1. 概述
近年来,大量的数字视频被生产并应用于教育、娱乐、监视、信息存档等领域,数字视频已经成为人们视觉信息的最重要来源之一。大量的视频数据增加了人们对于数字视频浏览、筛选和存储的压力。依照传统的方法,用户只能通过视频标题、简介、标签等有限的外部资源信息间接了解视频内容,而对视频本身的内容没有一个直观的理解。视频摘要生成技术在提高用户对视频内容信息的获取上发挥了重要作用,该技术通过分析一定长度的视频数据中信息的稀疏性,从原始视频数据中选取具有代表性的、有意义的部分,将它们以某种方式组合并生成紧凑的、用户可读的缩略数据,使用户在更短的时间内快速理解视频 [1]。
根据生成摘要过程是否需要标注数据,生成视频摘要的研究可以分为无监督学习的生成方法和有监督学习的生成方法。无监督学习生成方法通过自定义直观的标准来挑选关键帧或关键镜头,并组合成相应的视频摘要;有监督学习生成方法从人工创建的摘要中学习特征信息,拟合人类对输入视频进行总结的方式。在实际应用中,这些模型表现出不错的效果,但是它们仍然存在一些不可忽视的问题:一些研究者为了提高模型的性能,不断增加模型的复杂度,使得模型的计算量大大增加,在训练数据不足的情况下难以达到理想的收敛效果;并且大多数模型对冗余帧的判定和处理的效果并不理想。
针对上述存在的问题,本文提出融合GRU和非极大值抑制的视频摘要生成模型。所提模型将视频数据看成以帧为单位的序列数据,首先用GoogLeNet网络提取每一帧的图片特征,其次将帧特征序列传入包含GRU和注意力机制的序列到序列(Sequence-to-Sequence, Seq2Seq)模型中,提取帧级重要性得分,最后通过基于非极大值抑制(Non-Maximum Suppression, NMS)的算法去除冗余帧并生成关键帧序列和关键镜头序列。
本文的研究主要有如下三点贡献:其一,提出一种融入GRU和注意力机制的Seq2Seq模型,使模型在处理视频帧序列时能最大程度保留帧与帧之间的长距离影响因素,同时减少模型的参数,提高反向传播时的收敛速度;其二,提出基于非极大值抑制的算法,有效地处理冗余帧,获得更具代表性的视频摘要;其三,在SumMe、TVSum和VSUMM三种数据集中验证了模型的有效性。
本文后面的组织架构为:第1节介绍与视频摘要相关的研究工作,第2节介绍所提的融合GRU和非极大值抑制的视频摘要生成模型及算法原理,第3节进行实验对比和分析,第4节进行工作总结与展望。
2. 相关工作
早期的视频摘要方法大多基于无监督学习方法 [2] [3] [4] [5] [6],通过外观或运动特征等底层视觉信息来提取视频摘要,其中聚类算法的使用最为广泛。对于基于无监督聚类的方法,基本思想是通过将相似的帧或镜头聚集在一起,然后在每个聚类中选取特定数量的帧或镜头进行组合生成摘要。该方法关键点在于模型需要选择可以判断帧相似的特征(例如,颜色分布,亮度,运动矢量),进而建立可用于测量相似性的不同标准。聚类算法生成摘要通常需要花费较长时间,文献 [6] 中提到,通过聚类算法生成摘要所花费的时间大约是原始视频时长的数倍。除此之外,由于聚类算法通常只关注视频帧的重要性程度,容易忽略掉视频的时域信息对摘要生成的影响。
随着深度神经网络的不断发展,有监督学习的视频摘要方法开始得到关注。有监督的视频摘要方法能准确地捕获视频帧的选择标准,并输出与人类对视频内容的语义理解更加一致的帧子集。在有监督学习方向上,文献 [7] [8] [9] [10] 认为同类别的视频数据具有相似的上下文结构,故利用模型从相关的照片或从属于特定事件类别的视频中学习特征,最终得到对特定领域更有表征性的摘要;文献 [11] [12] 利用原始视频和编辑过的视频进行相对排名,省去了标记数据的繁琐工作。
