1. 引言
随着相机、手机等硬件设备的发展,需要后期处理的图像也越来越多。但由于图像具有多样性与复杂性,无论传统图像处理方法还是深度学习方法,都难以做到对任何输入完全鲁棒。所以,针对特定类别的图像抠图算法 [1] 更具有实际应用意义。
人像抠图是语义分割 [2] [3] 的一种,是从图像或者视频中提取出人像前景,使人像与背景准确分离的一种技术。该技术在现实中有着广泛的应用,比如虚拟现实、增强现实、电影制作和摄影合成,这些应用主要基于图像合成技术。在图像合成技术中,通过人像抠图技术可以得到所需要的mask,mask中每一个像素点的值表示了原始图像每个像素是否属于人像前景,其精度直接影响合成图像质量的优劣。
对于图像I,人像抠图旨在找到人像前景F与背景B的最佳线性组合。对于任意的像素点i,可以满足以下公式:
(1)
其中Ii为图像I的像素点i,αi表示在像素点i的前景不透明度。对于RGB图像,有7个未知变量:
,
,
,
,
,
,
,而已知变量仅有3个:
,
,
。由于已经变量远小于未知变量,因此需要用户提供额外的先验知识才能求解,所以多数图像抠图算法 [4] [5] [6] [7] 利用三分图(trimap)作为先验知识,再进行图像抠图任务。比如Cho [8] 等人结合了CF抠图 [9] 与KNN [5] 抠图两种方法,以两种方法的输出和RGB图像作为CNN网络的输入来学习图像与mask的映射关系。Xu等人 [10] 用RGB图像与三分图来输入并集成了编码解码器结构和细化网络来预测mask。Lutz [11] 等人则使用生成式对抗网络进行图像抠图任务。三分图是用户指定一部分已知的前景区域与已知的背景区域,然后求解未知的区域α。然而这个方法需要用户有一定水平的专业知识而且可能需要很长的时间才能得到满意的效果。因此近年来有学者尝试舍弃三分图作为先验知识并以端到端的方式学习图像与对应的mask之间的映射关系。比如Chen [12] 等人从图像中学习隐性语义约束而不是用三分图或者涂鸦等先验知识来生成mask。Liu等人 [13] 利用粗糙注释数据与精细注释数据相结合的方法,在不使用三分图的情况下,实现端到端的mask生成。但是这些方法在远景人像抠图中并不能达到满意的效果,原因有三个,首先是远景容易出现多余的干扰信息、其次是人体边缘轮廓的细化,最后是人体的携带物体容易与背景进行混淆。
因此,本文自制了远景人像数据集来进行实验。并提出了人像抠图无监督语义精修算法对mask进行语义精修。为了验证算法的效果,本文以SHM算法作为基线,并加上人像抠图无监督语义精修算法进行对比实验分析,表明了本文算法的优越性能。本文贡献如下:1) 为了去除人像背景噪音,结合了行人检测模型并提出了人像边框感知算法。2) 把无监督语义分割网络应用于人像抠图,并提出了人像精修模块来细化人体边缘轮廓和分离背景与人体携带物。3) 自制了远景人像抠图数据集,并使用充足的实验验证了算法的有效性。
2. 人像抠图无监督语义精修算法
由于使用当前主流的人像抠图模型对远景人像进行人像抠图得到的mask存在噪音以及语义缺失问题。针对这些问题,本文提出了人像抠图无监督语义精修算法,该算法可以对人像抠图后的mask进行图像去噪和语义精修。算法如图1所示,由人像边框感知模块与无监督语义精修模块组成。人像边框感知模块通过行人检测模型与人像边框感知算法对输入的mask进行去噪。无监督语义精修模块则通过无监督语义分割网络并结合人像精修算法对去噪后的mask进行语义精修,得到更为精细完整的人像抠图。
2.1. 人像边框感知模块
如图1中的人像边框感知模块所示,人像边框感知模块的输入为RGB图像和mask,首先使用行人检测模型 [14] 对RGB图像进行行人检测,得到人像边框
,其中
表示人像边框左上角的坐标,
表示人像边框右下角的坐标。随后,使用人像边框感知算法对边框B进行修正并同时对mask进行去噪。如图2所示,该算法主要分为两个部分:人像边框内的修正算法与人像边框外的噪音去除方法。人像边框内的修正算法用于边框B没有完全框住人像的场景,该算法可以对人像边框B进行修正以达到完全框住人像的目的。
如图2(a)所示,行人的乐器在行人检测模型没有检测出来的情况下,人像边框内的修正算法可以很好地进行边框修正。具体实现方法如算法1所示。在得到完整的人像边框后,本文使用人像边框外噪音去除方法进行去噪。如图2(b)所示,该方法只保留面积最大的人像边框内的前景信息,并把该边框之外的前景信息设为背景信息,以去除人像背景的噪音。
算法1. 人像边框内的修正算法
Input:
表示人像边框,mask表示透明度遮罩。
Output: B'表示修正后的人像边框。
1) initialize set
2) for
