1. 引言
降水作为全球水循环三个最重要组成部分之一,其对人类生活影响程度不言而喻。多普勒天气雷达是进行气象观测的重要工具,其可产生三个最主要的数据:雷达反射率因子(雷达回波)、平均径向速度和谱宽。利用雷达回波可确定降雨(雪)带,但是如何准确分析二者关系,例如确定某次降雨的等级或者大小,是一个具有挑战性的工作。
目前被广泛研究用于雷达回波与降雨量关系分析的方法主要有两种:Z-I关系法和雷达外推法。Jones等发现了反射率因子(雷达回波强度单位)与降水量间的Z-I关系。多普勒效应被发现后,雷达数据与雨量站数据开始结合使用,简单的Z-I关系也逐渐开始被优化 [1]。Suzana R等人为了获得更准确的区域Z-I关系,使用了最优化方法 [2];而汪瑛则提出了动态分级Z-I关系估计法 [3]。Brandes引入Bares客观分析法来分析雷达回波与降雨关系 [4]。目前,与Z-I关系结合使用最主要的雷达外推方法是光流法 [5]。使用光流法进行雷达外推后,还要使用Z-I关系进行反演,二者误差叠加,整体分析精度会降低。
近年来,机器学习相关技术为很多领域解决问题带来了新的途径,使得许多原来棘手的非线性问题迎刃而解。在气象领域,Lee等人根据当地雷达信息和降水数据通过径向基神经网络,预测了24小时后的降雨量 [6];Robert等在降雨数值分析的基础上,引入了人工神经网络进行局部地区降雨分析 [7];Luk等人使用多层前反馈神经网络、偏循环神经网络和时间延迟神经网络3种方法对帕拉玛塔河流域上游暴雨量进行了预测,表明选用这3种模型用来进行分析预测是可行的 [8];Chau等将极限学习机与马尔科夫蒙特卡洛方法、Copula和Bat算法结合,实现了巴基斯坦3个农业带的降雨分析,取得了很好的结果 [9];韩婷婷、时玮域 [10] 等人使用SVM方法对大雾天气进行预测,在大雾预测方面实现了新的突破。
基于此,本文采用XGBoost集成学习算法,采用多层雷达数据进行降雨分类问题分析。本文使用辽宁省气象局提供的辽宁省内的雷达回波数据及多个降雨观测站点测得的降雨数据,经数据预处理与匹配后,形成雷达回波与降雨数据集。随后,使用优化后XGBoost模型对雷达回波与降雨量之间的关系进行分析。最后,搭建了雷达回波与降雨分析系统,并投入日常气象工作中使用。文中第2节描述了数据组织方式以及预处理办法;阐述了如何建立优化模型、搭建降雨分析系统的过程以及系统实现的主要功能。第3节则对实验结果进行分析,研究模型内部分析数据规律,以及使用该方法进行分析预测的可行性。论文第4节则对全文进行了总结。
2. 多层雷达数据与降雨关系分析
2.1. 雷达和降雨数据集的处理
本模板本文使用历年辽宁省地区的多层雷达回波数据和降雨数据来建立机器学习训练样本数据集,原始数据由辽宁省气象局提供。为了有效利用多层雷达和降雨数据提供的有用信息,构建可靠的雷达回波和降雨关系分析模型,需要将原始的雷达数据和降雨数据进行数据预处理。数据预处理包括去除脏数据、站点观测值提取、强化特征,然后按照时间相近原则匹配雷达观测数据和降雨测量数据。
雷达数据每间隔6分钟产生一次,每次产生21层雷达数据,它们对应间隔0.5 km不同高度的雷达回波,其可视化后如图1所示。据气象领域经验,通常最上和最下2层雷达所得数据存在较强的杂波干扰并且降雨量关系不明确。因此,本文选取3~19共17层雷达回波值来构成数据集的特征序列,其组织形式如图2所示。
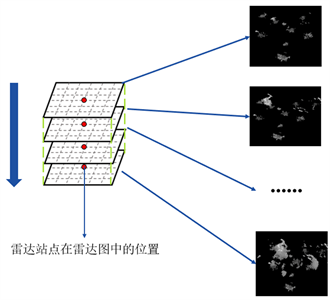
Figure 2. Multilayer radar data organization form
图2. 多层雷达数据组织形式
首先依据规格说明对原始雷达数据文件进行解析,获得雷达图分辨率、中心经纬度、像素间距对应实际距离等头部信息。然后,将二进制数据流文件转成雷达图对应的数值矩阵。最后,根据气象观测站点经纬度,在多层雷达数据中找到其位置,并求得该位置八邻域雷达回波数据均值,依据式(1)转换为对应的雷达回波值。其中dBZ是雷达回波的单位,Grey表示灰度值。八邻域雷达回波数据均值是指依据经纬度在雷达图中找到雷达站点对应回波值后,同时取其周围八个回波值,加自身共9个数据均值作为站点对应的回波值,其目的是减少雷达回波数据的稳定性,从而更好地反映降雨的变化关系。
