1. 引言
人工智能对输入的未知事物进行分类判别,很大程度依据聚类将数据点按照一定规则进行分群 [1]。根据距离或相似度对数据点聚类,是研究诸多自然和社会问题的有力工具。而在各种聚类算法中,分层聚类具有特别的优势 [2]。聚类是一个把数据对象集划分成多个组或簇的过程,使得簇内的对象具有很高的相似性 [2]。但与其他簇中的对象很不相似。数据间的距离通常使用距离度量。数据对象的簇可以看成隐含的类 [3]。在这种意义下,聚类有时又称自动分类。聚类过程中可自动地发现这些分组,这是聚类分类的突出优点。也被称为无监督学习,因为在没有标签信息情况下,可实现自动分类。由于这种原因,聚类是通过观察学习,而不是通过有标签的示例学习。
语音信号可视为基本音素单元的序列。现今很多自动语音识别系统依赖于这些基本单元准确识别。当前成熟的百度搜索也是基于文字的检索,而基于语音对语音的搜索有巨大的市场需求。但无监督的语音研究困难重重,语音分割是声学片段建模中至关重要的初始步骤,该步骤在音频搜索和无监督声学建模得到了广泛应用。以语音分割成基本单位涉及声道系统从一种状态转换到另一种状态的时刻。但是,过渡并不是突然发生的,而是连续发生的 [4] [5] [6] [7]。
通常,聚类的方法有很多种常见的有K-means [8] [9]、层次聚类(Hierarchical clustering)、谱聚类(Spectral Clustering)、GMM等方法 [8]。其中,ward’s method [10] 是聚类中一种常用方法,该方法对不相邻的特征(样本)的距离都要一一计算,计算量大,内存开销大,需要好的算法来处理这个问题 [7]。尤其,当输入的语音序列比较大时,常规的凝聚型层次聚类Hierarchical methods (HAC)方法就变得很慢。于是本文根据语音特征本身就具有相邻语音有较高的相似性,跨段语音差异更大的特点。提出基于HAC算法基础上相邻快速HAC算法解决时间长、内存开销大等问题,并应用到语音分割中来。
2. 层次聚类的原理及分类
2.1. 层次法(Hierarchical methods)
系统聚类也称层次聚类法。该算法先计算特征之间的距离,如欧式距离。在迭代过程中,每次查找到距离最近的点并合并到同一个类。然后,再计算新类与剩余类之间的距离,继续将距离最近的类合并为一个大类。不停的合并,直到合并到一个类或满足某个阀值。其中类与类的距离的计算方法有:最短距离法,最长距离法,中间距离法,类平均法等。比如最短距离法,将类与类的距离定义为类与类之间样本的最短距离 [11]。
根据层次分解的顺序层次聚类算法可分为:自下向上和自上向下两种方法,即凝聚的层次聚类算法和分裂的层次聚类算法,也可以理解为自下而上法(bottom-up)和自上而下法(top-down)。
自下而上法的凝聚型层次聚类初始化时每个个体(object)都是一个类,然后根据linkage寻找同类,最后形成一个“类” [12]。
而分裂型层次聚类采用自上而下法,就是反过来,初始化时所有个体都属于一个“类”,然后根据linkage排除相似度不高的类,最后每个个体都成为一个“类” [11]。
2.2. 层次聚类的流程
凝聚型层次聚类的策略是先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到所有对象都在一个簇中,或者某个终结条件被满足。绝大多数层次聚类属于凝聚型层次聚类,它们只是在簇间相似度的定义上有所不同。这里给出采用最小距离的凝聚层次聚类算法流程 [13] [14] 如下:
从上面算法1可以看出凝聚的层次聚类并没有类似基本K均值的全局目标函数,没有局部极小问题或是很难选择初始点的问题。合并的操作往往是最终的,一旦合并两个簇之后就不会撤销。当然其计算存储的代价是昂贵的。
2.3. 层次聚类的优缺点
层次聚类算法的优点有:距离和规则的相似度容易定义,限制少;不需预设聚类数k;可以发现类的层次关系;可以聚类成其它形状。缺点有:计算复杂度太高,当特征(样本)数量很多就需要很多时间;奇异值也能产生很大影响;算法很可能聚类成链状。
这个方法其实效率比较低,特别是算cluster的ESS值还要先求均值点,然后算距离的平方再求和,不过有一个快速的计算方法叫Lance-Williams Algorithm [15] (快速HAC)可以大大简化ward method的计算。该算法可以不用ESS的公式计算ESS,直接套用下面的公(1)。
(1)
其中,初始的ESS由两点之间的距离决定,也就是说完全不需要算ESS了。但计算量和内存开销也大。因此,根据语音特征分割所具有的特点,进一步改进HAC算法有效解决语音特征分割面临的时间和空间的问题。
3. 改进HAC算法
从以上分析可以看出,原来的HAC或快速HAC算法都先把所有样本当成初始类,计算出样本之间的距离,并存储在矩阵中形成一个上三角矩阵 [16],从距离矩阵中找到最小的,合并成一个类,更新全部其他点到该新类的距离矩阵,再迭代上述步骤直到只剩一个类。整个过程的计算存储代价是昂贵的,耗时也严重,因语音特征中可能一长段语音特征对应同一个phoneme,段内的语音特征相似度高,段外语音特征相似度不高的特点,只需关注相邻两两语音的相似,即左右特征的距离,不用关注不相邻样本间不相邻特征之间的距离来改进HAC算法并应用到语音分割中 [17] [18]。
