1. 引言
在回归问题中,我们常遇到数据具有噪声或离群值的问题,即样本中的个别值其数值明显偏离它所属样本的其余观测值。一般情况下离群值产生的原因可以分为两大类:人为原因和自然原因。比如输入的时候多输入了一个0发生了错误,使得原本的年薪5万变成了50万,这是人为原因。一个年级前10名学生的成绩远远高于其他人,且这些数据没有任何错误,这是自然原因所导致的离群值。这些离群值的出现会增加误差,降低统计检验的能力,可能对具有实质性意义的估计产生偏见或影响,还会影响回归、方差统计和其他模型的基本假设。因此在数据有离群值扰动的情况下,我们要采用对离群值鲁棒的统计方法来分析数据。所谓的鲁棒性是指一个系统在受到扰动的情况下仍然能保持其功能。本文主要研究回归问题中的鲁棒性问题,我们将提出一个新的鲁棒的损失函数来提高回归算法的鲁棒性。
假设数据由下列模型生成:
,
, (1.1)
其中
为解释变量,
为可分度量空间,
为响应变量。回归问题旨在通过模型(1.1)生成的观测值来训练
的一个估计
。假设
上的概率分布为
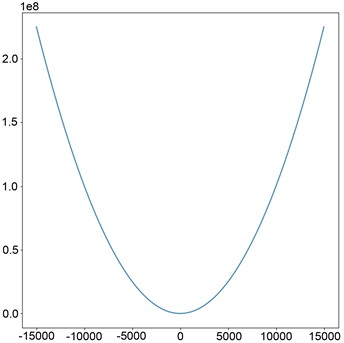
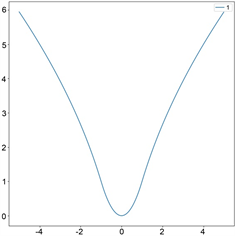
。在回归模型(1.1)下,量化估计函数f回归效率的最常用的损失函数是均方误差。均方误差也称L2损失,如图1(a),它是一种常用的损失函数,其定义如下:
。 (1.2)
基于L2损失的回归算法的缺点是其最优性在很大程度上依赖于高斯假设。而在许多实际应用中,数据往往比较复杂,可能会被非高斯噪声或离群值污染,若在这种情况下使用对离群值不鲁棒的损失函数,则可能使整个统计分析无用 [1]。因此为了克服L2损失不鲁棒的特性,我们需要引进鲁棒的损失函数。
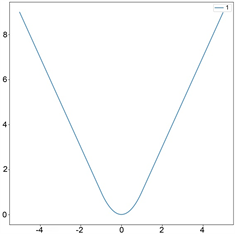
平均绝对误差也称L1损失,如图1(b),是另一种用于回归模型的损失函数,其定义如下:
。 (1.3)
L1损失比L2损失更具鲁棒性,但它的中心点是折点,因此不能求导,从而不易于求解。
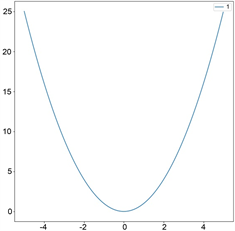
P. J. Huber等 [2] 在1964年提出了Huber损失函数,如图1(c),其定义如下:
(1.4)
其中
是一个非负参数,用来控制损失函数二次与线性的范围。当残差大于等于
时采用L1损失,残差小于
时采用L2损失。Huber损失函数结合了L1损失和L2损失的优点,它对离群值比L2损失更鲁棒,同时在中心点处可导。R. Girshick [3] 在2015年采用Smooth L1损失函数在Fast R-CNN上取得了很好的效果,Smooth L1是Huber损失中
的特殊情况。
冯云龙等 [4] 在2015年提出了基于最大相关熵 [5] 的MCCR损失函数,如图1(d),其定义如下:
, (1.5)
其中
是一个非负的尺度参数。该损失函数对带非高斯噪声的回归问题有帮助,对高斯噪声也能取得很好的表现。
 (a)
(a) 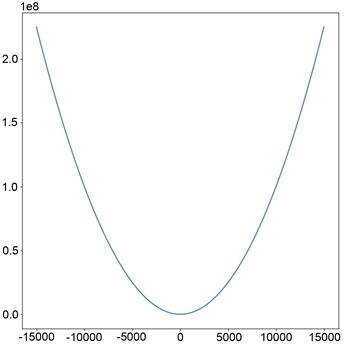 (b)
(b) 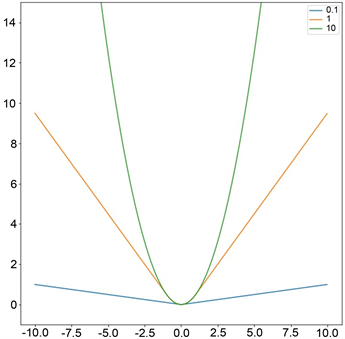 (c)
(c) 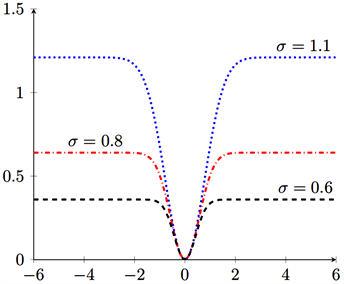 (d)
(d)
Figure 1. Diagram of four loss functions
图1. 四种损失函数示意图
本文为进一步提高回归算法的鲁棒性,提出了一种新的基于Huber损失函数的非凸鲁棒损失函数p-Huber损失,该损失函数由参数p和
控制。具体定义和性质在第二节中讨论。在第三节中,我们对采用p-Huber损失的模型进行仿真实验,并与L1、Huber、MCCR三种损失函数从预测效果等方面进行了比较。
2. p-Huber损失函数及回归算法
2.1. p-Huber损失函数
在Huber损失函数的基础上我们提出了如下新的非凸鲁棒损失函数p-Huber回归损失,其定义如下:
(2.1)
其中p和
