1. 引言
人工智能技术作为一项新兴技术,近年来发展极为迅猛,研究方向涉及到多种交互模式、智能分析系统管理和构建、大数据挖掘和综合应用等方面,在全世界范围内的众多领域得到广泛应用,应用范围从制造业扩展到信息通信、电商、金融、医疗、翻译等专业服务领域。其中基于深度学习的人工智能技术,在图像识别、语音语义识别、软件设计等多方面能达到人类智慧难以企及的高度 [1]。
增强现实技术,借助计算机视觉技术和人工智能技术产生物理世界中不存在的虚拟对象,并将虚拟对象准确“放置”在现实世界中,通过更自然的交互,呈现给用户一个感知效果更丰富的环境。它包含了多媒体、三维建模、实时视频显示及控制、多传感器融合、实时跟踪及注册、场景融合等新技术与新手段,提供了在一般情况下,不同于人类可以感知的信息 [2]。世界主要的发达国家,均将人工智能产业作为国家发展战略。与之相对的,在我国,关于人工智能技术在电网运维领域的应用尚处于起步阶段 [3] [4]。
针对当前国内在数字化变电站计量运检领域应用人工智能技术的空白,本文开发了专用于深度图像学习的软件工具,可以用来标记数字化变电站计量待训练的图像,并进行有效的识别。通过训练标记好的计量设备图像,与增强现实设备所采集的设备图像进行识别匹配,用以预测现场设备运行中的有用信息,从而形成变电站计量领域宝贵的数字资源。
为了加强增强现实技术在变电站计量应用的准确性,我们改进了yolo-v3图像识别算法,使得该算法能够更好的适应计量设备的识别,提高变电站计量设备图像中有用信息的识别率。
2. 图像深度学习的流程
2.1. 深度学习算法
深度学习(Deep Learning, DL)是机器学习(Machine Learning, ML)领域中一个新的研究方向,它被引入机器学习使其更接近于最初的目标——人工智能(Artificial Intelligence, AI)。深度学习是受到人类大脑处理数据和创造用于制定决策的模式而诞生的一系列算法,并拓展和提升一个人工神经网络的单模型结构。其中,人工神经网络包括前向神经网络(Feedforward Neural Networks, FNN)、卷积神经网络(Convolutional Neural Networks, CNN)和循环神经网络(Recurrent Neural Networks, RNN)等几种主要类型 [5]。
由于循环神经网络采用反馈的形式,从输出回到输入,将信息传递回网络,构成一个循环,具有记住历史数据并应用到预测中的能力。考虑该实际应用增强现实眼镜识别图像能力及其现场应用的实时性要求,本文采用卷层神经网络模型作为基础,针对计量图像实际情况进行针对性的改进,主要是在现有卷积层模型的基础进行改进,使其能够提高图像识别的精确率,不仅提高识别精度,也缩短了收敛时间 [6]。
对于本研究来说,难点主要就是从数字化变电站的各种计量图像中,准确提取各种有效信息,形成数字资源,以更好指导数字化变电站的生产、运行和维护。
由于各种计量设备的外形不同,有效信息的位置不同,加上增强现实设备所采集的图片守拍摄角度和现场光照环境差异等,给本研究的图像识别带来比较大的挑战。结合当前主流的图像识别算法,尤其是针对数字化变电站计量领域图像特点,本研究采用yolo-v3图像识别算法并对其进行改进,以适应计量设备的图像识别工作。
2.2. yolo-v3 图像识别算法
