1. 引言
多数单领域推荐不能有效解决数据稀疏和冷启动问题,无法满足用户的需求,因此跨域推荐成为了推荐系统的热点之一。跨域推荐指通过把用户在领域A中丰富的反馈信息的知识迁移到用缺乏该用户反馈信息的领域B中进行商品推荐。因此,研究人员对于跨域推荐的研究多数是基于知识迁移上进行的 [1]。而在研究跨域推荐过程中,常用的反馈信息是评论文本 [2] [3],原因在于评论文本中蕴含着丰富的用户偏好信息和商品特征信息,适合进行知识迁移。
然而,现有的多数跨域推荐模型都是基于数据密集的领域向数据稀疏的领域进行知识迁移的方式进行单向推荐 [2] [3] [4],这些模型利用两个领域中的共同用户作为桥梁进行知识迁移,从而利用辅助域中的丰富信息来提高目标域的推荐效果,但这也意味着它们并没有利用目标域中的信息来帮助辅助域。然而,不同领域下的用户数据具有丰富性和多样性,如果可以同时利用这些用户的知识进行双向迁移,实现双向推荐,更能充分利用两个领域的知识,有利于缓解数据稀疏的问题。
基于上述问题,本文提出一种基于评论情感信息向量化的双向跨域推荐模型(Dual Cross Domain Recommendation based on Sentiment Vectorization of Reviews, RSCDR)。该模型利用bert [5] + Transformer [6] 的方式对每条评论文本中的情感信息进行文本情感向量化,并分别计算出用户偏好向量和商品特征向量;然后,利用潜在正交映射的方式同时对两个领域进行跨域推荐,即在两个领域中,利用正交映射函数将用户的偏好从域A中迁移到域B中(反之亦然)。最后,本文利用NFM [7] 进行评分预测。
2. 相关研究
单向跨域推荐的核心在于辅助域的知识如何迁移到目标域中。Xu等 [2] 认为利用评论文本中丰富的情感信息进行跨域推荐,能更好挖掘出用户偏好。因此,Xu提出了一种新型的情感信息提取模型,该模型通过自动识别用户评论的语义方向提取出评论文本中的情感信息,并利用多层感知机MLP [8] 将辅助域中的情感信息向目标域中迁移,从而进行跨域推荐。Fu等 [3] 利用扩展的堆叠降噪自编码器(SDAE) [9] 将多种辅助信息和评分矩阵进行融合,从而提取出不同领域下的潜在特征,再通过MLP来学习不同领域之间的特征映射。文献 [10] 利用情感分类器对不同领域的每条评论文本进行情感分类,并计算出两个领域内共同用户兴趣向量,再利用领域自适应网络分离出不同领域之间的共享的用户兴趣向量后再进行迁移的方法来进行跨域推荐。
对于多目标跨域推荐,多数文献利用两个领域中共同用户的共享特征进行跨域学习。文献 [10] 通过扩展DeepCoNN [11] 模型,提出了一种基于卷积神经网络(CNN) [12] 的多域产品推荐模型CCoNN,该模型利用多个域之间的公共用户评论信息生成用户偏好向量和项目特征向量,并在多任务学习(MTL) [13] 的基础上通过分解机(FM) [14] 对用户-产品对进行总体评级预测。Zhu等 [15] 认为利用丰富的用户反馈信息就有可能同时提高两个领域的推荐性能,而不是单一的目标域。为此,Zhu等提出了一种双目标跨域推荐模型来解决现有的单目标跨域推荐的局限性,该模型利用评分和评论文本信息生成用户和项目的评分和文档嵌入,并在多任务学习的基础上,设计了一种可适应的嵌入共享策略来组合共享跨域的公共用户嵌入,再利用NCF [16] 实现双目标跨域推荐,以用来提高推荐性能。而文献 [17] 提出了一种基于双重学习机制的跨域推荐的新方法,即利用潜在正交映射函数来提取不同领域中的用户偏好信息,同时保持不同潜在空间中用户之间的关系后,进行双向迁移,从而提高不同领域之间的推荐性能。