是两个非负的参数。当
时,损失函数与Huber损失函数相同(只相差一个常数系数)。当
时,损失函数与经典的L2损失相同。
如图2(a)所示:参数p主要控制 -Huber损失函数的凹凸性,当
时图像为非凸,当
时图像为凸,本文主要研究
时非凸的情况。图2(b)显示参数
主要控制p-Huber损失函数的拐点。p-Huber损失函数桥接了L2损失函数和鲁棒性损失函数。
,
,
,
(a)
,
,
,
(b)
Figure 2. Diagram of different parameters of p-Huber loss
图2. p-Huber损失不同参数示意图
2.2. 基于p-Huber损失的学习算法
给定一个容量为m的独立同分布的样本
,对于任何估计
,其在样本点上导致的经验误差为:
。
本文考虑下列经验风险最小化学习算法:
, (2.2)
其中假设空间
是
的紧子集。
是以
为范数的所有定义在
上的连续函数的巴拿赫空间。
的紧性可保证估计函数
的存在性。模型(2.2)是一个带约束的最小化问题。当
取成由Mercer核
生成的某个再生核希尔伯特空间 [6]
的有界子集时,模型(2.2)和下列不带约束的正则化学习算法是等价的:
, (2.3)
其中
是非负的正则化参数,用以防止算法发生过拟合。
表示定理 [7] 告诉我们只需要在以下函数集中最小化模型(2.3):
,
这里b是一个偏移量。在第三节仿真实验中我们采用如下高斯核:
,
其中参数h是待定的高斯核的尺度参数。
3. 仿真实验
3.1. 实验平台及噪声介绍
软件环境:
操作系统:Windows 10家庭版x64位
开发工具:Python 3、Matlab 2015b
硬件环境:
处理器:Inter i7-6700HQ@2.60 GHz
内存:8 GB
在我们的实验中,按如下方式添加噪声:
, (3.1)
其中
遵循标准高斯分布,
是一个脉冲噪声(离群值),定义如下:
这里引入
和
来设置高斯噪声的方差和脉冲噪声的大小。在我们的实验中,我们始终设置
,即10%的样本被脉冲噪声污染。
3.2. 辛格函数下的评估
为了展现p-Huber损失函数的有效性,我们将其预测精度分别与L1损失、Huber损失、MCCR损失进行比较。首先我们选择辛格函数作为回归函数。辛格函数 [8] [9] 经常被用来举例说明回归函数。一维辛格函数的表达式如下,图像见图3。
。 (3.2)
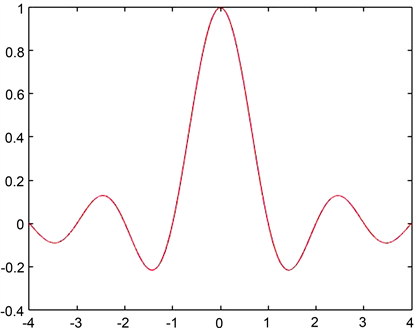
Figure 3. One-dimensional Sincfunction graph
图3. 一维辛格函数图像
在实验中,首先从被高斯噪声破坏的辛格函数中抽取规模大小为100的训练集,然后我们抽取了另一个同样规模的被高斯噪声和离群值污染的训练集。在每个训练集上对辛格函数的拟合结果绘制在图4和图5中,其中黑色实线表示辛格函数,被高斯噪声污染的训练集用加号来表示,离群值用正方形来标记,橙色虚线代表p-Huber拟合的曲线,红色虚线代表MCCR拟合的曲线,蓝色虚线代表Huber拟合的曲线,绿色虚线代表L1拟合的曲线。
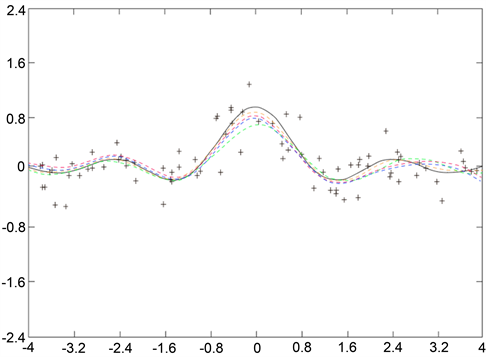
Figure 4. The fitting effect diagram of different models to the Sinc function when contaminated by Gaussian noise
图4. 高斯噪声污染时不同模型对辛格函数的拟合效果图
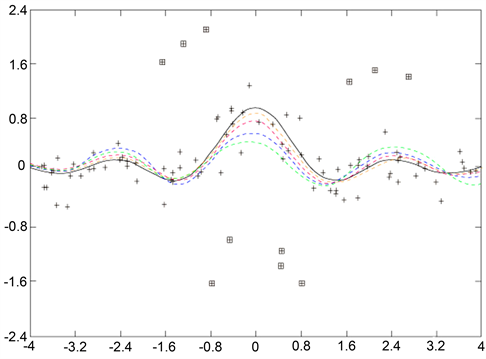
Figure 5. The fitting effect diagram of different models to the Sinc function when contaminated by Gaussian noise and outliers
图5. 高斯噪声和离群值污染时不同模型对辛格函数的拟合效果图
