1. 引言
糖尿病是最常见的慢性病之一,随着人们生活水平的提高,人口老龄化以及肥胖发生率的增加,糖尿病的发病率呈逐年上升趋势。据统计,糖尿病在中国以每年100万的速度递增。其中,1型糖尿病患者占10%,2型糖尿病患者占90%。
根据IDF于2017年11月14日公布的数据显示:2012年,全球半数以上糖尿病未被诊断,约50%的糖尿病患者不知道自己患糖尿病。约480万人死于糖尿病,其中半数死于60岁以下。糖尿病防治医疗费用超过4710亿美元;2013年,全球糖尿病在20岁~79岁成人中的患病率为8.3%,患者人数已达3.82亿,其中80%在中等和低收入国家。IDF预计到2035年,全球将有近5.92亿人患糖尿病。全球糖尿病防控形势已日趋严峻,糖尿病已对全球医疗体系构成巨大挑战。我国是糖尿病的重灾区,中国糖尿病的患病人数已高居全球首位,其次是印度、美国、巴西、俄罗斯。同时,据最新的《中国成人糖尿病流行与控制现状》调查研究显示,中国18岁及以上成人糖尿病患病率已高达11.6%,糖尿病前期的患病率更是达到了惊人的50.1%。这意味着,每10位中国成年人中,就有6位血糖不正常。按照这一比例,我国糖尿病患者人数已达1.14亿人,糖尿病前期人数接近5亿人。糖尿病已经成为我国最为重要和棘手的公共卫生问题之一 [1]。本文利用ARIMA模型模拟中国近年糖尿病患者人数变化趋势,并进行短期预测,为中国人民身体健康提出科学依据。
2. 资料与方法
2.1. 数据来源
表1数据为搜集2000~2018年中国各年糖尿病人数。
2.2. 研究方法
ARIMA模型是由Box和Jenkings提出的重要时间序列分析预测模型,ARIMA模型包括三种基本模式:自回归模型AR(p),移动平均模型MA(q)和自回归移动平均ARMA(p,q)模型。其中,p、q分别为自回归和移动平均的阶数。应用ARIMA模型的前提条件是:预测对象是一个零均值的平稳随机序列且这一平稳随机特性不随时间变化而变化 [2]。如果序列不是平稳的序列,需要对原始序列进行平稳化的处理,最常见的处理方法是对原始序列进行d次差分,拟合预测模型ARIMA(p,d,q),d代表非平稳序列差分的次数。本研究利用R3.4.3软件对中国近年糖尿病患者数据拟合ARIMA模型,并进行预测分析。ARIMA模型建模分为4个步骤。
1) 模型识别
ARIMA模型建模的基础前提是数据序列应该是平稳序列,本研究中通过观察中国近年来糖尿病患者序列的时序图,以此判断平稳性,若不满足平稳性,需要利用“diff”函数进行差分平稳化成平稳序列,此时差分的次数即为ARIMA(p,d,q)模型中的阶数d,在此基础上利用自相关函数图和偏自相关函数图判断截尾性和拖尾性,并且依据图像确定p、q的值进行定阶 [3]。
2) 参数估计
采用最大似然估计计算自回归系数和移动平均系数。利用“Box.test”函数进行模型诊断,判断残差是否满足白噪声,若不满足白噪声模型则需要改进。
3) 模型检验与优化
依次确定p、q的值,利用“Box.test”函数进行模型诊断,判断残差是否满足白噪声,在残差满足白噪声前提下,依据信息量最小原则,选择AIC和BIC值最小的模型为最佳模型。
4) 进行预测
通过确定的最优模型,对中国2014~2018年糖尿病患者人数进行预测,并与实际值进行比较,计算预测值和实际值间的相对误差。
3. 结果
3.1. 模型识别
收集中国2000~2018年糖尿病患病人数的数据,见表1,对中国2000~2013年糖尿病患病人数的数据绘制时序图,见图1。由时序图观察可得,中国2000至2013年糖尿病患者人数整体呈上升趋势,2000至2005年患者人数上升较快,2005至2010年患者人数增长较为平缓,2010至2011年最为特殊,患者人数出现了下降趋势,之后增长速度放缓。
由时序图可看出,此时间序列为非平稳时间序列,并且蕴含一个近似线性的递增趋势,因此,需要对该序列进行1阶差分运算,并绘制差分序列的时序图,见图2。
由图2可见,经过一次差分之后,差分序列的线性趋势被提取。因此,对差分后的数据绘制acf图和pacf图,见图3。