在文献 [10] 和文献 [17] 的研究基础上,本文提出一种基于评论情感向量化的双向跨域推荐模型。该模型利用情感分类的方法进行特征提取,并利用所提取的情感向量化计算出用户偏好和商品特征,再通过潜在正交映射函数进行双向跨域学习,从而预测出不同领域下用户对商品的评分。
3. 模型设计与分析
3.1. 评论情感信息向量化
用户在对商品进行评价时,给出的评分具有用户对商品的情感打分,而评论文本中往往包含着用户偏好信息和商品特征信息。评分的高低决定了用户对商品的喜爱程度,因此可以从评论文本中进行用户情感分析,从而挖掘出更深层次的用户偏好和商品特征。文献 [18] 提出了一种具有评论感知的推荐模型SentiRec,该模型将每个评论文本编码为固定大小的评论向量,并对评论向量进行训练以体现评论文本的情感。文献 [10] 参照SentiRec模型,利用word2vec [19] + CNN + 逻辑斯蒂回归的方式提取每一条评论文本的情感向量,再计算出对应的用户向量和商品特征。在文献 [10] 研究方法的基础上,本文利用bert+Transformer的方式挖掘出每条评论文本中隐含的用户情感向量。
多数电商平台把评分值设定在1到5之间,本文将情感阈值设定在3。本文利用评分值来为每一条评论文本添加一个情感标签:当评分大于或等于3时,对应的评论文本的情感标签为积极,而小于3时,对应的评论文本的情感标签为消极;然后,通过情感分类器将评论情感标签融入到评论文本向量中,生成特定的用户情感向量,最终获取到对应的用户偏好向量和商品特征向量。
bert模型具有多层Transformer [6] 结构,而Transformer是一种基于Attention机制进行特征提取的提取器。从图1中可以看出,Transformer Encoder的结构包括自注意力和前馈神经网络。首先。自注意力对整条评论文本的单词序列进行关注,并帮助模型对单词进行编码,获取到评论文本的上下文语义,再将数据输送到前馈神经网络中进行计算。本文首先通过bert模型将评论文本的单词转换为词向量,再利用Transformer为编码器的方式进行特征提取,并利用分类器进行情感分类。处理流程如图1所示:
文献 [6] 指出Transformer并不包含递归和卷积,因此Transformer为word embeddings添加了位置编码,用来识别序列中的单词顺序。本文利用正弦函数sin和余弦函数cos的线性变换来提供位置信息:
(1)
(2)
模型把从Tranformer解码器中提取到的特征向量输入到分类器中进行情感分类。然而,此时经过情感分类器得到的是每条评论文本的评论情感向量vectorui,文献 [10] 表明,用户和商品的关系存在一对多或多对多的,因此还需要将用户和商品对应的所有评论文本进行平均化,即:
(3)
(4)
其中,Iu表示用户u对所有商品进行过评论的集合,Ui表示对商品i进行过评论的用户集合。
通过上述方法,本文得到了两个不同领域中的用户偏好向量u和商品特征向量i,用来作为下一个模块的输入。
3.2. 基于NFM的跨域学习
本文设置的场景为两个领域存在相同的用户,他们都在两个领域中购买了商品。根据文献 [17] 的描述,如果两个用户在领域A中有类似偏好,那么他们在领域B中也应该存在着相似的偏好。因此,为了理解领域A中的偏好,可以将领域B的用户偏好和它们组合在一起,反之亦然。文献 [17] 提出在两个NCF模型上进行双重迁移学习推荐,利用潜在的正交映射,在源域和目标域之间同时迁移用户偏好,最终得到不同领域的用户评分。然而,交互特征对于用分评分预测是非常重要的,深入考虑稀疏的特征之间的交互,挖掘出交互特征的深层次含义,有助于提高模型的迁移能力,从而提高模型的性能。因此,基于该文献提出的潜在正交映射函数的方法上,本文利用NFM模型进行评分预测。