基于深度学习的目标检测已经逐渐成为自动驾驶、视频监控、机械加工,智能机器人等领域的核心技术,而现存的大多数精度高的目标检测算法,速度较慢,无法适应工业界对于目标检测实时性的需求,而随后出现的yolo算法克服了以上的缺陷,成为了图像识别算法的最优选择。
yolo算法是一个对象检测算法的名字,这是Redmon等人在2016年的一篇研究论文中命名的。yolo将对象检测重新定义为一个回归问题。它将单个卷积神经网络应用于整个图像,将图像分成网格,并预测每个网格的类概率和边界框 [7]。
yolo算法使用一个卷积神经网络网络直接预测不同目标的类别与位置,算法相对简便,容易编程实现,具有运算速度快、背景误检率低、召回率低等优点。
鉴于yolo算法的上述优点,我们选择yolo算法来实现目标检测。yolo算法目前已经经过了3个版本的迭代,最新的版本是yolo-v3算法,在速度和精确度上获得了巨大的提升,本文将yolo-v3算法应用于变电站计量信息的图像识别上。
计量信息识别的核心需求就是利用整张图像作为网络的输入,直接在输出层回归所需识别图像边界框的位置及其所属的类别。为支持多尺度目标的识别,本文充分利用yolo-v3算法图像识别的优势,提取计量有用信息,以指导数字化变电站实际运维。
在核心的图像特征提取方面,yolo-v3采用了称之为Darknet-53的网络结构,该算法含有53个卷积层,它借鉴了残差网络的做法,在一些层之间设置了快捷链路,以加快算法效率。
Darknet-53主干网如图1所示,Darknet-53网络采用256 × 256 × 3作为输入,图1最左侧那一列的1、2、8、4等数字表示多少个重复的残差组件。每个残差组件巧妙地设置有两个卷积层和一个快捷链路,可以较好平衡算法精度和算法效率间的关系,这对于有一定实时性要求的变电站计量等电力工业应用具有重要意义。
为了解决对不同尺度目标的检测,深度网络在三种不同的尺度上进行检测,在网络中的三个不同位置处,在三种不同大小的特征映射上使用检测内核来完成检测过程。对于输入图像,先归一化到416 × 616的大小,深度网络在三个等级上进行预测,这通过分别将输入图像的尺寸下采样32、16和8来精确地给出,具体流程如图2所示。
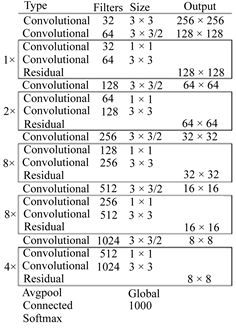
Figure 1. Yolo-v3 algorithm backbone network
图1. Yolo-v3算法主干网
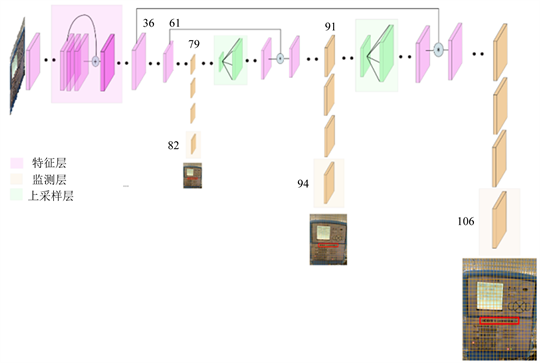
Figure 2. Image recognition and detection flow chart
图2. 图像识别检测流程图
1) 第一次检测由第82层进行,对于前81层,图像由网络下采样,使得第81层具有32的步幅。如果输入为416 × 416的图像,则得到的特征图将具有13 × 13的大小。这里使用检测内核,提供13 × 13 × 255的检测特征图。
2) 来自层79的特征映射经历几个卷积层,然后被2倍上采样到26 × 26的维度,该特征映射与来自层61的特征映射深度连接。之后,组合的特征映射会再次经受几个卷积层以融合来自较早层的特征。通过第94层进行第二次检测,产生26 × 26 × 255的检测特征图。
3) 再次遵循类似的过程,其中来自层91的特征图在与来自层36的特征图深度连接之前会经历少量的卷积层,以融合来自先前的信息。最终在第106层进行第三次检测后,产生尺寸为52 × 52 × 255的特征图。