近年来,基于Seq2Seq模型的视频摘要生成模型 [13] - [18] 受到研究者的广泛关注。文献 [14] 使用融入长短期记忆(Long Short-Term Memory, LSTM)单元的Seq2Seq模型自动生成帧级重要性得分,并通过交叉熵和行列式点过程(Determinantal Point Process, DPP)筛选关键帧。文献 [15] 在上述Seq2Seq模型中引入视觉注意力机制,提高历史解码信息的利用率,并使用背包算法筛选关键帧。与上述方法不同,本文在Seq2Seq模型中使用GRU代替LSTM单元,提高训练效率,使模型能达到更好的收敛效果,同时使用非极大值抑制筛选关键帧,达到更好的去冗余效果。
3. 融合GRU和非极大值抑制的视频摘要生成模型
本文所提模型包括特征提取模块、重要性得分生成模块和摘要生成模块,其整体结构如图1所示。特征提取模块负责对输入的原始视频下采样和特征提取,将获得的视频帧序列输出到下一模块;重要性得分生成模块负责分析并捕捉视频帧序列的上下文信息,生成帧级重要性得分;摘要生成模块根据重要性得分结果,使用非极大值抑制去除冗余帧,生成相应的关键帧序列和关键镜头序列。
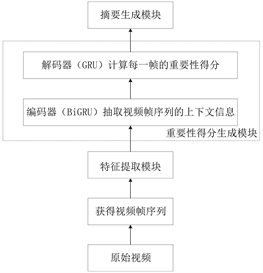
Figure 1. Model structure diagram of video summarization integrating GRU and non-maximum suppression
图1. 融合GRU和非极大值抑制的视频摘要生成模型结构图
3.1. 特征提取模块
本文将GoogLeNet [19] 作为帧特征提取器,负责提取视频数据每一帧的图片特征。与其他卷积神经网络不同,GoogLeNet在网络层之间添加了多个inception块,一定程度上减少网络层数,在相同的计算量下具有更好的分类性能。GoogLeNet中的inception结构如图2所示,通过引入Inception块,GoogLeNet在相同尺寸的感受野中能叠加更多的卷积,提取到更丰富的帧特征;同时Inception中的多个1 × 1卷积层能有效降低模型的维度,防止训练阶段出现过拟合。

Figure 2. Structure diagram of inception
图2. Inception结构图
由于所用数据集中的部分视频数据包含较多冗余帧,相近的视频帧具有相近的特征,故本文首先需要对原始视频帧序列进行下采样。根据时间顺序生成原始视频的视频帧序列,记为V,则下采样后的视频帧序列
由V每30帧中随机抽取2帧组成。然后将
输入到经过预训练的GoogLeNet中,获得帧级图片特征序列,记为
,其中
表示下采样后第i帧的特征向量,n表示下采样后的总帧数。
3.2. 基于GRU的Seq2Seq模型计算重要性得分
本文将获取帧级重要性得分任务看成机器翻译任务,将获取帧级重要性得分过程按照机器翻译过程进行处理。获取帧级重要性得分模块的输入是视频帧特征序列
,其中
表示第i帧的图片特征向量。Z由上一模块的GoogleNet网络提取获得。获取帧级重要性得分模块的输出是重要性得分序列
,其中
表示第i帧的重要性得分。
即便Seq2Seq模型善于处理序列数据,它仍然存在一些弊端。Seq2Seq模型的编码器将输入编码为固定大小状态向量的过程是一个信息有损压缩的过程,信息量越大,该转化向量的过程对信息的损失就越大;同时Seq2Seq模型中的循环神经网络(Recurrent Neural Network, RNN)在处理过长的序列时,若对当前状态有用的信息距当前状态的时间间隔较大,这些信息记录将变得模糊,导致在训练时出现梯度弥散问题且计算效率低下;除此之外,模型连接编码器和解码器的模块组件只有一个固定大小的状态向量,导致解码器无法直接去关注到输入信息的更多细节。