(1)
降雨数据间隔产生,一小时内累计,下一小时重新计算,表示雨量站监测的一小时内降雨量。为了得到固定间隔内准确的降雨值,在数据库中提取有雨数据,然后添加精确位置和时间信息。然后进行数据清洗,删除空数据,得到数据集中的标签列。
进行雷达数据和降雨数据匹配时,由于采样频率不同,进行匹配要求时间接近、站点编号完全一致。匹配完成后,根据气象分析预测需求,将匹配后的数据分为5个等级。
2.2. 基于XGBoost的雷达回波与降雨分析系统
2.2.1. XGBoost集成学习算法
本文采用集成学习中的XGBoost方法来分析雷达回波与降雨量之间的关系。基于集成学习的雷达回波与降雨分析方法通过集成多个弱分析器的结果来提升分析的准确率 [11]。本文所述多层雷达回波数据与降雨量之间存在着复杂的函数映射关系,普通弱学习器很难取得很好的效果。把多个弱学习器组合在一起,形成一个强学习器,这是集成学习的核心思想。
XGBoost是GBDT (Gradient Boosting Decision Tree)的改进版本。为了避免过拟合问题,它将树模型的复杂程度纳入到正则项中;损失函数使用泰勒展开式展开,使用了一阶导数与二阶导数。经历 次迭代后样本i的分析结果可以被表示为:前 棵棵决策树分析结果与使用迭代函数 的第 次迭代结果之和。
(2)
XGBoost的目标函数可被表示为式(3),其中,第一项为损函数差,例如常见的logistic或MSE,其代表了模型的偏差;为了尽可能减小模型方差,控制树的复杂程度,在一定程度上防止发生过拟合现象 [12],在目标函数中加入了第二项正则项
,它的更详细表示见式(4)。式(4)中,T表示每棵树叶子节点的数量,其值越小表示模型越简单,
表示这些树叶子节点权重组成的集合,
中权重不宜过高,
、
是参数,可依据实际应用自行设置。
(3)
(4)
为建立XGBoost分析模型,需将前文所述预处理后的数据集划分成2部分,一部分用来训练XGBoost模型,另一部分用来验证模型效果。XGBoost模型接受雷达数据的3~19层,共17层雷达回波作为输入,经内部多棵决策树分析后,输出多层雷达回波数据对应的降雨等级(0~4级,共5个等级)。
2.2.2. 基于XGBoost的雷达回波与降雨分析模型优化
虽然XGBoost在防止过拟合、泛化能力等方面表现不俗,但只有找到一组最优超参数,该模型表现才能最优。目前,网格搜索、随机搜索、遗传算法以及粒子群算法等常被用来进行参数优化。上述方法除网格搜索方法外,在进行多个超参数优化时,都存在参数间相互影响的问题,往往不能保证结果最优。
网格搜索(Grid Search)是一种穷举搜索调参手段,这种优化方法将尝试范围内的每一种超参数组合,以此确定最优的超参数组合。显然,网格搜索方法可以避免选取局部最优解的问题。为了尽量提高分析模型的准确率,本文选取网格搜索作为超参数优化方法,并且采用 折交叉折验方式来验证选取的超参数组合是否合理。
K折交叉验证(K-fold cross validation)是一种检验分类器性能的统计学方法 [13]。其基本思想是将训练集分为K份(均等划分,K ≥ 2),其中K − 1份作为训练集,带入模型训练,剩余1份子集作为验证集 [14]。上述过程重复K次,验证集每次选取第1,2,3,……,K份子集,记录每次验证集得分Ei(1 < i ≤ K),并求得均值作为得分 [15]。网格搜索与交叉验证关系见图3。
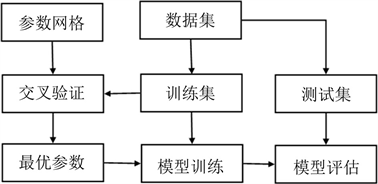
Figure 3. Grid Search and Cross Validation
图3. 网格搜索与交叉折验确定参数
2.2.3 降水分析系统的设计与实现
为将前文设计实现的分析算法投入日常气象工作中,本文设计并实现了一个功能齐全、用户友好的分析系统。系统功能可以被分为四个部分,分别是:雷达数据自动获取处理模块、雷达数据分析模块、降雨数据分析模块以及结果分析模块,相关模块功能框图见图4。
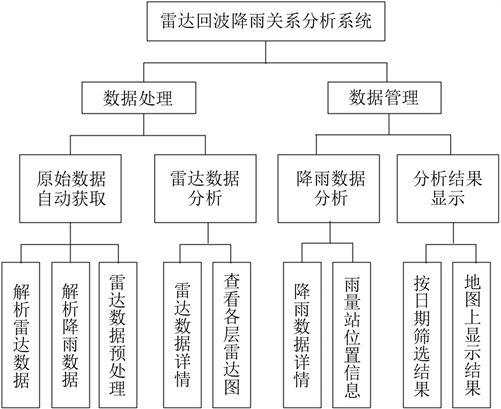
Figure 4. System functional block diagram
图4. 系统功能框图
