1. 引言
从目前我国的经济发展来看,无论哪个方面的经济发展都在不断与国际接轨,股票市场作为社会主义市场经济发展的产物,也在慢慢走向国际化,人们对股票市场的关注度也越来越高,很多投资者也都纷纷加入到股票投资市场,期望给自己带来更多的收益,所以对于股票投资者来说,预测股价走势是很有必要的,这样才能够帮助投资者选择最佳投资时机,获取最高的利益,对于机构而言也是如此,从更高层面来看,也促进了我国市场经济的发展。
精准的预测股票的价格是较为困难的,是预测研究中的一大难题,相关学者经过不断的研究与创新,提出并建立了较为精确的预测股票价格模型如:吴玉霞,温欣 [1] 通过利用时间序列中的ARIMA模型,将“华泰证券”250期的股票收盘价作为实证数据来进行建模,由结论可知ARIMA模型在短期预测中,无论是动态预测还是静态预测效果都较好;贺本岚 [2] 利用时间序列常用的两种短期预测模型ARIMA和ARCH模型,并用这两种模型来预测上证指数的收盘价,对预测结果进行对比得出预测效果较好的是ARCH模型;陈小玲 [3] 分别利用ARIMA和BP神经网络对股价进行预测研究,将百度和阿里巴巴这两支股票的收盘价作为实证分析数据,结论表明两种模型在股价短期预测中是可行的。
单一预测模型在某些情况会存在一定的局限性,预测结果的精度和准确性较差,因此在1969年Bates和Granger [4],首次提出了用组合的方式将单一模型结合起来,也即是提出组合模型这一概念,该理论自提出以来,一直持续引起国内外学者的广泛讨论和关注,由于通过组合的方式能够大幅度地提高模型的准确性和预测精度,所以很多学者都对此进行了相关理论研究和实例验证。翟静,曹俊 [5] 在组合模型预测的大环境之下,通过方差倒数法将ARIMA模型和BP神经网络算法结合在一起对我国的粮食产量进行预测研究,得出组合模型的预测准确度比只用时间序列ARIMA或BP神经网络进行建模的模型预测结果准确度高。
基于此,本文选取沪深300指数和百度的收盘价为研究对象,利用线性模型ARIMA和非线性模型BP神经网络的单一模型和组合模型来预测股票价格,在模型组合时,利用了等权重法和方差倒数法。最后将单个模型和组合模型得到的预测值进行对比。
2. 研究方法与模型建立
2.1. 时间序列的ARIMA模型
在时间序列模型中,我们会经常运用到ARIMA模型,ARIMA模型能够很好的研究和分析时间序列数据,而且预测的精度对于短期的数据还是较高的。
在上世纪70年代,Box和Jenkins提出了时间序列模型,这种模型有三种基本类型:自回归模型、滑动平均模型和自回归滑动平均模型。设
是一个均值为零,且是平稳的时间序列,ARMA(p,q)模型也即是p阶自回归,q阶滑动平均的公式表达为:
可简写为
。ARIMA(p,d,q)模型中d的含义是差分阶数,在金融市场中,股票价格的时间序列数据通常是非平稳的,因为只有平稳序列才能建立ARMA模型,所以要对其进行平稳化处理,一般来说差分是进行平稳化最常用的方法,差分后的ARIMA与ARMA相同。
以下考虑ARIMA(p, 1, q)过程,也即是经过一阶差分的ARMA(p, q)模型,
,有:
将
代入得:
将上式改写为:
(1)
2.2. ARIMA模型的建模步骤(图1)
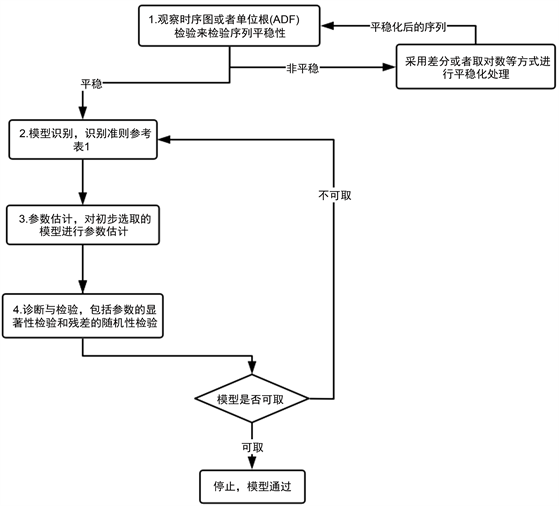
Figure 1. Diagram of ARIMA model modeling steps
图1. ARIMA模型建模步骤图
拟合模型的初步识别准则 [6] 如下表1所示:

Table 1. Preliminary identification criteria for the ARMA model