从图4中我们可以看出,当数据仅受高斯噪声污染时,这四个模型都能很好的拟合函数图像。从图5中我们可以看出,当数据受到高斯噪声和离群值的污染时,这四个模型都能成功拟合曲线,但是p-Huber拟合效果最好。
下面我们通过实验来分析在加入噪声和离群值的情况下p-Huber损失函数的参数p和
对算法的影响。经过数值实验,对于拟合结果我们绘制了如下表格。在表格里,我们记录了数据集的平方误差相对和,其定义如下:
, (3.3)
其中
表示
在数据集T上的均值。

Table 1. When δ = 0.7 , different values p predict the result of Sinc function
表1.
时,不同的取值p对辛格函数预测的结果
Table 2. When p = 2.53 , different values δ predict the result of Sinc function
表2.
时,不同
的取值对辛格函数预测的结果
表1显示当固定
时,随着参数p的变化,实验拟合效果也不相同,这说明参数p对鲁棒性有影响。表2显示当固定p时,随着参数
的变化,实验拟合结果几乎相同,这说明参数
对鲁棒性几乎没有影响,
主要用来控制损失函数的拐点。
3.3. 弗里德曼基准函数下的评估
我们接下来考虑多维回归问题,选择了弗里德曼基准函数作为回归函数。弗里德曼基准函数 [10] 在研究回归问题时已被广泛采用,其定义如下:
;
;
。
对于
,
,其中
服从
上的均匀分布,
是噪声变量。对于
和
,
的每个坐标分别服从下列区间上的均匀分布:
,
,
,
。
对于每个函数,我们随机抽取1000个观测值进行训练和交叉验证,另外随机独立抽取1000个观测值作为测试集,然后根据(3.1)的方法添加噪声和离群值,一组加入了高斯噪声,另一组加入了高斯噪声和离群值。对于
我们设置
。对于
和
,设置
使得信号功率与
功率之比为3。对于无离群值的情况下,我们设置
。对于训练集中存在离群值的四个模型,我们设置
,其中D是每个基准函数的定义域。对于每个回归模型,都通过均方误差下的10倍交叉验证对高斯核的宽度h,正则化参数
和损失函数中的比例参数(LAD损失没有比例参数)进行了调整。我们将其残差
都记录下来。对于每个回归模型,其平方误差相对和记录在表3。
Table 3. The prediction results of different models on Friedman’s benchmark function
表3. 不同模型对弗里德曼基准函数的预测结果
表3中我们可以看出,当数据仅受到高斯噪声污染时,这四个模型都能很好的拟合。但当数据被离群值破坏时,所有四个模型虽然仍能拟合,但是 -Huber拟合效果相比其它三个更优。
3.4. 真实数据集下的评估
本节中我们用四个真实数据集对p-Huber损失的拟合效果进行评估。这四个真实数据集中一个来自2018年12月至2019年12月股票交易历史数据,另外三个来自机器学习数据集中的UCI数据集:Airfoil Self-Noise数据集,Concrete Compressive Strength数据集,Yacht Hydrodynamics数据集。
我们将2/3数据用作了训练,其余用作测试,并多次实验,其准确性由平方误差相对和来测量。实验结果记录在表4,其中包含了数据特征的大小d和数量m。
Table 4. The prediction results of different models on real data
表4. 不同模型对真实数据的预测结果
表4显示在上述四个真实数据集中,基于p-Huber损失函数的学习回归算法的表现要优于其它的方法。
4. 结语
在本文中,我们提出了一种新的鲁棒损失函数p-Huber损失函数。通过选取不同参数,对p-Huber损失函数进行了图像和性质分析。为了说明p-Huber损失函数的有效性,我们分别在辛格函数,弗里德曼基准函数和真实数据集下进行了实验。
时p-Huber损失函数为非凸函数,通过跟其他常见损失函数进行比较,结果显示基于p-Huber损失函数的回归学习算法在有离群值的情况下其预测效果要优于常见的损失函数的预测效果,其更具鲁棒性。