1. 引言
考虑二元逻辑回归模型中因变量
服从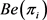 分布。其中,伯努利参数
依赖未知参数
和解释变量
的取值,表达式如下:
分布。其中,伯努利参数
依赖未知参数
和解释变量
的取值,表达式如下:
,
(1)
X是
的矩阵,
是X第i列。
为
的未知系数矩阵。
在逻辑回归模型中,使用迭代加权最小二乘(IRLS)算法可得
的极大似然估计(MLE):
(2)
其中
且
,
。
在逻辑回归模型中,当解释变量高度相关时即存在复共线性问题时,MLE的方差会膨胀。为了克服这个问题,学者们提出了很多估计来改进MLE。例如,Schaefer等 [1] 提出了岭极大似然估计(RE)。Månsson等 [2] 提出了Liu极大似然估计(LE),表达式为:
(3)
其中
,
,
。
Asar [3] 提出了Liu-Type极大似然估计(LTE),表达式为:
(4)
其中
,
。
Huang J [4] 提出了两参数极大似然估计(TPE),表达式为:
(5)
其中
,
。
考虑在实际工作中,逻辑回归模型中的未知参数向量
有可能存在一些先验信息,这时我们可通过等式约束、不等式约束、椭球约束等来描述这些先验信息。本文将考虑带随机线性约束的情况。一般的随机线性约束为:
(6)
其中,H是
的满秩已知矩阵。h是一个
预设值的向量。u是一个服从均值为0,方差矩阵为
的
随机向量。其中
为已知的
阶正定矩阵。
基于随机线性约束,Nagaraja和Wijekoon [5] 提出了随机约束极大似然估计(SRE),表达式为:
(7)
为了进一步改进SRE,Varathan和Wijekoon在文献 [6] 和 [7] 中分别提出了随机约束岭极大似然估计(SRRE)和随机约束Liu极大似然估计(SRLE)。其中SRLE表达式为:
(8)
Wu和Asar [8] 提出了随机约束Liu-Type极大似然估计(SRLTE),表达式为:
(9)
我们结合SRE和TPE提出了一个新的估计即随机约束两参数极大似然估计(SRTPE),其表达式为:
(10)
其中
。
从SRTPE的表达式看出,SRTPE是一种更一般的估计,它可以退化为SRE,SRRE,SRLE:
1)
.
2)
.
3)
.
4)
.
2. 提出估计的性质
接下来我们将在均方误差矩阵(MSEM)准则下,对新提出的新估计SRTPE与TPE,LTE,LE,SRE,SRLE和SRLTE进行比较。其中参数
的估计
的MSEM为:
(11)
这里
是方差矩阵,
是估计
的偏差。一般的,当
时,我们称估计
在MSEM准则下优于
。
现在,我们将根据以下三个引理来证明我们所得的定理。引理如下:
引理1. (Rao和Toutenburg [9])设矩阵A和B是
阶矩阵,且
,
。则
。
引理2. (Rao [10])设M和N都为
阶正定矩阵,则
当且仅当
。
引理3. (Trenkler和Toutenburg [11])令参数向量
的两个估计
,
。设
。则
当且仅当
。其中,
为
的偏差。
定理1. SRTPE在MSEM准则下总是优于TPE。
证明:由公式(11)可得TPE和SRTPE的MSEM如下,
其中
。现在我们考虑它们的差,令
由于:
则
又因为矩阵
,因此
证明完成。
定理2. 当
时,新估计SRTPE在MSEM准则下优于
LTE当且仅当
。其中
,
。
证明:由公式(11)可得LTE的MSEM为
接下来我们考虑LTE与SRTPE的MSEM的差
因为
,
,根据引理2, 当
时,
。再根据引理3,当
时,
。定理得证。
定理3. 当
时,新估计SRTPE在MSEM准则下优于
LE当且仅当
。其中
,
。
证明:由公式(11)可得LE的MSEM为
考虑LE与SRTPE的MSEM的差
因为
,
,根据引理2, 当
时,
。再根据引理3有,当
时,
。得证。
定理4. SRTPE在MSEM准则下优于SRE当且仅当
。其中
,
。
证明:由公式(11)可得SRE的MSEM为
考虑SRE与SRTPE的MSEM的差
由于
,因为
,
,所以根据引理1可知
。又因为
,根据引理2有当
时,
即
。定理4得证。
定理5. 当 时,SRTPE在MSEM准则下优于SRLE当且仅当
。其中,
。
时,SRTPE在MSEM准则下优于SRLE当且仅当
。其中,
。
证明:由公式(11)可得SRLE的MSEM为
考虑SRLE与SRTPE的MSEM的差
因为
,
,通过引理2,当
时,
。再根据引理3,当
时,
。定理得证。
定理6. 当
时,SRTPE在MSEM准则下优于SRLTE当且仅当
。 其中
。
证明:由公式(11)可得SRLTE的MSEM如下
考虑SRLTE与SRTPE的MSEM的差
因为
,
,通过引理2有,当
时,
。根据引理3,当
时,
。定理得证。
3. 偏参数k和d的选取