雷达数据自动获取处理模块主要完成两项工作:一是在后台自动完成对雷达数据的预处理工作,处理过程如前文所述,处理过后得到数据集;二是对雷达数据进行转码、解码、可视化等一系列操作,得到每间隔6分钟的21层雷达图,随后使用雷达数据分析模块注册的回调函数告知该模块,雷达数据已准备完成,可供调用。
雷达数据分析模块主要完成雷达数据分析和雷达可视化工作,其界面如图5所示。在该模块中可以选择查看指定时间的雷达可视化图片以及雷达数据头部信息,包括:文件说明、纵深数量、网格开始经纬度及中心经纬度、有效站点等信息。
最后一个模块显示XGBoost分析模型输出的分析数据。左侧选择当前查看的时刻后,右侧会显示这一时刻XGBoost模型的分析结果。分析结果包含一张由basemap绘制的辽宁省地图,地图内包含按照经纬度位置信息绘制的降雨雷达监测站点。降雨量从大到小被分为5个等级,分别由绿色、蓝色、黄色、橙色以及红色标识,如图6所示。
3. 实验结果及分析
文中所述降雨分析属分类过程,其评价指标有准确率(Accuracy,式(5))、精确率(precision,式(6))、召回率(recall,式(7)),F1得分(F1-Score式(8)) [16]。上述式中TP、TN、FP、FN等含义见表1,正类使用“1”表示,负类使用“0”表示。

Table 1. Abbreviations used in evaluation method
表1. 评价方法中涉及缩写含义
(5)
(6)
(7)
(8)
准确率主要评价模型正确预测分析样本能力,精确率即查准率,被用来评价模型的精确性,指类别真正为“1”的数据占所有预测为“1”的数据比例;召回率又称查全率,被用来评价模型对于类别为“1”的数据识别能力;而F1得分是折中进行模型评估。
在使用本文所述XGBoost方法建立基于多层雷达回波数据的降雨强度等级分析模型时发现,在一定范围内当训练迭代次数(即模型中树的数量)增加时,模型分析效果有一定提升,但超过某个值时,即使训练集误差减小,测试集误差率仍不变甚至轻微上升,这说明发生了过拟合现象,详见图7。在图7中,迭代次数小于600时,测试集与训练集误差均在减小,说明此时为欠拟合状态;而迭代次数大于1000以后,训练集误差近似一条直线,表明此时发生了过拟合现象,这证明理想的模型弱分析其数量为700~900个。
各分类等级指标详细统计数据见表2,不同降雨等级对应不同的精确度、召回率和F1-SCORE得分指标数据,表明对应的多层雷达回波数据的特征显著程度不同。
为了进一步验证研究工作的有效性,使用本文的XGBoost方法和当前常用的机器学习算法进行对比实验。比较的方法为Adaboosting,GBDT,Bagging三种集成学习算法。实验结果如图8所示。本文的XGBoost方法建立的基于多层雷达回波数据的降雨强度等级模型准确率为75.66%,高于其他对比集成学习模型,包括Adaboosting (72.59%)、GBDT (70.35%)以及Bagging (71.28%)。由此可见本文使用的XGboost模型较其他机器学习模型取得了较高精度,更适合进行气象分析,特别是降雨相关的分析预测。
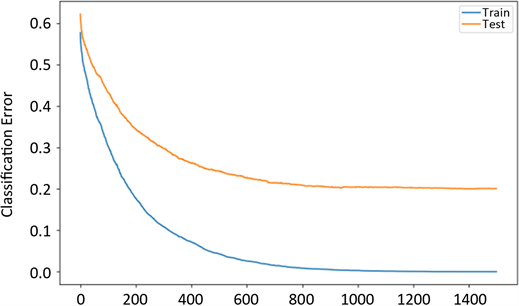
Figure 7. Relationship of iteration and error rate system result of standard experiment
图7. 迭代次数与错误率关系
Table 2. Each classification level index data
表2. 各分类等级指标数据
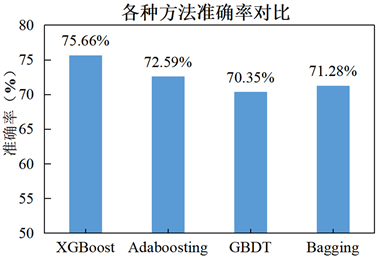
Figure 8. The accuracy of various methods
图8. 各种方法分析的准确率
4. 结论
使用多层雷达回波数据进行降雨分析预测时,本文尝试采用XGBoost方法进行分析,并构建了可用的分析系统。经过数据预处理、模型建立、超参数选取、模型优化等过程后,得到了较好的降雨值与降雨等级分类结果。此外,还比较了XGBoost方法与其他机器学习方法的分类结果,结果表明,XGBoost较主流的Bagging、Adaboosting、GBDT等方法,结果更贴近实际,这说明使用XGBoost方法进行降雨相关分析预测是可行的。