表1. ARMA模型初步识别准则
最后利用上文得到的已经通过检验的模型,对所研究的问题进行分析、建模、预测。
2.3. BP神经网络算法
BP神经网络 [7] 是目前应用范围很广的神经模型,是使用误差逆向传播算法来进行训练的一种多层前馈神经网络,对训练集数据进行反复不断的训练来调整权值和阈值,得到神经网络预测输出值与我们所期望得到的输出值无限接近,BP神经网络的学习能力极强,能很好的学习数据间的函数映射关系,从而来对数据进行分类、聚类、拟合、预测等等。

Figure 2. BP neural network topology
图2. BP神经网络拓扑结构
由图2可知,BP神经网络从结构上看有三层,从左往右依次为输入层、隐含层、输出层。其中,相邻的层之间是完全连接的,而在同一层内的神经单元之间是无连接的。
为BP神经网络的输入值;
为BP神经网络的隐含层节点,
为BP神经网络的输出值;
和
表示BP神经网络权值。
在使用BP神经网络模型预测之前,需对模型进行训练,若不对网络进行训练的话,网络就不会具备联想记忆和预测能力,就不能进行预测研究。通常情况,在神经元个数较少的情况下,网络对样本的识别能力会降低,这样网络的训练量达不到,得到的训练结果少了,网络就不能对样本进行完全的识别,给网络的训练带来困难,反之,若神经元的个数很多的情况下,网络训练的时间就会增加,网络的就会出现过度训练的情况,严重可能导致训练效果及预测效果都很差。一般情况下,对我们来说隐含层神经元个数的确定是极其困难的,到目前为止还没有一个明确可行的理论方法支撑,我们就只能通过以下经验公式,并结合多次的试验反复对比来确定。
经验公式中:l表示隐含层神经元个数;n表示输入层节点数;m表示输出层节点数;a表示一个0~10任意整数。
2.4. 模型组合方式
1) 等权重组合:顾名思义,给予两个模型同等的数值的权数;
2) 方差倒数法 [4]:
主要思想:从预测误差入手,根据预测误差来进行赋值,也就是给误差平方和大的模型赋予小的权重,相反给误差平方和小的赋予较大的权重,这样一来,经过这种赋权的方式组合的模型,其预测的误差平方和就会最大程度的最小。
具体步骤:第一步计算每个单一模型预测的误差平方和;第二步用第一步得到的结果(也即是每一个模型的误差平方和)求倒数;第三步把第二步计算得到的值全部加起来所有;最后用第二步得到的各倒数除以第三步求得的倒数和,从而就可以得到各个模型的权数。
3. 实证研究分析
3.1. 数据来源
本文选取沪深300指数2017年6月1日至2019年12月17日(除节假日外)共624天的收盘价作为实验数据,来预测2019年12月18日至2019年12月31日的收盘价,并以同样的时间节点选取百度股票的收盘价来进行实证分析。所有历史数据均来自英为财情(https://cn.investing.com/)财经网站。
3.2. ARIMA模型建立
3.2.1. 平稳性检验
根据沪深300指数收盘价的原始数据画时序图以及做单位根(ADF)检验,时序图如图3所示,ADF检验如下表2所示:
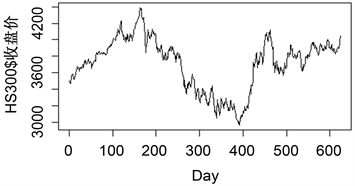
Figure 3. Time chart of the original data of the closing price of the CSI 300 Index
图3. 沪深300指数收盘价原始数据时序图
Table 2. ADF test of the original data of the CSI 300 Index
表2. 沪深300指数原始数据的ADF检验
由时序图可知序列不平稳,ADF检验的
