相似度,其计算公式如下:
(1)
其中
为距离公式,不同的样本类型会有不同的定义,当为图像数据时通常为L2范数距离,当为文本数据时通常为余弦相似性。
记f为需要解释的复杂模型,g为简单模型,则衡量两个模型之间差异的目标函数如下所示:
(2)
其中
为模型g的复杂度,当g为线回归模型时,模型复杂度为权重系数不为0的个数。
LIME算法流程如下表1所示:
2.3. EBM
EBM于2015年被Rich Caruana等人 [4] 提出,EBM被应用到医学领域并取得不错的效果。EBM基于广义加性模型GAMs (Generalized additive models)而提出的模型。广义加性模型具有很好的可解释性。像逻辑回归这样的广义线性模型GLMs (Generalized linear models)实际上是广义加性模型的一种特殊形式记
为样本的第j个特征,其中特征个数为p,则广义加性模型的标准形式为:
(3)
其中g是连接函数,
。
EBM在广义加性模型的基础上加入了两个特征的交互项,一种自动搜索选取交叉项方式由Yin Lou等人提出 [5],EBM的公式如下所示:
(4)
其中
为岭函数(shape function),
为交叉项岭函数,对于回归问题EBM使用回归样条(Regression Splines)作为岭函数,对于分类问题EBM采用二叉树或者集成二叉树作为岭函数。最后对每个特征以及筛选出的交叉项对应的岭函数进行线性组合得到预测结果,具体细节以及迭代求解过程请参考文献 [5]。值得注意的是本文将采用不含交叉项的EBM模型,不含交叉项的EBM模型具有更强的可解释性。是一种传统的广义加性模型。
2.4. GAMINET
GAMINET由香港大学教授张爱军于2020年提出 [6],GAMINET和EBM的原理架构非常相似,最大的区别是EBM的岭函数采用二叉树或者集成二叉树生成,而GAMINET则采用全连接神经网络,GAMINET每个特征生成一个子网络或者两个特征交叉生成一个子网络,每个子网络对应一个输出,即为岭函数。最后对岭函数加上一层全连接层,基于全连接层得到最终的输出结果。GAMINET的模型表达式为:
(5)
其中
为主效应(main effect)构成的集合,主效应即单个特征对应的岭函数,
为交互效应构成的集合,交互效应即为交叉项对应的岭函数。训练时,GAMINET将每个特征输入子网络进行训练,单个特征子网络模块训练完成后,再将残差作为响应变量继续对交叉项子网络模块进行训练。同样,为具备更强的可解释性,本文将采用的不含交叉项的GAMINET模型。
3. LIME模型的改进
LIME [1] 算法当中采用线性模型对关注样本附近随机扰动生成的样本进行拟合,局部逼近复杂模型在关注样本附近的决策行为。我们都知道,线性模型解释性强,但学习能力非常有限,故本文将使用不含交叉项的EBM [4] 和GAMINET [6] 去近似复杂模型在关注样本附近的行为。不含交叉项的EBM模型和GAMINET模型属于广义加性模型,具有良好的可解释性,模型输出的特征重要性可与线性模型一般视为每个特征对最终决策的影响程度。由于EBM、GAMINET对单个特征通过集成树或者神经网络进行加工,相比线性回归具备更强的特征学习能力。如当响应变量和特征分量之间的关系为
时,对于线性回归模型是没有办法学习到这样的关系,而EBM、GAMINET则可通过集成树或者神经网络将特征分量进行升华,如:
再通过最后的线性层将升华后的特征进行组合得到响应变量和特征分量之间的关系。由于最后一层结构是线性的,故我们很容易计算每个特征分量对决策结果的贡献程度,因此它们具有非常好的可解释性的同时精度也提高了。
3.1. 数据集介绍
本文将采用UCI数据库提供的Adult数据集 [7] 进行实验,Adult数据集是从美国1994年人口普查数据库抽取而来,用于预测居民收入是否超过50 k,标签为是否超过50 k,特征变量主要包含有性别、年龄、职业、教育程度、婚姻状况、种族等。一共有48,842条数据。
3.2. 模型对比
现选择XGBoost为复杂模型, LIME模型算法内部利用的是线性模型(Ridge回归、逻辑回归)去局部近似复杂模型的局部行为,本小节将在LIME模型算法的框架下,用EBM以及GAMINET去逼近XGBoost在关注样本点附近的行为,比较EBM、GAMINE和线性回归模型对复杂模型的逼近复杂模型的能力。使用XGBoost对Adult数据集进行拟合,在训练集上的准确率为0.883,AUC为0.941,在测试集上准确率为0.883,AUC为0.923。
对某个关注样本点,分别采用10个不同的随机数种子在该样本点附近扰动生成10个数据集,每次生成5000个样本,并分别用线性模型、EBM以及GAMINET进行拟合,结果如下表2所示,其中括号左边是模型在生成的数据集上的AUC值,右边是准确率。