针对以上提到的问题,本文在下面分别对编码器和解码器做出相应的改进。
3.2.1. 编码器改进:双向GRU网络提取上下文信息
本文采用双向GRU网络提取视频帧的上下文信息。GRU (Gate Recurrent Unit) [20] 作为一种循环神经网络的变体结构,通过控制重置门(Reset Gate)和更新门(Update Gate)来处理当前节点的上一状态信息(即上一视频帧的有效信息)和上一层输入数据(即当前视频帧的图片特征),并获得当前节点的状态信息(即当前视频帧的有效信息)。GRU网络可以解决RNN中存在的长期记忆模糊问题和反向传播中的梯度弥散问题;同时相较于包含3个门信息的LSTM单元,GRU具有更少的训练参数,在保证精度的情况下优化了训练中反向传播的计算效率。
在本文的编码器中,每个GRU的重置门有针对性地记忆当前视频帧图片特征的信息,更新门则调节上一视频帧有效信息的保留比例,最终输出当前视频帧的有效信息。图3展示了单个GRU的内部结构。图中
表示第
帧的有效信息,
表示第t帧的图片特征,
和
表示第t帧的有效信息,r和u分别表示重置门信息和更新门信息。
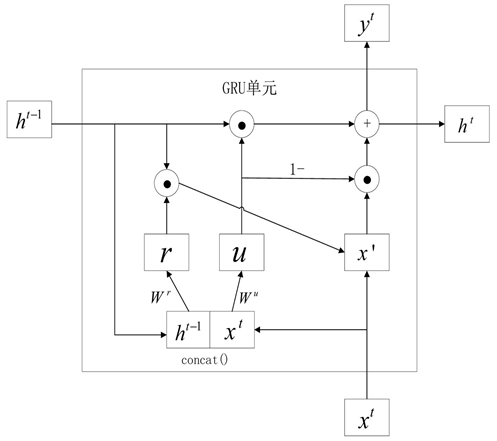
Figure 3. The structure of GRU (
represents the dot product operation,
represents the addition operation)
图3. GRU结构(
表示点乘操作,
表示相加操作)
GRU的工作过程分为三步:首先,根据第t帧的图片特征
和第
帧的有效信息
来获取重置门信息r和更新门信息u:
(1)
(2)
其中
表示将两个向量或矩阵进行拼接,
和
是需要训练的权重参数,
表示使用sigmoid函数归一化。然后,使用重置门r筛选出上一视频帧对当前帧的有用数据
:
(3)
其中
表示将第
帧的有效信息
和所得重置门信息r进行点乘,
表示通过双曲正切函数将结果约束在(−1, 1)之间。最后,使用所得更新门信息u计算第t帧的有效信息
:
(4)
(5)
其中
进行遗忘操作,将第
帧的信息选择性遗忘,
进行记忆操作,将第t帧的图片特征选择性记忆。最终得到的
用于计算第
帧的有效信息,
作为当前GRU的输出。
由公式(4)可以看出,每个GRU包含的其他帧的信息均以加算的形式保留在当前状态中,因此在反向传播时,每一个过去状态的相应影响权重不会趋向于0,避免梯度弥散问题。
针对视频帧序列的特性,本文不仅要考虑当前帧之前的视频帧对当前帧的影响,也要考虑当前帧之后的视频帧对当前帧的影响,故采用双向GRU网络作为获取帧级重要性得分模块的编码器。双向GRU网络包括forward层和backward层。经过特征提取的视频帧序列输入到双向GRU网络后,forward层从
到
正向计算并保存当前帧之前各帧对当前帧的影响信息,backward层从
到
反向计算并保存当前帧之后各帧对当前帧的影响信息。最后在每个时刻结合forward层和backward层的相应时刻输出的结果得到的当前帧最终的有效信息。在编码器中,通过GRU计算第t帧的有效信息
:
(6)
(7)
(8)
(9)
(10)
其中
表示根据第t帧的图片特征和第
帧的有效信息,经过使用公式(1)-(5)的过程计算获得第t帧的正向(或反向)有效信息。
和
表示forward层中第t帧的正向有效信息,
和
则表示backward层中第t帧的反向有效信息,通过公式(10)对两层的输出加权求和,并使用sigmoid函数对结果进行归一化,获得第t帧的最终有效信息
。
3.2.2. 解码器改进:结合注意力机制获得重要性得分