3.1. 算法设计
根据语音分割的特殊性,不用矩阵来存储距离,而是改用字典双链表来存储相邻特征距离,其伪代码如下:
(2)
其中,i,j为相邻两两语音特征向量下标,dist其相邻语音特征的欧式距离 [19]。欧式距离计算如下:
(3)
其中,X, Y为n维的语音特征(样本),如39维的MFCC。
同样,该算法初始时,每个特征是独立的phoneme,在距离双链表中找到最小距离,和相邻语音特征下标,再根据下标来更新合并后的新数据点。
(4)
其中,front,back为相邻的两个特征下标,
为用平均法把front和back特征合并为新特征,就由合并的两个相邻特征的平均值来取代。
3.2. 算法流程
该算法中,凡是两个相邻的特征都计算它们的欧式距离 [18],相并逐一求出输入语音特征的相邻欧式距离,然后存表双链表中。先从相邻距离双链表中查找出距离最小的两个特征并合并成一个段,这个段就是那两个特征的平均值,接着再求新段与相邻特征的距离。层次聚类算法对语音特征分割结果示意图 [19] 如图1所示。
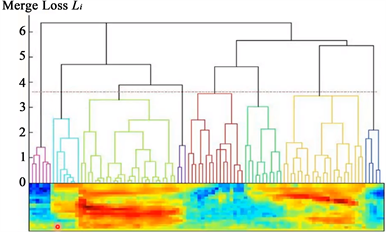
Figure 1. Schematic diagram of speech feature segmentation by hierarchical clustering algorithm
图1. 层次聚类算法对语音特征分割结果示意图
对如图1,横轴是时间,时间轴上为语音特征信号,如39维的MFFC序列。Merge Loss Li为与合并前的那两个特征相差多少,最后长一整个树。当这棵树长好后,可以在这棵树上切一刀,就可以切出一个个段来。从虚线处切,虚线下一条线对应的每个子树就对应一个segment,这样就得到8个segment。如果觉得切的太细,可往上移再切。就可做任意精细度的切割法 [7] [20] [21] [22]。
对快速HAC算法改进的相邻HAC算法流程如下所示:
其改进的相邻HAC算法伪代码如下:
1:clusterMap[k] = 1# 存放cluster的情况,形如'1':4表示cluster1里面有4个元素(样本)
2:single_obj。append(i,i+1,dist)#存放cluster之间的距离,形如'1,2':3。22表示cluster1与cluster2之间的距离为3。22
#查找距离最短的两个cluster,并迭代合并
3:while True:
4:minnode, min = link。min() #查找距离最短的两个cluster
5:front, back = minnode。getName()#取得相邻特征的下标
6:clusterMap[clusterCount]= ni + nj #合并相似段
#更新最小相邻距离cluster到新cluster的距离
7:newdistance[clusterCount] = (newdistance[front] + newdistance[back]) /2
#更新最小距离节点与相邻节点间的距离,并更新
8:Update_dist(minnode,left,right)
9:Update_link(minnode,left,right)
#删除最小节点和两个cluster
10:del minnode,clusterMap[front,back]
#只剩一个子类或满足某个阀值
11:if len(clusterMap) == 2:
12:break# 合并到只剩一个集合为止,然后退出
其中,伪代码第行和第行的两个函数update_dist()和update_link()分别为更新计算查找到距离最短的两个cluster并用平均法表示为一个新节点后与相邻类间的距离,以及重新更新查找到距离最短的两个cluster与相邻cluster的链表。
4. 实验对比与分析
4.1. 实验平台
本实验采用python 3.6,硬件配置:CPU Intel(R) Xeon(R) E3-1231 v3 @ 3.4 GHz,16 G内存,NVIDIA GeForce GTX 1060 3 GB;软件配置:pycharm64。
4.2. 实验结果
使用62 Kb、199 Kb和1367 Kb的39维的MFCC语音特征数据文件分别用快速HAC和改进的相邻HAC算法进行实验,得到对比结果,如表1所示。

Table 1. Fast HAC (GPU acceleration) and the performance comparison table of the improved adjacent HAC algorithm
表1. 标准试验系统结果数据
5. 结束语
HAC层次聚类为无监督分类的重要工具,其默认分类算法中合并成本高,需要较大的计算力、较大的内存空间。如果总共有n个组,就必须把每个组合并都要算一遍,也要n × (n − 1)/2,当特征(样本)数量增多时比较耗时,消耗内存也线性地增长。因此,为解决语音特征分割问题,提出相邻语音特征分割,只需关注相邻特征(样本)语音的合并问题,就无需要计算并更新所有特征或类间的距离,进而赢得了时间和空间,最后通过实验对比分析验证了算法的有效性。
参考文献