框架如图2所示,rwithin表示域内学习,用于预测目标域的用户偏好。rcross表示通过利用潜在正交映射函数对源域用户进行操作,捕获不同领域的差异性。因此,两个领域的最终评分定义为
(5)
(6)
其中,α表示两个NFM模型在预测用户偏好方面的相对重要性。
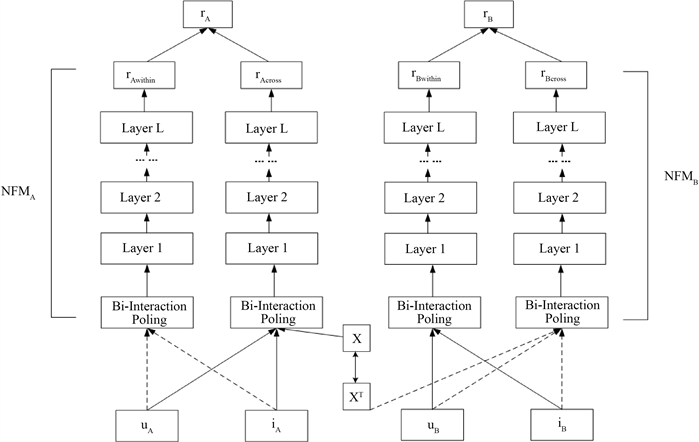
Figure 2. Potential orthogonal mapping on NFM model
图2. NFM模型上的潜在正交映射
用户评分的预测是基于文献 [7] 提出的NFM模型,NFM模型因为在embedding层和MLP网络之间添加了一个特征交叉池化层,从而能提取到深层次的交互特征。
对于NFM的embedding层,本文直接把上一节中计算得到的用户偏好特征u和商品特征v充当网络输入的嵌入向量。本文通过相乘的方式来组合这两个特征,定义如下:
(7)
NFM模型的定义公式如下:
(8)
其中,x表示两个特征组合成的交互特征,w0表示全局偏差,
表示交互特征i的值,wi表示潜在特征向量的系数,ƒ(x)代表Bi-Interaction pooling,一个多层前馈神经网络,其公式定义如下:
(9)
而在Bi-Interaction pooling之上是一堆连接层,用于学习特征之间的高阶交互,从而获的更深层次的特征交互。NFM模型的评分预测公式如下:
(10)
其中,L表示隐藏层数,Wl、bl、σl分别为第l层权重矩阵、第l层偏置向量和第l层激活函数。
3.3. 损失函数和目标函数
在评论文本情感向量化中,本文利用交叉熵损失函数作为整个情感分类器的损失函数,该公式定义如下:
(11)
而基于NFM的跨域学习中,根据文献 [17] 描述,设VA、VB分别为评分矩阵,则模型的目标函数可以定义为:
(12)
其中,
、
分别表示公式(6)和(7)。
4. 实验方案与结果分析
4.1. 数据集
本文选择的数据集是公开的Amazon数据集 [20],该数据包含不同类型的领域。本文选取了以下5个商品域中进行实验(表1),分别为Movies_and_TV (Movie)、Books (Book)、Apps_and_Android (Android)、Toys_and_Games (Toy)、CDs_and_Vinyl_5 (Music)。由于Movie、Book和Music数据集过大,因此本文对着三个数据集进行数据筛选。比如,在“Movie-Book”数据中,先筛选出商品数大于或等于150的商品,再从中筛选用户数大于或等于15的用户。
4.2. 数据预处理和参数设计
bert预训练模型中使用的是Transformers提供的Bert-base-uncased,它的结构是12层的Transformers,输出层维度为512层,隐向量的维度为32。另外,本文将所有数据集按照8:1:1的比例划分为训练集、验证集和测试集。学习速率设为0.002,dropout设为0.5,优化器为Adam。
4.3. α的取值
由公式(6)和(7)可得,α的取值影响整个模型的性能。α表示指引两个领域中用户偏好的重要性。因此,α取适宜数值才能让模型发挥更好的作用。文献 [17] 表明,α取0到0.2之间的正值,模型的效果最好。但根据图3实验结果,本文模型在这个取值范围得到的结果并没达到最好的效果,原因可能在于模型不同、收敛性不同、数据集稀疏程度不同等。因此,本文将α的取值分别设置为0.03,0.1,0.3,0.5,0.7,0.9,并进行对比,从中挑选出α值,使得模型效果最好。
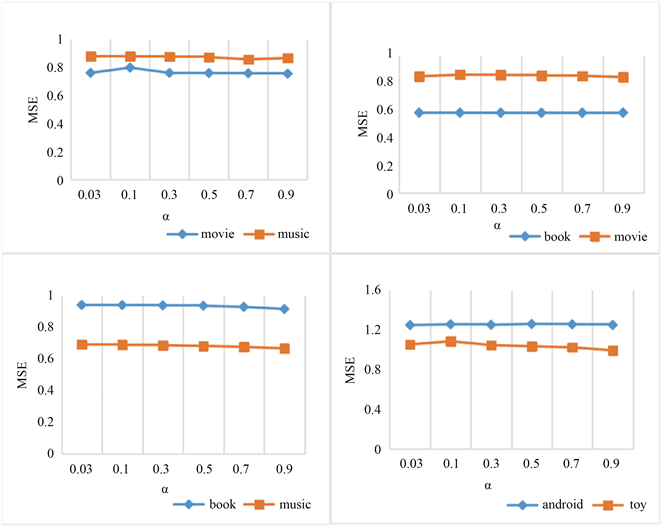