Table 2. Performance of three models on randomly generated datasets near certain sample (XGBoost)
表2. 三种模型在关注样本附近随机生成的数据集上的拟合结果(XGBoost)
同样也是在LIME模型算法的框架下用不含交叉项的GAMINET去局部近似全连接神经网络在关注样本点附近的行为,并和EBM以及线性模型进行比较。注意到两个复杂模型的数据处理方式略不相同,故图中显示的特征值不一样,且复杂模型决策依据也有所出入。全连接神经网络在训练集上的AUC为0.906,准确率为0.848,在测试集上的AUC为0.891,准确率为0.840,三种模型在扰动生成的数据集上的结果如表3所示。
Table 3. Performance of three models on randomly generated datasets near certain sample (neural network)
表3. 三种模型在关注样本附近随机生成的数据集上的拟合结果(全连接神经网络)
可以看到,对两种复杂模型(XGBoost和全连接神经网络),整体上EBM和GAMINET的效果都比线性模型要好。对于XGBoost,EBM的拟合效果要比GAMINET要好一些,而对于全连接网络,GAMINET拟合的效果比EBM更佳。这可能是由于EBM是基于树的,更加适合逼近复杂树模型,而GAMINET是基于神经网络的,和复杂神经网络的决策逻辑更相契合一些,因此拟合神经网络的效果更好。
接下来将在LIME的算法框架下,基于EBM拟合复杂模型XGBoost在关注样本点附近的行为并进行解释决策依据,同样,本文将基于GAMINET去拟合全连接网络在关注样本点附近的行为以及寻找复杂模型局部的决策原由。关注样本点的特征取值在局部解释图中有呈现。
3.3. 基于EBM的LIME模型改进算法
本小节用XGBoost在Adult数据集上训练一个预测模型,并将选择一个关注样本点,分别用原始的LIME [1] 模型以及基于EBM [4] 的改进LIME模型对XGBoost在该关注样本点附近的行为进行解释。复杂模型在训练集和测试集上的AUC分别为0.941,0.923,准确率分别为0.883,0.873,图3和图4分别为原LIME
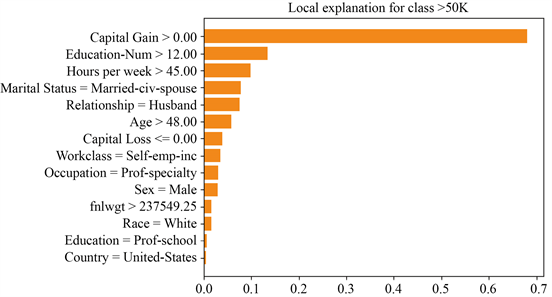
Figure 3. Feature importance of LIME globally
图3. LIME输出的全局特征重要性图

Figure 4. Feature importance of improved LIME based on EBM globally
图4. 基于EBM的改进LIME模型输出的全局特征重要性图
模型和基于EBM改进后的LIME模型在关注样本点附近生成的数据集上整体特征重要性图(绝对值),可以看到两个模型均认为Capital Gain、Education-Num以及Hours per week是最重要的特征,并且均是和标签>50 k是正相关的,关注样本点在这三个特征附近取值均较大,因此被预测为>50 k,当我们取在这三个特征上取值相对较小的样本进行研究时,绝大多数样本被复杂模型预测为≤50 k,故不管是原始LIME模型还是基于EBM的改进LIME模型都可以让我们看到特征和复杂模型预测结果之间的关系,探索其决策依据。
进一步可以看到EBM认为Relationship比Marital Status更加重要,即前者比后者更加影响复杂模型的决策行为,而LIME则反之。我们取Relationship、Marital Status这两个特征列联合标签放入一个逻辑回归模型中训练,从图5可以看到逻辑回归输出的Relationship特征重要性绝对值要比Marital Status要大。基于EBM的LIME模型的解释性更加可靠,这是因为EBM的学习能力比逻辑回归要强。
此外两个模型输出的局部特征重要性图提供了关注样本点的每个特征取值对标签的影响程度。如图6和图7所示。

Figure 5. Feature comparison: Relationship VS. Marital Status
图5. 特征Relationship和Marital Status比较图

