1. 引言
近年来,随着现代化进程的快速推进,空气质量问题(特别是雾霾问题)越发凸显,严重影响公众的身体健康 [1]。雾霾的主要成分是细颗粒物(Fine Particulate Matter, PM2.5),当其浓度越高时,说明空气的质量越差。PM2.5的体积小,需要较长时间才能在空气中消散,而且活性强,可吸附含有毒物质的污染物 [2] [3]。当PM2.5进入到人体后,会造成各种呼吸道病况的发生 [4] [5]。因此,有必要对PM2.5浓度进行准确预测,为环境治理人员和公众提供PM2.5浓度信息。
目前,作为一种随机增量学习方法,随机配置网络因其引入了监督机制对将要添加的隐含层节点进行筛选,使其具有强大的预测能力和极快的学习速度 [6] [7]。随机配置网络的构造分两步进行:1) 采用监督机制来随机生成一组隐含层节点,从中选择一个使当前网络具有最高精度的隐含层节点作为新增节点;2) 采用优化算法来确定整个网络的输出权值。因此,随机配置网络不仅结构简单、易于实现,而且具有较强的预测能力。因此,借助于随机配置网络,本文建立一种新型的PM2.5浓度预测方法,致力于构建一种结构简单、易于实现,且能够用于PM2.5浓度预测的方法。
2. 预备知识
随机配置网络
随机配置网络采用点增量的方式,即一个一个地添加隐含层节点的方式,来构建网络,直至达到事先设定的停止条件。其停止条件是指:根据运行系统内存的要求,同时考虑计算复杂性,设置最大的隐层节点和期望达到的预测精度,只要满足上述两个条件之一,就结束网络的构建。
随机配置网络的监督机制有如下形式:
(1)
式中,
为当前网络的残差,L为当前网络隐含层节点数,
,
,且
。
再添加完隐含层节点后,随机配置网络采用如下的权值更新算法来获得整个网络的输出权值 [8] [9]:
(2)
3. 基于随机配置网络的PM2.5浓度预测模型
本文选择来自于盐城市在2016年下半年到2017年下半年的空气检测数据来建立PM2.5浓度的预测模型。其中,将2016年下半年至2017年上半年的数据用于训练所提PM2.5浓度预测算法,剩余的数据作为测试集,来验证所提PM2.5浓度预测模型的预测能力。其他的空气质量指标还包括CO、NO2、O3、SO2、和PM10这5种污染物质。
3.1. 数据预处理
由于数据集中存在缺失值,不能直接用于模型的训练。数据集的处理方法一般有两种,一种是直接将缺失的数据删除,另一种是采用数据填补算法来补充缺失的数据。为了简单起见,本文采用数据删除法来处理缺失值。具体操作如下:
本文利用Matlab的 isnan函数来删除数据中的缺失数据,程序如下:
for i=size(Xtraino, 1):-1:1
if sum(isnan(Xtraino(i, :))) > 0
Xtraino(i, :)=[];
end
end
delete(' Xtrain.csv');
dlmwrite('Xtrain.csv', Xtraino, 'precision', 12);
其中,Xtraino为原始的训练数据,Xtrain为不存在缺失值的训练数据。部分原始训练数据如表1所示,删除缺失值之后的训练数据如表2所示。

Table 1. Some original training data
表1. 部分原始训练数据
Table 2. The corrected training data
表2. 部分不存在缺失值的训练数据
3.2. 数据的归一化
在建立PM2.5浓度预测模型之前,要对所有的训练数据集和测试数据集进行归一化处理。本文采用Matlab 的mapminmax函数对所有数据进行归一化,将其缩放到
区间内。具体操作如下:
[Xntrain,inputps]= mapminmax(Xtrain);
Xntest=mapminmax('apply',Xtest,inputps);
[Yntrain,outputps]=mapminmax(Ytrain);
Yntest=mapminmax('apply',Ytest,outputps);
其中,Ytrain,Xtest和Ytest分别为训练集的输出,测试集的输入和输出;Xntrain,Yntrain,Xntest和Yntest为归一化后的结果。
3.3. 训练集与测试集
每个时刻采集6个数据,将前两个时刻采集的12个数据作为输入,当前时刻的PM2.5的浓度作为输出。那么,经上述处理后,训练集包含8218个样本,测试集包含4018个样本,分别用于所建PM2.5浓度预测模型的训练和验证。
3.4. PM2.5浓度预测模型的实现
由前面内容可知,基于随机配置网络的PM2.5浓度预测模型从
开始添加隐含层节点,首先利用监督机制来指导隐含层参数的生成,在添加完隐含层节点后,再采用优化算法(2)来获得网络的输出权值。因此,基于随机配置网络的PM2.5浓度预测模型的构建分为两部分:隐含层节点的添加和输出权值的更新。
令
为训练模型的输入,则对应的模型的输出为
。给定两个空集
和W,用于存储监督机制所产生的隐层参数w和b。模型的具体实现步骤如下:
1) 隐含层节点的增加。首先在监督机制下随机配置一组隐层参数,若找不到满足监督机制的节点,则对监督机制的约束力度进行放松,即
,
,直至找到监督机制下的隐层参数为止。将获得的隐性参数存储于
和W中,再从中找出一组隐性参数,即
和
,使得当前模型具有最高的预测精度,并将其代入事先指定的激活函数,形成新增节点。
2) 输出权值的更新。在确定激活函数的随机参数后,需要对隐含层与输出层之间的连接权值进行更新。本文采用全局优化算法(2)来得到网络的输出权值。最后,重复步骤1)和2),直至到达设置的停止条件,模型建立完毕。
3.5. 模型参数选择
所建PM2.5浓度预测模型包含以下训练参数:
为模型训练设定的最大节点数;
为隐含层节点配置的次数;r为学习参数;
为网络容忍度;
为随机参数w (输入权值)和b (偏置)的选取范围,
为变化步长。另外,选择
为网络的激活函数。具体参数设置如下:
;
;
;
;
。
4. 模型验证
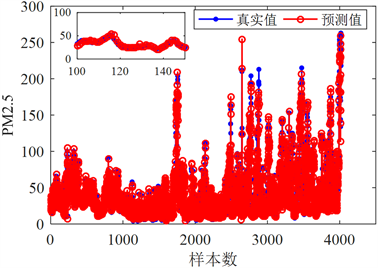
Figure 1. Prediction result of the PM2.5 based on stochastic configuration network
图1. 随机配置网络的PM2.5浓度模型预测结果
基于随机配置网络的PM2.5浓度模型的预测结果如图1所示。从图1可以看出,基于随机配置网络的PM2.5浓度预测模型的输出与真实的PM2.5浓度是基本匹配的,这说明本文所建PM2.5浓度预测模型具有较高的预测精度,可以用于实际中的PM2.5浓度的预测。
5. 结论
考虑到PM2.5对公众健康和空气监控的重要性,本文集成随机配置网络技术,建立了一种新型的PM2.5浓度预测模型。所建立的预测模型,结构简单,便于实现,具有良好的应用前景。然而,本文并没有将数据的时序特征和干扰考虑在内,以致模型的紧致性不够。未来的研究工作是引入时序鲁棒算法来提升预测模型的紧致性。