由图3我们可以看出,自相关函数图呈拖尾现象,偏自相关函数图呈现了1阶截尾特性,因此,我

Table 1. Number of diabetes mellitus patients in China from 2000 to 2018 (unit: billion)
表1. 2000~2018年中国糖尿病患病人数(单位:亿)

Figure 1. Number of diabetes patients in China from 2000 to 2013
图1. 2000~2013年中国糖尿病患病人数
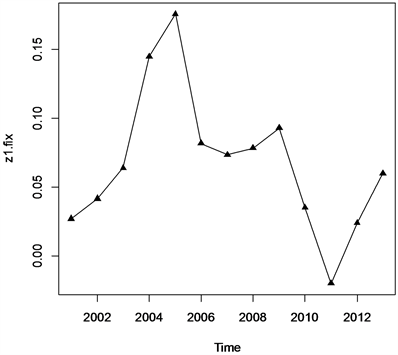
Figure 2. Sequence Diagram of first order difference sequence
图2. 一阶差分序列时序图

Figure 3. ACF Diagram and pacf diagram of difference sequence
图3. 差分序列的acf图和pacf图
们可以初步确定拟合模型为ARIMA(1,1,0)。
3.2. 参数估计
由3.1我们已经初步将模型识别为ARIMA(1,1,0),现采用条件最小二乘法估计未知参数,根据估计的结果,我们可以确定该模型的口径为
接下来,我们利用“Box.test”函数进行检验,对中国近年糖尿病患者序列拟合模型的残差序列进行延迟6阶和延迟12阶的白噪声检验,检验结果见表2。
Table 2. Residual test results of Arima (1,1,0) model
表2. ARIMA(1,1,0)模型的残差检验结果
由表2,我们可以知道,延迟6阶和延迟12阶的统计量
的p值显著大于显著性水平0.05,所以可以认为模型的残差序列是白噪声序列。
3.3. 模型检验与优化
我们依次将模型拟定为ARIMA(1,1,0)、ARIMA(0,1,1)、ARIMA(0,1,2)、ARIMA(2,1,0)、ARIMA(1,1,1)、ARIMA(2,1,1)、ARIMA(1,1,2),然后利用“Box.test”函数进行模型诊断,判断残差是否满足白噪声,检验结果见表3。
Table 3. White Noise test for residual series of Arima (P, 1, Q) alternative model
表3. ARIMA(p,1,q)备选模型残差序列的白噪声检验
由表3可以知道,7个模型延迟6阶和延迟12阶的统计量
的p值均显著大于显著性水平0.05,因此可以认为这7个模型的残差序列均是白噪声序列。由于残差序列均满足白噪声,因此依据信息量最小原则,我们需要选择AIC和BIC值最小的模型为最佳模型。7个模型的AIC、BIC值见表4。
Table 4. Comparison of Arima (P, 1, Q) alternative model AIC and BIC values
表4. ARIMA(p,1,q)备选模型AIC、BIC值的比较
依据表4,可以看出ARIMA(1,1,0)的AIC、BIC值最小。因此,我们选定ARIMA(1,1,0)为最优模型。
3.4. 进行预测
通过3.3中,我们确定最优模型为ARIMA(1,1,0)。因此,我们通过最优模型进行未来五年,即2014~2018年中国糖尿病患者人数的预测,并绘制图像,图像见图4。
并绘制个性化的预测图,预测图见图5。
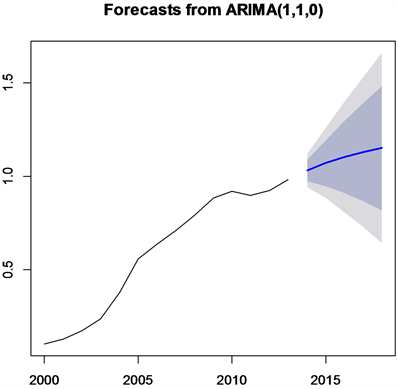
Figure 4. Projected number of diabetes patients in China from 2014 to 2018
图4. 2014~2018年中国糖尿病患者人数预测图

Figure 5. Personalized predictors of Diabetes Mellitus in China from 2014 to 2018
图5. 2014~2018年中国糖尿病患者人数个性化预测图
散点图为观察值序列,实线是拟合值,虚线是95%的置信线。