这样就实现了13 × 13层负责检测大型物体,而52 × 52层检测较小的物体,26 × 26层检测中等物体。
3. 深度学习算法改进方案
3.1. 基于优化的锚盒子设计
yolo-v3算法采用锚盒子(Anchor box)的概念,有助于增加目标检测的性能。锚盒子对于物体检测影响非常大,常见的设计是基于手工的分析方法,即定义若干个个特定尺度和长宽比的锚盒子,然后在全图上以一定的步长滑动。这种方式在其他经典的图像识别检测方法中也被广泛使用。而yolo-v3算法的锚盒子设计的特殊之处在于,通过采用K-Means算法对数据集聚类得到从而提高算法性能。但无论是手工定义一组尺度、长宽比还是通过聚类得到锚盒子,目前存在以下两个问题:
1) 大部分的锚盒子都分布在背景区域,这些锚盒子对检测没有任何作用;
2) 量设备图像中厂家和型号等对象宽高比极大,而像信号等对象宽高比又非常小,预先定义好的锚盒子无法满足这些宽高比差异较大的情况。
因此本文对现有的锚盒子设计进行改进,其中锚盒子优化的对象如下:1) 锚盒子的中心位置,即让锚盒子尽可能分布在有对象的区域;2) 优化锚盒子的宽高,使之与对象的形状接近。
从上面分析可知,深度学习的图像识别中,本质上是给定一系列训练样本,通过映射关系,使得给定一个输入,即便这个输入不在训练样本中,也能够输出目标,尽量与真实目标接近。损失函数(loss)是用来估量模型的输出目标与真实值目标之间的差距,给模型的优化指引方向。
本文使用Darknet53输出的特征优化锚盒子位置和大小,其loss如下式:
(1)
式中Lloc为锚盒子位置预测分支loss,Lshape为锚盒子形状预测分支loss,λ用以调整二者的权重,λ开始时取0.5,之后取值由每次计算时的位置偏差决定,计算位置偏差的数字,这个偏差对应着锚盒子中心位置。我们将整个特征图区域分成物体中心区域,外围区域和忽略区域,标记框中心区域映射到特征图对应位置,标记为正样本。标记框除中心区域外映射到特征图对应位置,标记为忽略,训练时不处理。标记框以外区域映射到特征图对应位置,标记为负样本,这样位置预测简化为一个二分类问题,采用二值交叉熵损失。
形状预测分支的目标是给定锚盒子中心点,预测最佳的长和宽,这是一个回归任务。由于优化的宽高,因此无法直接确定锚盒子应该分配给哪个标记框,这样就无法确定优化目标。
因此,本文采用近似的方法,即采样几组常见的宽高,将锚盒子分配给与之最大交并比(Intersection-over-Union, IoU)的标记框,由此确定优化目标。本文方法中,优化锚盒子的宽高使之与对应标记框具有最大IoU,经过学习后锚盒子与标记框具有较大的初始IoU。形状预测分支loss如下式:
(2)
式中为平滑L1损失,(w, h)和wg,hg,分别表示预测锚盒子的形状和标记框形状。
3.2. 卷积层改进
锚盒子与标记框的IoU越大,锚盒子的分类和回归就变得更容易,但无论是分类还是回归,对主干网的特征依赖性强。特征质量提高会带动检测效果的提高,这一点从更换较大的主干网,平均精度一般会提高1到2个点中可以看出。使用更大的主干网带来的提升很有限,同时计算量会显著提高。在不增加网络层数条件下,提高卷积提取的特征质量非常重要。