Figure 6. Feature importance of LIME locally
图6. LIME输出的局部特征重要性图

Figure 7. Feature importance of improved LIME based on EBM locally
图7. 基于EBM的改进LIME模型输出的局部特征重要性图
3.4. 基于GAMINET的LIME模型改进算法
本小节用全连接神经网络在Adult数据集上训练一个预测模型,选择和上一小节相同的关注样本点,分别基于LIME [1] 模型以及基于GAMINET [6] 的改进LIME模型对复杂模型在关注样本点附近的行为进行解释,寻找决策依据。复杂模型在训练集、测试集上的AUC分别为0.907,0.893,准确率分别为0.849,0.843。从图8和图9可以看到两个模型特征重要性排前三的特征均为capital_gain、education_num、maritial_status,原始LIME模型认为capital_loss比hours_per_week更加重要,而基于GAMINET的改进模型则反之。同样我们取capital_loss、hours_per_week这两列特征以及标签列放入逻辑回归中训练,得到如图10所示的逻辑回归特征重要性图。可以看到hours_per_week相对capital_loss来说特征重要性绝对值更大。基于GAMINET的LIME改进模型能够更加准确地逼近复杂模型的局部行为。图11为GAMINET每个子网络的输入到输出的函数曲线图,当特征为连续特征时是一条光滑曲线,若为离散特征则为柱形图。GAMINET从原始输入到最后的输出都是公开透明的,是结构上可解释性模型,且它不是简单的线性模型,具有更强的学习能力。
此外两个模型输出的局部特征重要性图提供了关注样本点的每个特征取值对标签的影响程度。如图12和图13所示。

Figure 8. Feature importance of LIME globally
图8. LIME输出的全局特征重要性图
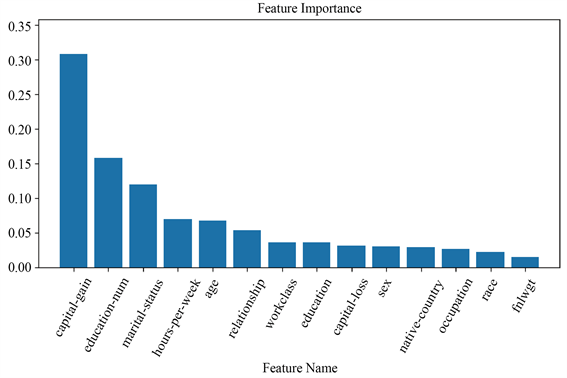
Figure 9. Feature importance of improved LIME based on GAMINET globally
图9. 基于GAMINET的改进LIME模型输出的全局特征重要性图

Figure 10. Feature comparison: Hours per week VS. Capital Loss
图10. 特征Hours per week和Capital Loss比较图
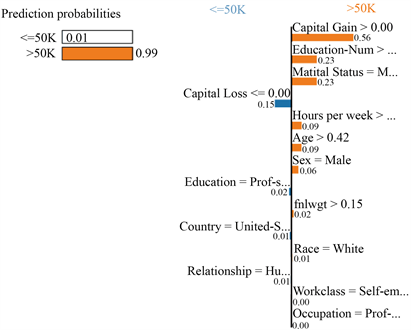
Figure 12. Feature importance of LIME locally
图12. LIME输出的局部特征重要性图
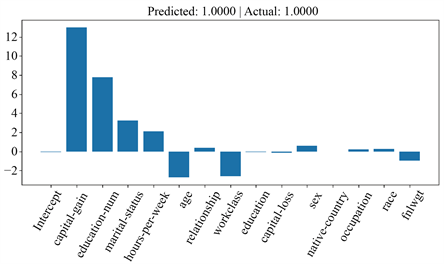
Figure 13. Feature importance of improved LIME based on GAMINET locally
图13. 基于GAMINET的改进LIME模型输出的局部特征重要性图
4. 评价与展望
本文提出了基于机器可解释性方法LIME [1] 的改进算法,LIME内部采用的是线性模型去逼近复杂模型的局部行为,线性模型结构简单,可解释性强但学习能力弱,拟合效果一般。而本文采用的是较新提出的EBM [4] 模型和GAMINET [6] 模型,两种模型均为结构上可解释性模型,具备较强学习能力的同时也具备良好的可解释性,进一步提升了LIME对复杂模型的解释能力。并且经实验发现,基于EBM的改进LIME模型更适合去解释复杂树模型,而基于GAMINET的改进LIME模型则更适合解释神经网络模型。LIME原理简单,适用范围广,可以解释所有的黑盒模型,但LIME在关注点附近进行扰动生成新样本时需要确定邻域范围,不同的邻域范围得到的局部可解释性模型相差可能很大,并且LIME在生成新样本点时,新样本的每个特征分量是基于整个数据集的每列特征单独的分布生成的,没有考虑到特征的交叉性,导致可能生成不大可能出现的样本点,因此还需进一步改进该方法。