为了解决有损压缩的中间向量难以存储足够信息的问题,本文在解码器部分结合注意力机制对视频帧信息进行解码。
注意力机制 [21] 通过借鉴人类视觉注意力的工作原理,在序列中筛选出重要性更高的部分作为当前节点输出的判断依据。在本文中,注意力机制模块首先通过快速扫描全局视频帧,获得需要重点关注的几个目标帧,然后对上述目标帧投入更多注意力资源,以获取更多对当前帧的重要性评判的信息,同时抑制非目标帧的无用信息。除了加入注意力机制之外,本文在解码器部分同样采用GRU网络,进一步减少参数的数量,提高计算效率。
本文的解码器解码过程如图4所示。根据在编码器中获得的每一帧的有效信息
,结合解码器每个时刻的状态
,可以求得第j时刻的注意力信息
。
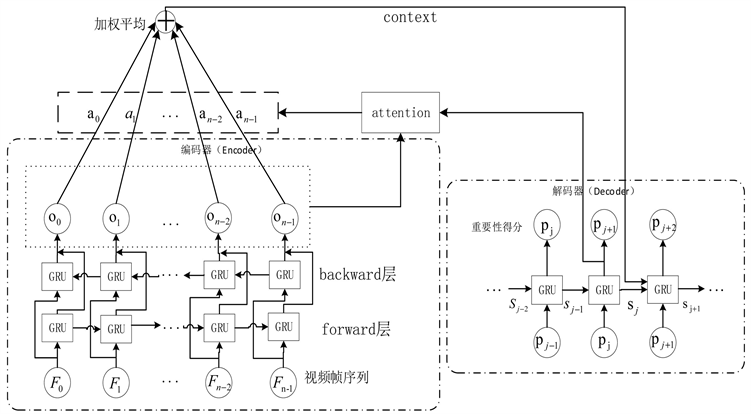
Figure 4. The process of obtaining the importance score of video frames combined with the GRU network and the attention mechanism
图4. 结合GRU网络和注意力机制的获取视频帧重要性得分过程
(11)
(12)
其中
表示其他每一帧i对第j帧的注意力权重,
是相关度函数,衡量当前帧与解码器状态的相关度,本文采用的相关度函数是:
(13)
其中
是模型参数。
反映了对当前视频帧最相关的信息。进一步地,利用所得
可以计算出解码器
时刻的状态
以及
时刻的重要性得分
:
(14)
(15)
通过将j时刻的状态
和第j帧的注意力信息
拼接后作为
时刻的输入,解码器可以在解码的每一步查询最相关的原视频有效信息,避免中间向量信息不足问题。
3.3. 基于非极大值抑制生成视频摘要
现有方法通常使用DPP算法或动态规划的方法生成视频摘要,两者所选取的视频摘要均具有不错的概括能力,但是这些方法主要通过重要性得分的高低筛选关键帧,而没有关注所选取的关键帧之间的特征相似程度,因此在生成的视频摘要中仍存在一定程度的冗余。在视频摘要生成模块中,与现有模型不同,本文将去除冗余帧作为主要任务,基于非极大值抑制的思想设计算法方案,在筛选关键帧时,不仅考虑重要性得分更高的视频帧,同时根据帧与帧之间的图片相似度,过滤与已选视频帧相似度高于阈值的视频帧,使在关键帧序列中重要性得分总和尽可能高的前提下,保证关键帧之间的相似度尽可能低。
在生成关键帧序列的步骤中,按照算法1,遍历上一模块获得的帧级重要性得分序列,采用基于非极大值抑制的算法去除冗余帧,生成关键帧序列。
算法1的第2行将帧级重要性得分序列P重新排序,使遍历序列P时优先筛选得分更高的帧。在遍历序列P过程中,5~7行限制关键帧序列K的长度,保证K的长度不大于m;9~14行计算当前帧
与关键帧序列K中每一帧之间的相似度并与阈值
比较,第10行中
表示根据
和
的特征向量采用余弦距离计算相似度;若上一步中与K中每一个关键帧的相似度均低于
,则将
加入K中;20行将K按时间顺序重新排列,作为所提模型的静态视频摘要。
进一步地,根据上一模块得到的关键帧序列K和帧级重要性得分P,按照算法2,筛选出关键帧对应的关键镜头,并根据当前关键镜头序列的总时长情况,决定删减或扩充镜头时长。与文献 [14] 和文献 [15] 相同,本文采用基于核的时域分割(kernel temporal segmentation,KTS) [9] 镜头检测算法获取镜头序列P',并且将最后生成的关键镜头序列总时长n限定在原视频长度的15%左右。
算法2的5~10行通过遍历关键帧序列K,将所有关键帧对应的镜头加入关键镜头序列S中;12~23行通过删减K中不含关键帧的镜头以解决K时长过长的情况;25~35行通过贪心算法补充镜头以解决K时长不足的情况,其中第26行的镜头级重要性得分由镜头中所有帧得分相加获得。