Figure 3. MSE values in different parameter α
图3. 参数α对MSE值的影响
图3显示了不同α值对模型性能的影响,通过观察四个表的MSE可以发现,α对不同的数据集的影响是不相同的,经过多次实验发现,当α = 0.9时,模型的性能较好。因此,本文将α的值设为0.9。
4.4. 对比模型
本文采用均方误差MSE作为评价指标,MSE值越低表示模型的性能越好,其公式如下:
(11)
其中,N表示样本个数,
表示在模型中获得的预测评分,
表示可以真实评分。
本文选取了以下几个基线模型进行对比分析:
1) FM:一种基于矩阵分解的模型,可以解决由数据稀疏引起的特征组合问题。
2) NFM:在FM模型上,引入Bi-Interaction pooling进行评分预测。
3) DDTCDR:该模型在NCF模型的基础上利用潜在正交映射进行跨域推荐。根据文献描述,在α取0到0.2之间的正值,模型的效果最好。在该模型中,本文把α值设为0.03。
所有模型的嵌入向量来自评论情感向量化生成的用户偏好特征和商品特征。
另外,FM、NFM模型部分代码参考文献 [21]。
4.5. 实验结果和分析
在四组数据集上进行实验分析,粗体表示该组数据集中得到的最优结果。
如表2所示,从总体上看,相对于其他模型,本文模型的性能效果较好。

Table 2. Comparison of the effects of each model in different datasets
表2. 各模型在不同数据集中的效果比较
FM模型和NFM模型进行对比,可以发现NFM模型在特征提取的能力比FM强。将FM模型和RSCDR模型进行比较,可以观察到RSCDR的性能提升不少。
RSCDR模型基于NFM模型,通过进行对比,RSCDR在三个数据组中取得最优结果,在“Movie-Book”实验组中,RSCDR模型和NFM模型在Movie数据集结果相差很小,但在同组的Book数据集中,RSCDR模型比NFM提高了2.1%。同时,在“Movie-Music”数据组中,RSCDR分别提高0.64%和1.48%,在“Book-Music”和“Android-Toy”数据组中,RSCDR比NFM模型分别提高了2.33%、2.61%、0.74%和2.16%,由此可见,利用潜在正交矩阵进行跨域推荐RSCDR模型能够有效解决推荐系统中数据稀疏的问题。
DDTCDR模型与本文模型最为相似,都是利用了潜在正交矩阵进行跨域映射,进行双向推荐。但从本文实验结果上看,只有在“Android-Toy”数据组的Toy数据集中,RSCDR模型的性能比不上DDTCDR模型,但在其余三组数据组中,DDTCDR模型取得的效果并不明显,RSCDR的MSE值均能比DDTCDR要低。因此,在本实验中,从总体上说明基于NFM的RSCDR模型能有效挖掘出交互特征的深层含义,能够提高跨域推荐的性能。
5. 结束语
本文利用情感分类器对不同领域的评论文本中的情感进行分类,将评论进行情感向量化,并从中计算出用户偏好特征和商品特征,并在NFM模型上利用潜在正交函数进行双向迁移,实现双向跨域推荐。通过实验证明该模型的在跨域推荐上具有较好的效果。因此,在下一步工作中,可以深入研究,不同特征提取方式对潜在正交映射的影响。
基金项目
广东省科技厅项目(2016A070708002, 2015A070706001, 2014A070708005);研究生教育创新计划(2016SFKC_42, YJS-SFKC-14-05, YJS-PYJD-17-03)资助;教育部“云数融合、科教创新”基金项目(2017B02101);江门市基础与理论科学研究类科技计划项目(2017JC01021)资助。