传统卷积的几何结构是固定的如3 × 3卷积,这限制了网络的几何变换能力。本文采用可变形卷积(Deformable Convolution)模块,提高对计量设备图像不同物体形变的建模能力。可变形卷积基于一个平行网络学习offset,使得卷积核在输入特征图的采样点发生偏移,集中于我们感兴趣的区域。标准卷积中的规则格点采样是导致网络难以适应几何形变的原因,为了削弱这个限制,对卷积核中每个采样点的位置都增加了一个偏移变量,可以实现在当前位置附近随意采样而不局限于之前的规则格点。本项目设置Darknet53的C9-C11替换为可变形卷积。
在基于优化的锚盒子的设计中,由于锚盒子的尺寸大小可以变换,原始固定尺寸的锚盒子特征映射到同一个网格的对应关系被破坏,本文使用3 × 3的变形卷积方法修正原始的特征图,锚盒子的宽度和高度经过一个1 × 1卷积得到变形卷积方法的偏差值,此操作将锚盒子区域的特征融合到一个网格中,消除了可变锚盒子带来的特征不匹配问题。由于部分区域没有锚盒子,这部分区域再通过卷积计算特征时没有意义的,因此采用带掩膜的卷积,没有锚盒子的特征区域掩膜设置为0,以提高计算速度。
4. 算法实现
4.1. 算法实现流程
实现深度学习的图像识别流程通常如下:先是通过导入大量现有的现场图片进行学习,然后形成数据库,最后图像识别时再调用端口导入需要预测的图片,具体过程如图3所示。

Figure 3. Image recognition training process of deep learning algorithm
图3. 深度学习算法图像识别训练过程
1) 通过图像深度学习训练工具导入大量的现场设备图像素材(正常运行、各种故障的图片素材),然后开始对每张图片进行标记特征,每张图片会有多种特征(厂家名称、型号、电源灯、运行灯、液晶屏幕、条形码等);
2) 待全部图片标记工作完成后,进行归类训练,形成学习库(学习库是自定义格式,非关系型数据库)。
3) 选取长宽为13 × 13的锚盒子,在卷积运算过程中计算IoU值,仅留下IoU大于阈值的框,提取框尺寸的数值,并与对应的喵盒子的尺寸比较,计算尺寸偏差的数值,记录留下的框对应喵盒子的id和对应图片的id,这代表着是用13 × 13中的哪个格子进行预测。
4) 将电力工业现场采集的数字化变电站计量图像,作为待处理图片,图像识别时调用yolo-v3算法,将数字化变电站计量表图像所显示的表计数字大小作为目标,从导入的计量表图像图片中提取表计数值,作为返回值。
4.2. 算法实现工具
电力设备的图像特征数据属于比较重要的电力数据,基于数据安全原则,采用C/C++、Qt5.12.3等开发语言自主开发了一套用于图像深度学习的配置及训练工具,方便开展工作量繁多的图片特征标记工作、自动学习训练工作及其他管理操作。
工具采用工程项目管理的方式,可支持多项目、多设备的标记配置及深度学习训练,可适用于所有电力一二次设备,本文主要用于对数字化变电站计量设备进行深度学习的配置及训练,训练工具支持以下功能:
1) 训练工具支持多个训练工程的管理与切换:采用xml格式进行深度学习训练工程的字段信息存储及管理。通过点击工程列表下某个训练工程,可以进行切换,如图4所示。切换后该训练工程的已导入图片及标记等信息都会在相应tab分页进行详细展示。
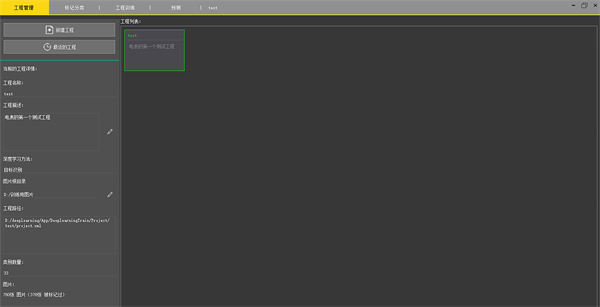
Figure 4. The management interface of the training project