Algorithm 1. Algorithm for getting key frame sequence
算法1. 获取关键帧序列算法
Algorithm 2. Algorithm for getting key shot sequence
算法2. 获取关键镜头序列算法
4. 实验分析
4.1. 实验数据集
本文实验用到3个公开数据集,分别是TVSum [22]、SumMe [23]、和VSUMM [5]。
TVSum数据集包含50个视频,包含车辆修理、派对聚会、宠物展示等类型的内容。SumMe数据集包含25个视频,包含体育竞赛、节日庆祝等主题,且视频均是未做后期处理的拍摄视频。VSUMM数据集包含100个经过后期处理的视频,时长均在10分钟以下,其中50个视频来自YouTube网站,包含卡通,新闻,体育,商业广告,电视节目和家庭视频这6种类型,另外50个视频来自open video project网站,主要以纪录片为主。TVSum和SumMe的标签是由20名测试者人工标注的重要性评分,VSUMM的标签是由5名测试者人工选取的关键帧。
为了更有效地训练模型,本文对这些数据集的标签进行转换。其中TVSum和SumMe的标签需要选择这20个人工标注的重要性得分的平均值,并缩放到区间[0, 5]之内;而VSUMM的标签则需要把相应的关键帧转化为重要性得分,最大值为5(即5名测试者都选择了该帧为关键帧),最小值为0 (即5名测试者均未选择该帧)。
为了便于与其他模型作比较,本文采用大多数主流模型的数据集划分方法,即所有数据集均按照6:2:2的比例划分为训练集、验证集和测试集;同时将可能影响模型整体性能的卡通视频去除,即将VSUMM中的11个卡通视频移除数据集,保留剩余的89个视频。
4.2. 模型评价指标
为本文采用的评价指标包括F-score、关键帧冗余率KFRR。
F-score用于判断模型所生成视频摘要的整体表征能力。F-score由精确率pre和召回率rec计算得出:
(16)
(17)
(18)
其中
表示模型所生成的视频摘要与测试数据的视频摘要的重叠率,即生成摘要与测试摘要匹配的长度,
表示模型所生成的视频摘要的总长度,
表示测试数据的视频摘要的总长度。精确率衡量模型所生成摘要的总长度。精确率衡量模型所生成摘要相对于测试数据摘要的准确性,召回率衡量模型所生成摘要在测试数据摘要中的比重,是精确率和召回率的调和平均数,衡量两者的整体水平,即衡量模型所生成视频摘要的整体质量。
为了评估所提模型的去冗余效果,本文提出一种新的评估指标——关键帧冗余率,衡量在生成的关键帧序列中,图片的整体重叠率。本文将所生成关键帧序列的整体图片相似度,作为模型的整体关键帧冗余率:
(19)
(20)
(21)
公式(19)中
表示关键帧x与y的相似度,
和
表示长度为n的图片特征向量中的每个值。公式(20)中
表示模型对当前测试视频的关键帧冗余率,通过计算每个关键帧之间的相似度的平均值获得。公式(21)中
表示当前测试视频的冗余率(即
的计算结果),
表示当前测试视频的时长,
表示所有测试视频的总时长,通过将每一个测试视频的冗余率加权平均获得KFRR,其值越小,表示模型的去冗余效果越好。
4.3. 实验过程和结果分析
本文实验采用opencv工具提取视频帧,并将视频帧序列下采样(每秒保留2帧)。特征提取模块采用预训练后的googLeNet网络;重要性得分获取模块由编码器和解码器构成,编码器由2个不同传输方向的GRU网络层组成,每层包含256个GRU,解码器由1个GRU网络层和注意力获取模块组成;视频摘要生成模块则采用3.3节所提算法生成摘要,根据上一模块获取到的重要性得分最大长度设置为8和相似度阈值设置为0.6。训练过程中,损失函数采用均方差函数,优化算法选择随机梯度下降算法,BatchSize设置为32,学习率设置为0.005。本文所提模型的视频摘要的生成流程如图5所示。