to x2 do
3) while
4) do
end
5) while
6) do
end
7) end for
8) for
to y1 do
9) while
10) do
end
 (a) 人像边框内修正算法 (b) 人像边框外修正算法
(a) 人像边框内修正算法 (b) 人像边框外修正算法
Figure 2. Portrait border sensing algorithm flow chart
图2. 人像边框感知算法流程图
11) while
12)do
end
13) end for
14)
2.2. 无监督语义精修模块
如图1中的无监督语义精修模块所示,该模块包括无监督人像语义分割网络与人像精修算法,它的输入为人像边框感知模块的输出和RGB图像,输出为精修后的mask。
无监督语义分割网络 [15] 如图3所示,输入RGB三通道图像P,表示为
,其中N为像素点的个数。每个像素点先正则化到[0, 1]区间内,再使用无监督聚类算法f对图像P的像素点进行语义预分类,分成k类,即
,yn是一个1 × k的矩阵,该矩阵元素为1的下标即为该像素点n的类别。给每个像素分配标签后,卷积神经网络可以根据该标签实现无监督学习。该网络包括特征提取部分与特征分类部分。特征提取部分由M个特征提取块组成,特征提取块包括卷积层,批归一化层(BN)和线性激活层(ReLU),其中在卷积层上使用的是3 × 3的卷积核。
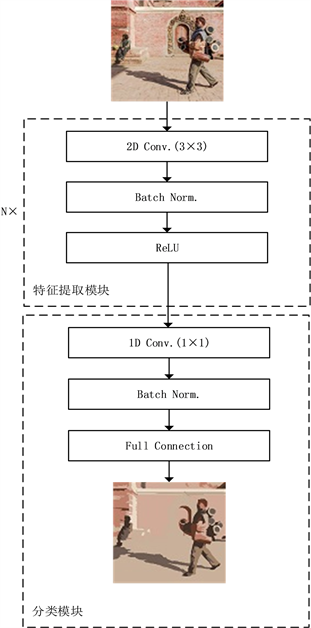
Figure 3. Unsupervised portrait semantic segmentation network
图3. 无监督人像语义分割网络
(2)
其中
为第i个特征提取块的输出。批归一化层可以使输入到ReLU的图片接近正态分布。特征分类部分由使用1 × 1卷积核的卷积层,BN层和全连接层组成。
(3)
其中G为
维的矩阵。最后网络的训练需要计算矩阵G与标签Y的损失,本文使用Softmax Loss作为损失函数。
(4)
RGB三通道图像经过无监督人像语义分割网络后每个像素点被分为q类。相同类别且连续的像素点构成区域Pk,其中
。人像精修算法的核心在于统计mask在每个区域Pk中前景与背景的个数,本文把像素点为黑色设为背景,像素点为白色设为前景。如果mask在区域Pk中前景的数量与背景的数量的比值大于θ,则把mask在区域Pk中的值都设置为前景的值,如果前景的数量与背景的数量的比值小于
,则把mask在区域Pk中的值都设置为背景的值。其中θ为超参数。该算法可以修改mask中的属于背景信息的前景信息,同时可以细化人像及携带物品的边缘轮廓。
3. 实验设计及结果分析
3.1. 实验准备
由于目前人像抠图数据集大多为半身人像图片,因此本文自制了一个远景人像数据集来进行实验设计与分析。该数据集的图像均采集于互联网,而且大多选择人像前景与背景变化较小的并且有携带物体的图片。数据集共有2000张图片,分辨率为1920像素 × 988像素,标注内容包括2703个行人目标框,2000张mask图。本文将该数据集按8:1:1分为训练集、验证机、测试集。因此随机抽取1600张图像所为训练集,200张图像作为验证集,200张图像作为测试集。
本文的实验环境:ubuntu16.04操作系统,Intel i7中央处理器,1 TB固态硬盘,32 GB内存,NVIDIA GTX2080Ti GPU × 2,并使用Pytorch深度学习框架进行训练。
3.2. 实验结果与分析
由于SHM算法是在人像抠图任务中率先舍弃用三分图作为先验知识的算法,并且是广泛使用的人像抠图算法,因此本文选择把SHM算法当作基线进行对比实验分析。
本文采用2个广泛使用的评价指标进行评测,分别为均方误差MSE (mean-square error)和绝对误差SAD (sum of absolute differences)。这2个指标的值越低表示效果越好。公式如下:
(5)
(6)
其中xi为实验获得的图像;yi是ground true图像。
在人像边框感知模块的实验中,本文使用YOLOv3算法 [14] 在自制数据集上训练行人检测模型。对输入图片进行行人检测得到人像边框后,使用人像边框感知算法对标签图片进行去噪。
在无监督语义精修模块的实验中,迭代次数为500,学习率设为0.0001,并选用Adam算法 [16] 作为优化器进行优化。对于不同的超参数θ,在表1中展示了使用Felzenszwalb算法 [17] 和SLIC算法 [18] 作为无监督聚类算法的实验效果,评价指标为使用语义精修算法后与使用之前降低均方误差。