,认为沪深300指数原始序列数据是非平稳的序列。需要做平稳化处理,对原始数据进行一阶差分,得到序列xdiff,并检验xdiff的平稳性,xdiff的时序图以及ADF检验的结果如下图4和表3所示:
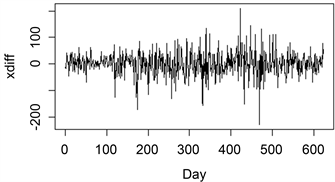
Figure 4. Time chart of the CSI 300 Index after stabilization
图4. 沪深300指数平稳化处理后的时序图
Table 3. ADF test after the first difference of the CSI 300 Index
表3. 沪深300指数一阶差分后的ADF检验
由图4时序图可知序列平稳,进一步通过ADF检验得到的
可知,差分后的序列xdiff已经平稳,故取d = 1。
3.2.2. 模型定阶
对差分后的序列xdiff,做其自相关图(ACF)及偏自相关图(PACF)如下:
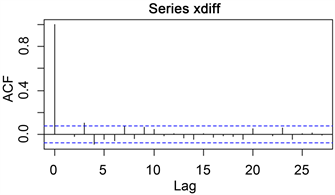
Figure 5. Autocorrelation diagram of the first-order difference sequence
图5. 一阶差分序列的自相关图
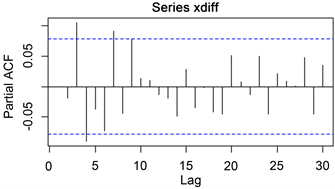
Figure 6. Partial autocorrelation graph of the first-order difference sequence
图6. 一阶差分序列的偏自相关图
由图5和图6可以看出p和q可能的取值分别为p = 3, 4, 7, q = 2, 3, 6, 8,从而我们考虑建立的模型如下表4所示,再通过AIC最小准则进行比较确定阶数p和q。
Table 4. ARIMA AIC comparison of different orders
表4. ARIMA不同阶数AIC比较
从表4可以看出,在所有选择的模型中,当p取4,q取8时,AIC值为6462.07,AIC值是最小的,因此确定模型为ARIMA(4, 1, 8),代入公式(1),模型ARIMA(4, 1, 8)的表达式为:
对ARIMA(4, 1, 8)进行参数估计,估计值如表5所示:
Table 5. ARIMA(4, 1, 8) model parameter values
表5. ARIMA(4, 1, 8)模型各参数值
将估计的参数代入到模型表达式中得到:
3.2.3. 模型的诊断检验
上文中,我们已经建立了ARIMA(4, 1, 8)模型,还需对模型的残差进行白噪声和正态性检验,只有检验通过,才能利用该模型进行预测。
画出残差的时序图和自相关图,如图7所示,从图可以看出,残差序列是平稳,且是相互独立的,并做Ljung-Box检验,从结果得知,Ljung-Box检验的
,这说明了残差序列是白噪声的,通过图8残差的Q-Q图可知,残差是满足正态性。
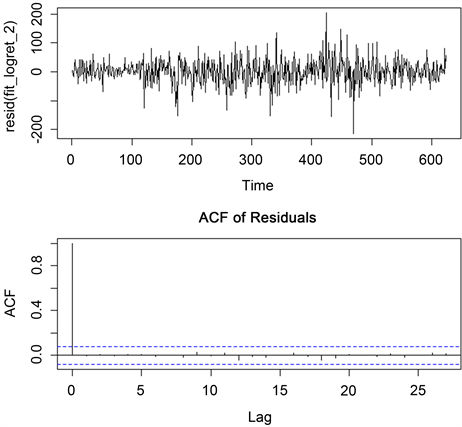
Figure 7. Residual sequence diagram and autocorrelation diagram
图7. 残差序列图及自相关图
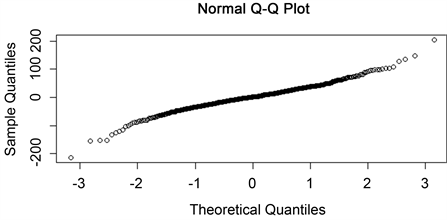
Figure 8. Residual normality test Q-Q plot
图8. 残差正态检验Q-Q图
综上所述,建立的ARIMA(4, 1, 8)模型是可行的,可以用于预测沪深300指数的收盘价。采用同样的建模过程对百度股票进行时间序列建模,得到ARIMA(2, 1, 2)模型为最优模型,且该模型各种检验均通过。