图4. 训练工程管理界面
2) 工具可对当前训练工程添加图片素材:本工具支持添加单个图片文件到工程或者添加整个图片文件夹进行快速的图片载入。
3) 训练工具可进行数据标记:通常图像特征数据标记是个耗时耗力的工作,而本工具支持比较快捷的标记方法,能以简单有效的方式管理标记信息。
5. 算法验证
电力设备的图像特征数据图像识别对于硬件要求比较高,采用GPU识别一般几十毫秒,而采用CPU识别则一般需要几秒,本项目不能接受这种速度。另一方面,图像识别依赖的深度学习引擎基本也都要依靠GPU来进行训练和运算。
考虑到目前国内外所有AR眼镜的硬件支撑不起图像深度学习与识别,因此我们采用含GPU硬件的云服务器,在云端完成大量的图像深度训练和学习。以下就是我们对基于深度学习的图像识别算法的实现和验证。
1) 工具深度学习训练
工具即可进行对本训练工程图片素材及标记数据的深度学习训练,训练算法支持Darknet和TensorFlow等经典的神经网络算法库。
其中TensorFlow是由谷歌人工智能团队开发和维护的神经网络算法库,是目前主流的开源机器学习框架;Darknet是相对轻量级些,而重量级的库对于学习的样本数量要求会比较多。
本项目的云服务器采用GPU (Nvidia Tesla P4)对集中器设备图片素材进行训练速度实测:样本数量100张采用Darknet深度学习算法进行训练,训练耗时8小时左右,如图5所示。

Figure 5. The main interface of engineering training
图5. 工程训练主界面
2) 训练工具训练完成后的预测
预测结果如图6所示。界面左侧会显示选择的预测方法,本次实验采用的是工程预测。在预测时将训练的图像拖入左侧,而要预测的图像拖入右侧。预测结果出现后,也会同时显示标记的分类数和图片总数以及预测准确率。这样能够非常清晰地显示相应的图像识别训练的效果,方便训练人员改进训练样本,提高图像识别的精确度。

Figure 6. The prediction result of engineering training
图6. 工程训练完成的预测结果
3) loss曲线
最后通过loss曲线来判断神经网络的训练情况,如图7和图8所示,训练集和验证集两者的loss曲线都逐渐收敛且间隙趋于稳定,虽然没有降到足够低(例如0.0x这个图像拟合几乎完全一致的数量级),但也说明该训练模型已经非常好地拟合了目标图片,同时算法具有较好稳定性。
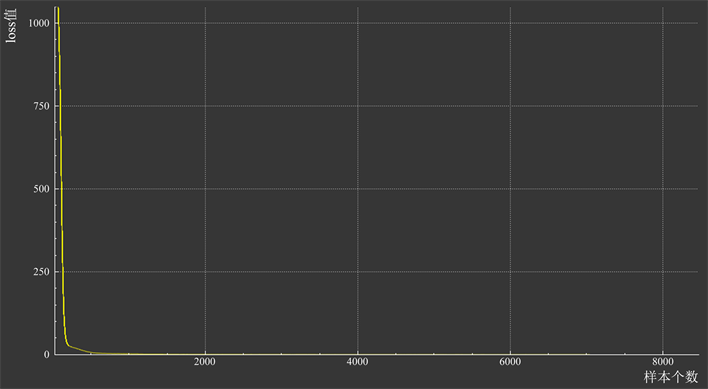
Figure 7. The loss curve of the training set
图7. 训练集的loss曲线

Figure 8. The loss curve of the validation set
图8. 验证集的loss曲线
6. 结论
针对现有的图像识别训练算法的不足,本文对传统的yolo-v3算法进行了改进,提出了一种适用于数字化变电站计量运检系统的图像识别训练方法。为与改进的算法相匹配,同时研发了一套用于适用于数字化变电站计量运检系统的图像深度学习配置及训练工具,更好地进行训练工具的管理和图像识别学习的优化。验证结果表明,该方法在应对计量设备式多样化、故障类型多样化、图像采集条件复杂化等恶劣识别训练工作条件有着广阔的应用前景,有助于降低数字变电站的运捡维护成本和提高变电站运维效率。