1. 引言
无论是传统模拟测量还是现代数字化测量技术采集的数据,粗差都在所难免,而当平差系统含有粗差时,经典最小二乘估计由于不具备抵抗粗差的能力而使其应用受到极大限制。针对粗差处理,自上世纪60年代以来,提出了很多方法。归纳起来,这些方法大致可分为三类,第一类是均值漂移模型 [1] [2],其思想是将观测向量看作是随机变量,当观测向量中某些观测值包含粗差时,样本均值会发生扭曲,从对结果的影响上来看,可解释为将含粗差的观测值看作是与正常观测值有相同方差和不同期望;第二类是方差膨胀模型 [3] - [8],这类模型是将包含粗差的观测值视为与正常观测值具有相同期望和不同方差来处理,这类方法已经由最初仅能处理独立观测值发展到也能处理相关观测 [9];第三类是我国学者欧吉坤教授提出的拟准检定法,该方法以观测值的真误差为研究对象,通过一套独特的选择拟准观测的实施办法,在附加拟准观测的真误差的范数极小的条件下,求解关于真误差的秩亏方程,根据真误差估值的分布特征来判别粗差,定位粗差,然后改正含粗的观测值 [10],这种方法后来被证明在一定条件下与选权拟合法具有等价性 [11]。以上方法尽管从提出至今发展已经非常成熟,但它们都有一个共同特点,那就是要么经过不断重复假设检验过程,逐步定位剔除或修正含粗差观测值,要么经过选权迭代过程削弱粗差影响,而且当样本值较少或粗差占比较大时,其结果的可靠性会有所下降。为此,本文尝试将信息扩散理论引入测量平差,利用信息扩散函数计算最小二乘估计残差的实际分布,将残差向量的概率值近似为相应观测值的权,然后再次进行平差计算,试验表明,这是一种非常高效的抗差估计方法。
2. 信息扩散原理及其估计
2.1. 信息扩散原理
设母体
的概率密度函数为
,
为给定的来自母体
的样本。当由
不能完全精确地认识
时,称 对
是非完备的。从概率统计的角度来看,这种不完备主要是因为样本集
中样本点数目太少,不足以反映
的全部特征。因此,可以通过增加样本数目来改善不完备程度。不难理解,当通过改善
使其趋于或达到可以完备描述
时,必定会经历一个由模糊到清晰的过程,即
从非完备到完备具有一种过渡趋势。当
非完备时,这种趋势表现在
的样本点上,就是每一个样本点都有发展成多个样本点的趋势,使每一个样本点都充当“周围未出现之样本点的代表” [12]。若设
对
是非完备的。从概率统计的角度来看,这种不完备主要是因为样本集
中样本点数目太少,不足以反映
的全部特征。因此,可以通过增加样本数目来改善不完备程度。不难理解,当通过改善
使其趋于或达到可以完备描述
时,必定会经历一个由模糊到清晰的过程,即
从非完备到完备具有一种过渡趋势。当
非完备时,这种趋势表现在
的样本点上,就是每一个样本点都有发展成多个样本点的趋势,使每一个样本点都充当“周围未出现之样本点的代表” [12]。若设 的观测值为
,则
在
点提供的信息应可以被其周围点分享,而周围点分享的来自
信息量的多少与其属于
点周围的程度有关,显然,越靠近
的点分享的信息就越多。若记
点自身信息量为1,则其周围的点从
获取的信息量介于0到1之间。这种
的观测值为
,则
在
点提供的信息应可以被其周围点分享,而周围点分享的来自
信息量的多少与其属于
点周围的程度有关,显然,越靠近
的点分享的信息就越多。若记
点自身信息量为1,则其周围的点从
获取的信息量介于0到1之间。这种 点的信息向其周围扩散的过程称为信息扩散过程,简称信息扩散。
点的信息向其周围扩散的过程称为信息扩散过程,简称信息扩散。
2.2. 信息扩散估计
设
是知识样本,Y是基础论域。设
,则当
非完备时,存在函数
,使点
获得的量值为1的信息可按
的量值扩散到
上去,且扩散所得到的原始信息分布
能更好地反映
所在总体的规律。若设
为定义在
上的一个波雷尔可测函数,
为常数,则称
(1)
为母体概率密度函数
的一个扩散估计,式中
称为扩散函数,
称为窗宽。
2.3. 信息扩散函数及窗宽确定
由(1)式知,实现母体概率密度函数
的扩散估计的关键是
的具体形式难以确定,当考虑样本分布符合正态分布时,可借用分子扩散理论导出正态扩散函数为 [12]:
(2)
由此,将(2)式带入(1)式可得母体概率密度函数的正态扩散估计为
(3)
上式中
为窗宽,一般可根据择近原则导出的以下经验公式确定 [12]:
(4)
其中
,
,
; a是n的函数,具体随n取值变化情况参见文献 [12]。当
时,取
,这是因为测量中总是要求要有多余观测,
一般都可以满足,若
时,可根据样本数目,按文献 [12] 给出的相应数值取值。
3. 利用信息扩散函数计算观测值的权
由上文可知,信息扩散估计本身一般只适合于一维参数估计,且要求样本具有相同的数学期望,而测量中的参数估计几乎全是多维参数估计的情况,且常常因为观测量种类不同,数学期望既不相同也难以比较,这样就制约了信息扩散估计在测量数据处理中的应用。文献 [13] 以水准测量为例,探讨了利用一维信息扩散估计进行水准测量平差的问题,但至今对于更为普遍的多维测量平差问题仍然讨论较少。为解决这一问题,本文提出采用观测值最小二乘估计的标准化残差向量V作为扩散变量构造V的概率密度函数