Figure 5. Process diagram of summarizing video
图5. 本文模型的视频摘要生成过程图
实验中用到的对比模型是VSUMM [5]、dppLSTM [14] 和SUM-attDecode [15]。其中VSUMM采用k-均值聚类算法生成静态视频摘要,dppLSTM和SUM-attDecode采用基于LSTM的Seq2Seq模型生成静态摘要和动态摘要,其中dppLSTM使用DPP算法去除冗余帧,SUM-attDecoder则使用动态规划算法去除冗余帧。
4.3.1. 比较F-score
本文首先模拟小数据集下模型的性能,仅使用上述3种数据集中的一种用于训练和测试模型,最终结果如表1所示。

Table 1. Comparison of F-score of different models under small dataset
表1. 小数据集下不同模型的F-score对比结果
表1展示了在SumMe和TVSum两种数据集中,本文模型与各种主流视频摘要模型的F-score值对比结果。从表1可以看出,本文模型在SumMe和TVSum中都具有较高的F-score值。相比于dppLSTM和SUM-attDecoder,本文模型所采用的GRU参数更少,因此在数据集较少的情况下,可以采用更高的学习率,使模型快速收敛,从而达到更好的效果。
进一步地,本文通过数据增强,模拟大数据集下模型的性能,与文献 [14] 和文献 [15] 相似,将分别随机选取SumMe和TVSum中20%数据作为测试集,将剩余的80%数据和另外2种数据集合并作为训练集和验证集,数据增强后的实验结果如表2所示。
Table 2. Comparison of F-score of different models under large dataset
表2. 大数据集下不同模型的F-score对比结果
从表2可以看出,相比于小数据集,本文模型在大数据集中的F-score提高了5到6点,证明本文模型在有充足的训练数据和验证数据的情况下,能收敛到更优的结果。同时对比其他模型在数据增强后的结果,再次证明本文模型具有更高的性能。
4.3.2. 比较KFRR
由于KFRR评估指标需要根据模型获取到的关键帧进行计算,因此实验中选择VSUMM和dppLSTM作为比对模型,对比结果如表3所示。
由表3可以看出,本文模型的KFRR值在两个数据集中都保持较低水平,说明本文模型具有更好的去冗余效果。由于SumMe数据集均是原生视频,含有大量的冗余帧,因此本文模型在SumMe数据集中的去冗余效果更加明显。
5. 结语
本文提出了一种融合GRU和非极大值抑制的视频摘要生成模型。所提模型在原有Seq2Seq模型基础上,使用GRU替代传统循环神经网络单元,有效地减少训练参数数量,并使用非极大值抑制算法更高效地去除冗余帧。实验数据表明,所提模型具有较优的性能和去冗余效果,同时具有更好的拟合效果,即使在小数据集中也具有不错的性能。
目前所用数据集均为短视频,导致所训练模型对长视频的摘要生成效果不理想,未来的研究可以考虑通过分段检测的方式对长视频进行逐段检测,并在此基础上对分段视频之间的关联关系进行建模,使视频摘要生成模型能够适应长镜头的检测工作。
致谢
以上是论文的全部论述内容,在这里感谢广东省科技计划项目给予资金支持,感谢陈平华老师的实验指导和修改意见,同时论文的成功撰写离不开实验室小伙伴的帮助,忠心感谢师生给予的良好学术环境。
基金项目
广东省科技计划项目(No.2020B1010010010、No.2019B101001021)。