3.3. BP神经网络模型
在BP神经网络模型预测中,不考虑其他的影响因子,仅以本文选取的两组实验数据作为单一预测因子。为了避免过拟合,对数据进行划分,把收集的实验数据中的时间序列划分为训练集、测试集和验证集,并且根据时间顺序分别按比例70%、15%和15%来进行划分。通过检验得到当隐含层为4时,以沪深300指数收盘价为原始数据的神经网络的均方误差最小,当隐含层为3时,以百度收盘价为原始数据的神经网络的均方误差最小,在使用MATLAB R2014a进行神经网络建模时,分别设计一个隐含层神经元数目为4、3的3层网络结构,并利用设计好的神经网络模型,对本文选取的两组数据沪深300指数和百度的收盘价进行预测。
4. 模型预测结果比较
利用单一模型ARIMA(4, 1, 8)模型和BP神经网络模型对沪深300指数收盘价的预测值,两种组合法得到的模型的预测值以及各模型所对应的相对误差如表6,表7所示,用ARIMA(2, 1, 2)模型和BP神经网络模型,以及采用不同方式组合的模型,对百度收盘价的预测值及各模型预测的相对误差如表8,表9所示。
Table 6. Predicted values of CSI 300 Index by different models
表6. 不同模型对沪深300指数的预测值
Table 7. Relative error of different models on the CSI 300 Index
表7. 不同模型对沪深300指数的相对误差
Table 8. Different models predict Baidu’s stock price
表8. 不同模型对百度股价的预测值
Table 9. Relative error of Baidu’s stock price forecast by different models
表9. 不同模型对百度股价预测的相对误差
上文中相对误差计算公式为:
从预测的相对误差表7和表9我们可以看出,通过方差倒数法组合的预测效果在前期较好,在后期来看,等权重组合法的预测效果较好。
从模型整体预测效果来看,本文选择平均绝对百分比误差(MAPE)来评估模型的预测精度,计算公式如下:
,
为实际值,
为预测值。
利用MAPE公式分别计算不同模型对沪深300指数和百度股票收盘价预测的平均相对误差,得到的结果如下表10所示:
Table 10. MAPE for different prediction models
表10. 不同预测模型的MAPE
由上表10可知,在对沪深300指数的预测模型中,等权重组合和方差倒数组合的ARIMA-BP的MAPE都为0.79%,是四个模型中最小的,说明组合后的模型预测效果最好,在对百度股价的预测模型中,等权重组合的模型的MAPE为1.81%,也是四个模型中最小的,说明预测效果最好。
5. 结论
本文利用时间序列模型和BP神经网络模型,对沪深300指数和百度股票的收盘价进行分析,分别建立了ARIMA(4, 1, 8)和ARIMA(2, 1, 2)模型和BP神经网络两种单一模型,以及通过方差倒数法和等权重法来组合两种模型,得到等权重组合ARIMA-BP模型和方差倒数组合模型,并利用四种模型对收盘价进行预测。结果表明,组合模型的预测效果优于单一模型。在组合模型中,等权重组合ARIMA-BP模型的预测效果比方差倒数组合模型好;在单个模型中,BP神经网络的预测效果优于ARIMA模型。这一结论充分说明了结合金融数据的线性和非线性的特征来进行预测是可行的,能较高地提升我们的预测精度。