去代替观测值L的概率密度函数
,近似估计母体概率密度函数
,然后根据
计算观测值l的权
,据此再次进行常规最小二乘估计即可获得参数的抗差最小二乘解。具体可采用以下步骤进行:
1) 针对原始观测值,令观测权阵为单位阵(如有确切先验权阵,可采用先验权阵)建立经典高斯-马尔科夫模型,利用最小二乘估计获得观测值的标准化残差向量;
2) 利用式(2)和式(3)估计标准化残差V的概率密度函数
,即
(5)
3) 用标准化残差的概率密度函数代替观测值概率密度函数计算观测值的权
,即
(6)
4) 利用步骤(3)中确定的权值再次进行最小二乘估计获得参数的抗差解
,即
(7)
式中B为高斯–马尔科夫模型的系数矩阵,L为观测向量,
。
4. 算例及分析
4.1. 算例描述及解算方案设计
本文算例来自文献 [14] 中例7~9三角网观测数据,网中共有4个已知点和2个未知点以及18个同精度角度观测值,已知数据及角度观测值见表1和表2,图1为测角网示意图。为验证本文方法的合理性及其抗差效果,现分别在第1、5、8、15和第16等5个角度观测值上依次模拟大小为−7.0″、7.0″、−5.6″、5.6″、6.8″和−6.8″的粗差,并采用如下4种方案进行平差计算:
方案1:采用模拟粗差后的18个观测值,按最小二乘进行平差处理;
方案2:采用模拟粗差后的18个观测值,按IGGIII进行平差处理;
方案3:采用模拟粗差后的18个观测值,按拟准检定法进行平差处理;
方案4:采用模拟粗差后的18个观测值,按本文方法进行平差处理。
以上各方案计算结果见表3,表3中
为未知点P1和P2的坐标改正数,
为各方案参数估值与参数真值(本文参数真值取文献 [14] 中不含粗差的正常最小二乘估计结果)差值的范数,可作为度衡量各方案参数估计的优劣指标。
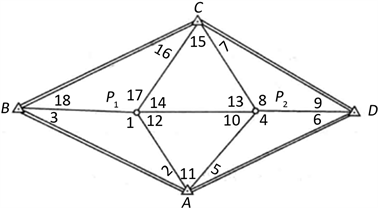
Figure 1. Schematic diagram of angle measuring control network
图1. 测角控制网示意图

Table 3. Parameter estimation results of each scheme
表3. 各方案参数估计结果
4.2. 结果分析
1) 结果描述:从表3参数估计结果来看,方案1参数估计结果与真值相差甚远,其结果是扭曲的,说明最小二乘估计不具备抵抗粗差的能力;方案2和方案3与最小二乘估计结果相比,都一定程度的削弱了粗差对参数估计结果的影响,方案4参数估计结果与真值最接近,抗差效果最好。从方案2、方案3和方案4参数估计与参数真值差值的范数分别等于0.6558、0.3590和0.1654来看,整体上抗差效果由好到差排列顺序依次为方案4、方案3和方案2;
2) 结果分析:方案4采用最小二乘估计残差标准差计算信息扩散函数值并利用式(6)近似计算观测值的权,相当于利用残差的真实分布定权,即便是某些观测值中包含粗差,其偏离正态分布的实际情况也会在信息扩散函数中体现,也就是说通过信息扩散函数定权方法能够较好地顾及粗差影响;IGG抗差估计核心是通过选权迭代过程实现的,其理想情况是若残差小于某一限值(本文取1.5倍验后中误差)则相应观测值的权不改变,若介于某一区间,则给予降权处理,若大于某一限值(本文取2.5倍验后中误差),则对相应观测值给予零权处理(即删除不用)。然而,上述选权迭代过程中,观测值权值会受最小二乘估计“均摊”效应影响而失真,即具有相对较小残差的观测值未必不含粗差,反之大残差也未必真包含粗差。不仅如此,这种“均摊”效应在迭代过程中还可能发生转移,这使得观测值定权具有了不确定性,观测值的最终权值是多次“均摊”和“转移”的结果;拟准检定法结果优于IGG方案,主要是因为拟准检定法在迭代过程中采用真误差的分群特性确定拟准观测值,而真误差是没有误差的,相对于IGG方案减少了不确定因素,但拟准检定法仍然会受初始“拟准观测值”选择不准确的影响,意即尽管拟准检定法在迭代过程中利用真误差分群特征确定“拟准观测值”,但在实施之初也同样会受最小二乘“均摊”效应影响而无法准确确定初始拟准观测,而这种影响会延续至后续过程。
5. 结语
如何处理受到粗差污染的观测数据一直是测量平差的重要研究内容之一。本文首先利用最小二乘估计的观测值标准化残差计算信息扩散函数,解决了多维不同类观测量难以利用信息扩散估计进行数据处理的难题,然后利用标准化残差的信息扩散估计值构造观测值的权阵再进行最小二乘平差,结果表明这是一种成功的抗差估计方法:与IGG方案以及拟准检定粗差处理方法相比,信息扩散估计根据残差实际分布定权,较好地避免了最小二乘估计残差的“均摊”效应影响,不仅可以起到良好的抗差作用,而且还可以一定程度地保留含有粗差的观测值信息,并且不需要任何迭代过程,是一种良好的抗差估计方法。
基金项目
贵州省科学技术基础研究计划项目(黔科[2017]1054);国家自然科学基金项目(41701464);贵州大学引进人才科研项目(贵大人基合字(2016)51号);贵州大学测绘科学与技术研究生创新实践基地建设项目(贵大研CXJD[2014]002)。