Table 1. The results of two pre-classification algorithms in different hyperparameters θ
表1. 两种预分类算法在不同超参数θ的实验结果
该数据显示,使用Felzenszwalb算法在θ为0.7的时候,实验效果最好,MSE平均降低0.0075。因为Felzenszwalb算法相比于SLIC算法,对于变化幅度小的照片,能很好地处理细节;对于变化幅度大的照片,也能很好地忽略一些细节。同时发现当θ取值0.6时,MSE降低最少,因为在区域Pk中前景与背景像素点数量的比值相差较小的话,改变前景或者背景的值可能会得到错误的结果。而当θ取值较大时,很有可能会忽略一些本应该改变的前景(背景)像素点。
为了验证人像抠图无监督语义精修算法(SHMR)在远景人像数据集的性能效果,在表2展示了具体的实验数据,该实验是预分类算法使用Felzenszwalb算法,θ取0.7时,在有无人像抠图无监督语义精修算法(SHMR)的情况下,用SHM算法的实验效果,可以看出在加上了SHMR算法后效果得到了明显的提升。
Table 2. Comparison of experimental results in the perspective portrait dataset
表2. 在远景人像数据集中的对比实验结果
为了验证在远景人像数据集中人像边框感知模块以及无监督语义精修模块的作用,本文进行了消融实验。如表3所示,在只使用人像边框感知模块的情况下,效果也有一定的提升。但是只使用无监督语义精修模块,效果反而变差,原因是在没有完全去除环境噪音的情况下使用无监督语义精修模块,会让噪音放大,使实验效果变差。
Table 3. Results of two module ablation experiments
表3. 两个模块消融实验的实验结果
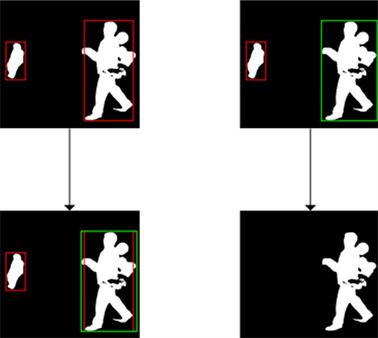
图4为在远景人像数据集中,使用SHM算法进行人像抠图以及SHM加上SHMR人像精修算法的实验效果图。可以看出,在有行人的环境中,SHM算法容易产生额外噪音,而本文提出算法的人像边框感知模块可以很好地去除噪音。在人像有携带物的情况下,人像整体也难以识别出来,在引入无监督语义精修模块后,人体携带物体也能准确识别,人像边缘轮廓也更加清晰。

Figure 4. Experimental renderings in the perspective portrait dataset
图4. 在远景人像数据集的实验效果图
为了验证SHMR人像精修算法的泛用性能,本文同时在半身人像抠图数据集进行实验分析。使用的数据集为爱分割(aisegment.com)高质量标注并开源的人像抠图数据集。该数据集包含34,427张图像和对应的matting结果图,分辨率为600像素 × 800像素,超参数的设置与远景人像数据集相同。表4展示了在半身人像数据集中的对比实验结果。
Table 4. Comparison of experimental results in the data set of half-length portraits
表4. 在半身人像数据集中的对比实验结果
由表4可以看出,在半身人像数据集中,加入SHMR算法后效果同样得到提升,但是MSE的降低并没在远景人像数据集中那么多,原因是:在远景人像数据集中存在很多环境噪音,由于SHMR有人像边框感知模块,环境噪音可以得到去除,最后再进行人像边缘的精修。然而在半身人像数据集中,环境噪音非常少,主要侧重了人像边缘的精修,所以MSE的降低并没有在远景人像数据集中那么多。
图5为在半身人像数据集中,使用SHM算法进行人像抠图以及SHM加上SHMR人像精修算法的实验效果图。对比远景人像数据集的实验可以看出,半身人像数据集中环境噪音明显大幅度减少,并且主要侧重于人像轮廓的修复。而加入SHMR人像精修算法后人像轮廓修复得更加完整清晰,这也验证了该算法的泛用性。

Figure 5. Experimental renderings of the bust portrait data set
图5. 在半身人像数据集的实验效果图
4. 结束语
本文针对远景人像抠图存在噪音、人体边缘轮廓粗糙、人体携带物易与背景混淆等问题,提出了人像抠图无监督语义精修算法。通过人像边框感知模块进行去噪并使用无监督语义精修模块优化细节,以达到人像前景与背景完整分割的目标。实验表明,在远景人像数据集中,在主流的人像抠图算法中加入人像抠图无监督语义精修算法后,效果有明显的提高,并且在半身人像数据集中,效果也有一定的提高。但由于本文将去噪模块与精修模块分割开来,也会导致误差的传递,接下来将针对端到端的人像抠图精修算法展开研究。