同时将预测值与这五年间糖尿病患者人数的实际值进行比较,计算相对误差,判断预测效果。结果见表5。
由表5我们发现,实际糖尿病患病人数均在预测值95%可信区间内,用2014~2018中国糖尿病实际患病人数评价ARIMA(1,1,0)模型预测准确度,预测值与实际值的平均相对误差为2.2689%,可见预测结果与实际结果基本一致,模型预测效果较好 [4]。
Table 5. Forecast analysis of Arima (1,1,0) model
表5. ARIMA(1,1,0)模型预测分析
4. 总结
近年来,由于生活水平的提高,饮食结构的改变,日趋紧张的生活节奏以及少动多坐的生活方式等诸多因素,全球糖尿病发病率增长迅速,糖尿病已经成为继肿瘤、心血管病变之后第三大严重威胁人类健康的慢性疾病,未来50年内,糖尿病仍将是中国一个严重的公共卫生问题 [5]。专家指出,由于目前人们的饮食结构正在由植物型向动物型转变,高脂肪、高热量食物正在越来越多地充斥我们的生活,加上糖尿病知识以及健康生活理念不够普及,都对中国糖尿病防治能力以及糖尿病教育提出更高的要求。尽管中国糖尿病发病趋势严峻,但防治状况不容乐观,一是因为目前我国专业糖尿病治疗机构、人员和设备等资源不足,无法与日益增长的糖尿病患者人数相适应,致使中国整体糖尿病诊治率还相对较低,二是因为许多公众和患者对糖尿病防治知识的认识不足,在糖尿病防治方面存在治疗不及时、用药选择和时机不当、忽视饮食运动等误区,从而使治疗效果不理想。另外,我国在糖尿病营养学和运动领域几乎还是空白,绝大多数医院目前尚无专业的糖尿病营养和运动医师 [6]。在糖尿病防治过程中,护理人员的专业素养与西方发达国家相比相对滞后,护理人员糖尿病专业知识的掌握程度还比较肤浅。同时,由于护理人力资源配置不合格,无暇对糖尿病人进行教育。
时间序列分析通过观察值历史数据来预测其发展趋势,探索其时间分布特征及影响因素。ARIMA模型应用于经济、工程、气象、水利等众多领域。医学卫生领域也用于预测疾病发病率、人群寿命、医疗卫生费用和食物中毒等,还用于研究气候及环境因素对人群健康的影响 [7]。
本研究选用中国2000~2013年糖尿病患者人数的数据进行时间序列分析。显示这些年间中国糖尿病患者人数整体呈上升趋势,且前些年大幅上升。基于我国基本国情分析,自2000年起,中国经济发展迅速,人民生活水平日益提高,人民的饮食结构正在由植物型向动物型转变,有更多高脂肪的食物经常出现在人们的生活中,因此,这些年间,糖尿病患病人数大幅增长。2010年后,糖尿病患者人数增长放缓,由于前些年人们对于糖尿病有了一定的认识,且我国的医疗水平日益提高,因此,对于糖尿病的防治有了一定的效果,增长速度放缓。经过模型识别、参数估计、模型优化确定最优模型为ARIMA(1,1,0),并且通过最优模型我们对中国2014~2018这五年间糖尿病患者人数进行了预测,预测值与实际值的平均相对误差为2.2689%,且实际糖尿病患病人数均在预测值95%置信区间内,预测效果较好。通过预测,我们发现这五年间,中国糖尿病患者人数仍然是逐年上升,但增速较为缓慢,可见,随着信息化时代的发展,人们对于糖尿病的认识越来越广泛,对于糖尿病的防治越来越有效,人们通过健康的生活方式,并且在日常生活中,控制饮食,加强锻炼,以此来预防糖尿病的发生。
本研究证实,通过时间序列对某种疾病患病人数或发病率进行建模,确定最优模型,可较好地对这种疾病的发展趋势进行预测,这种方法给疾病的预测及控制提供了一种科学的依据。
基金项目
国家级大创项目(202012026039)。
附录
中国近年糖尿病患者数据建模的程序
1) 模型识别
> x<-read.csv(D:/时间序列/中国历年糖尿病患病人数.csv,header=T)
> z1<-ts(x$data,start=2000)
> plot(z1,type=o,pch=17,main=2000-2013年中国糖尿病患病人数)#绘制时序图
> z1.fix<-diff(z1)
> plot(z1.fix,type=o,pch=17)#消除趋势
> par(mfrow=c(1,2))