因为随机约束两参数极大似然估计与定理中的各估计在均方误差准则下的比较结果依赖参数
的偏参数k和d的选择。所以合适的选取偏参数k和d可以使模拟得到可行的结果。为了得到可行的k和d的值。我们对矩阵C进行分解使得
。其中,Q是矩阵C的特征向量的列向量组成的矩阵,
,
是C的第i个特征值。我们令
(12)
其中
,
。
可以看出函数
是一个关于参数d的二次函数。因此,为了求使
最小的d的值,我们固定k,并对
求关于d的偏导得
(13)
令上述等式(13)等于零,我们得到了d的一个建议最优值
,结果如下:
(14)
同样的,为了求偏参数k的值使得
最小,我们对函数
关于k求偏导得到
(15)
令上述等式(15)等于零,即分子为0得到
(16)
当d固定时(16)中k的最优值依赖
,根据Hoerl和Kennard [12] 和Kibria [13] 提出的方法,我们用它的无偏估计来替代:
(17)
Hoerl等 [14] 提出了使用k的调和平均值来替代k的估计,Kibria [13] 提出了使用k的算术平均值来替代k的估计,Hoerl和Kennard [12] 提出了使用k的几何平均值来替代k的估计。再根据我们得出的k值得到偏参数k的三种取值分别定义如下:
(18)
(19)
(20)
最后我们使用Özkale和Kaçiranlar [15] 提出的迭代方法对模拟的k和d进行取值:
步骤一:根据文献Özkale和Kaçiranlar [15] 中的定理3.1计算
的值;
步骤二:用步骤一中
的值来估计
,
,
的值;
步骤三:用步骤二中的
,
,
的值来计算(14)式中
的值;
步骤四:如果
,则
。其中
,
。
4. 蒙特卡罗模拟
接下来我们用蒙特卡罗模拟来验证估计MLE,LE,LTE,TP,SRE,SRLE,SRLTE和SRTPE在MSE准则下的优良性。由文献McDonald和Galarneau [16] 使用下面等式生成解释变量:
,
(21)
其中,
是独立标准正态伪随机数,
表示任意两个解释变量的相关性。在模拟实验中,我们取
,
样本数
,
考虑0.85,0.9和0.95三种不同的情况。
由
服从伯努利二项分布而产生。对于
满足
。
此外,等式(6)中的约束矩阵我们的选取如下:
,
和
(22)
模拟次数重复2000次,估计MLE,LE,LTE,TPE,SRE,SRLE,SRLTE和SRTPE的MSE使用下面等式得到:
(23)
结果如下:

Table 1. Estimated MSE values of the MLE, LE, LTE, TP, SRE, SRLE, SRLTE, SRTPE when ρ = 0.85
表1. 当
时,估计MLE,LE,LTE,TP,SRE,SRLE,SRLTE,SRTPE的MSE
Table 2. Estimated MSE values of the MLE, LE, LTE, TP, SRE, SRLE, SRLTE, SRTPE when ρ = 0.9
表2. 当
时,估计MLE,LE,LTE,TP,SRE,SRLE,SRLTE,SRTPE的MSE
Table 3. Estimated MSE values of the MLE, LE, LTE, TP, SRE, SRLE, SRLTE, SRTPE when ρ = 0.95
表3. 当
时,估计MLE,LE,LTE,TP,SRE,SRLE,SRLTE,SRTPE的MSE
由表1~3可知,对建议的k和d值和给定的
为0.85,0.9和0.95三个取值,随机约束两参数极大似然估计的MSE均小于其他估计的MSE,即此时随机约束两参数极大似然估计在均方误差意义下优于其他各估计。同时,由表1~3可知,对给定的
为0.85,0.9和0.95,均有在k取
时SRTPE,SRLTE,SRLE,LTE,LE和TPE的MSE小于k取
和
时的MSE,即此时
优于
和
。由表1~3还可以看出,对建议的k和d值,随机约束两参数极大似然估计的MSE随着
的增大而增大,即解释变量之间的相关性增加,则新估计的MSE值会增加。
5. 总结
本文中,我们在二元逻辑回归模型中提出了一个新的估计即随机约束两参数极大似然估计。为了研究所提出估计的性质,理论上,我们在MSEM准则下对Liu极大似然估计,Liu-Type极大似然估计,两参数极大似然估计,随机约束极大似然估计,随机约束Liu极大似然估计,随机约束Liu-Type极大似然估计和随机约束两参数极大似然估计进行了比较,并得出了在MSEM准则下随机约束两参数极大似然估计优于SRLTE,SRLE,SRE,LTE,LE和TPE的充要或充分条件。实验上,我们用了蒙特卡罗模拟实验来比较了几个估计的优良性,验证了对建议的k和d值和给定的
为0.85,0.9和0.95情况下,新估计在MSE准则下优于SRLTE,SRLE,SRE,LTE,LE和TPE。