> acf(z1.fix,lag=50)
> pacf(z1.fix) #绘制自相关、偏自相关图
2) 参数估计、模型检验
> l<-arima(z1,order=c(1,1,0),method=CSS)
> l
> for(i in 1:2) print(Box.test(l$residual,type=Ljung-Box,lag=6*i))
3) 模型优化
> library(forecast)
> z1.fix1<-Arima(z1,order=c(1,1,0),method=ML)
>for(i in 1:2) print(Box.test(z1.fix1$residual,type=Ljung-Box,lag=6*i))
> z2.fix2<-Arima(z1,order=c(0,1,1),method=ML)
>for(i in 1:2) print(Box.test(z2.fix2$residual,type=Ljung-Box,lag=6*i))
> z3.fix3<-Arima(z1,order=c(0,1,2),method=ML)
>for(i in 1:2) print(Box.test(z3.fix3$residual,type=Ljung-Box,lag=6*i))
> z4.fix4<-Arima(z1,order=c(2,1,0),method=ML)
>for(i in 1:2) print(Box.test(z4.fix4$residual,type=Ljung-Box,lag=6*i))
> z5.fix5<-Arima(z1,order=c(1,1,1),method=ML)
>for(i in 1:2) print(Box.test(z5.fix5$residual,type=Ljung-Box,lag=6*i))
> z6.fix6<-Arima(z1,order=c(2,1,1),method=ML)
>for(i in 1:2) print(Box.test(z6.fix6$residual,type=Ljung-Box,lag=6*i))
> z7.fix7<-Arima(z1,order=c(1,1,2),method=ML)
>for(i in 1:2) print(Box.test(z7.fix7$residual,type=Ljung-Box,lag=6*i))
> z1.fix1$aic
> z1.fix1$bic
> z2.fix2$aic
> z2.fix2$bic
> z3.fix3$aic
> z3.fix3$bic
> z4.fix4$aic
> z4.fix4$bic
> z5.fix5$aic
> z5.fix5$bic
> z6.fix6$aic
> z6.fix6$bic
> z7.fix7$aic
> z7.fix7$bic
4) 进行预测
> z1.fore<-forecast(z1.fix1,h=5)
> z1.fore
> plot(z1.fore) #模型预测,进行五期预测
绘制个性化预测图:
> Q1<-z1.fore$fitted-1.96*sqrt(z1.fix1$sigma2)
> Q2<-z1.fore$fitted+1.96*sqrt(z1.fix1$sigma2)
> B1<-ts(z1.fore$lower[,2])
> B2<-ts(z1.fore$upper[,2])
> J1<-min(z1,Q1,B1)
> J2<-max(z1,Q2,B2)
> plot(z1,type=p,pch=10,ylim=c(J1,J2))
> lines(z1.fore$fitted,col=4,lwd=2)
> lines(z1.fore$mean,col=4,lwd=2)
> lines(Q1,col=6,lty=2,lwd=2)
> lines(Q2,col=6,lty=2,lwd=2)
> lines(B1,col=7,lty=2,lwd=2)
> lines(B2,col=7,lty=2,lwd=2)#绘制个性化预测图
NOTES
*通讯作者。