1. 引言
在煤矿生产过程中突水是与火灾、瓦斯等事故并列的矿井最主要安全灾难之一,长期以来一直严重威胁着煤矿安全开采。日后,随着浅部煤层开采完结,开采深度和范围势必不断加深和扩大,那么由深部开采带来的突水问题必将日益显著。如果矿井出现突水,怎样高效准确地查清突水缘由,判定突水水源,是处理和进一步防范突水事故的首要问题 [1],也是做好诸项后续治理工作的前提。
目前突水水源判别的主要方法有传统的环境同位素分析法、常规水化学特征判别法等,现代快速发展的多元统计学分析方法(距离判别分析法等)和非线性识别方法(BP神经网络法、可拓识别法等)等。吕玉广等 [2] 对王楼煤矿的水化学检测报告进行详细的整理分析,运用水化学特征法识别出煤系地层上段侏罗系砂岩裂隙水是该矿井的突水来源;周健等 [3] 选取距离判别方法准确地判别出梧桐庄煤矿突水水源,并与之前该矿采用的神经网络识别结果对比,认为距离判别法可以对矿井水来源做出高效的判定;鲁金涛等 [4] 建立出主成分分析和Fisher判别分析综合模型,对突水水源予以判别,取得很好的成效。
安徽某矿区内主要充水含水组有新生界含水组、煤系砂岩裂隙含水组、太灰岩溶裂隙含水组及奥陶系灰岩岩溶裂隙含水组,其中影响该煤矿安全开采的含水层细分为煤层顶板砂岩含水层、煤层底板砂岩含水层与太原组灰岩含水层,需要重点研究分析。
本文将对影响该矿安全生产的各含水层水化学资料应用多种统计分析方法进行研究,主要采用聚类(系统聚类)分析、因子(主成分)分析和Bayes逐步判别分析 [5],进而构建矿井突水水源判别模型,对突水水源做出判别。
2. 矿井概况
该煤矿处在淮南煤田潘谢矿区境内,东和张集矿相接,西和刘庄矿相邻,南北分别是罗园煤矿和陈桥背斜。属于华北型石炭–二叠系煤田,主要含煤地层为二叠系的山西组与石盒子组,有经济价值的煤层共有六层,分别为13、11、8、6、4、1煤层 [6]。虽局部地段小型褶曲发育,造成地层起伏,但幅度较小,地层产状总体上变化不大,不会对煤矿安全开采产生较大影响 [7]。
矿区内地表水主要受济河影响,地下水主要赋存在岩溶裂隙、砂岩裂隙与新生界孔隙之中。在沉积作用的影响下,形成含水层与隔水层相间出现的复合承压水。整个矿区内无复杂构造,各含水层之间水力联系不密切,只在断层形成的导水通道处产生较小的补给关系。矿区主要含水层中煤系砂岩裂隙含水层存在范围最广,q值为0.0046~0.0872 L/s·m,富水程度大都较弱,且静储量占多数,但当受到大的扰动而使层间水力平衡遭受破坏时则可能发生水力联系并突水;太原组灰岩含水层均厚为103.38 m,q值约是0.096~0.0808 L/s·m,富水程度较弱,但此含水层岩溶发育明显,可能对矿井生产造成不利影响,曾直接作为东风井突水水源。所以,在矿井开采时,应予特别注意。
3. 突水水源的多元统计分析判别
矿井含水层水化学成分中含有8个主要离子,其中重点研究讨论的7种,总量可达水中离子成分的90%以上 [8]。这些离子对矿井水的性质类型起着决定性的作用,根据其差异可对矿井水化学类型进行划分,进而对矿井突水水源做出判别。
本次整理了该矿30个水样的水化学特征资料(如表1所示),水样主要采于煤矿东翼采区探测孔、(轨道与皮带)石门、主副井及风井等,采样与测试时间在1997~2017年之间,此时间段内煤矿开采产生的扰动总体不大,可能对矿井安全造成影响的含水层大体处于静态,因而是在静态条件下对水化学特征进行多元统计分析。

Table 1. Water sample data table (unit: mg/L)
表1. 水样数据表(单位:mg/L)
注:X1、X2、X3、X4、X5、X6分别表示K+ + Na+、Ca2+、Mg2+、Cl−、SO2− 4、HCO− 3;1、2、3分别代表煤层顶板砂岩水、煤层底板砂岩水、太原组灰岩水。
3.1. 突水水源的系统聚类判别分析
系统聚类的基本思想是将x个不一样的样本分为x个不同的类别,而后把性质最相似(距离较近)的两个样本划分成一类;再接着从x − 1类中查找相似程度最高的两类继续进行整合,重复前面步骤最后全部的样本被聚合成一类为止。系统聚类分析法简单、直观,一些类型难以区别的数据都能采用这种方法进行分类 [9] [10]。
为研究从该煤矿所采的煤层底板砂岩水、煤层顶板砂岩水及太原组灰岩水水样的类别和内部联系,对突水水源作出判别,选择系统聚类法所包含的组内联接法、组间联接法、最近距离法、最远距离法、质心法和Ward法等6种方法对样品进行聚类分析,度量区间除质心法和Ward法选用平方Euclidean距离外,其余使用Euclidean距离,以使聚类分析更加完善。
利用SPSS软件对30个样品予以聚类分析,可得到6种系统聚类树状图,其中采用最近距离法作出的系统聚类树状图(如图1所示)各样品间联接较为混乱,类别判定错误较多。从图1中可以看到,按照实际所分的3个组别来看,30号样品划为单独一组,1~10号样品为一组,11~29号样品为一组,与表1所示的各样本真实所属水源类别相比差距较大,故最近距离法分类效果不理想。
所选用的系统聚类中另外5种方法皆可较好地对水样类别作出划分。例如图2组间联接法树状图所示,按照实际3个组别来分,除15号样品分类错误外,其余样品划分均与实际情况相符,1~10号样品为一组,21~30号样品为一组。
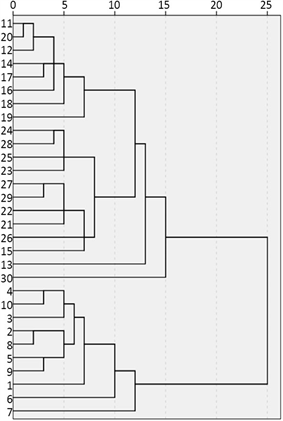
Figure 1. The dendrogram of the nearest distance method
图1. 最近距离法树状图
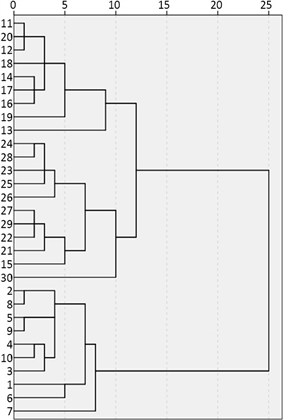
Figure 2. Tree diagram of the connection method between groups
图2. 组间联接法树状图
Ward法聚类效果最好,从图3可以看到,只有15号样品与21~30号样品划分成一组,不同于实际情况,其它样品均划分正确,且联接清晰,易区分,基本无链状连接情况。
根据系统聚类树状图并结合矿井实际水文地质资料分析可知,15号样品在6种聚类法中均与21~30号样品聚成一组,可能是由于煤层顶板砂岩水与太原组灰岩水存在一定的水力联系或有相同的补给源。在系统聚类所包含的6类方法中,组内联接法、组间联接法与最远距离法、质心法和Ward法的分类情况较相似。从系统聚类法的本质来看,质心法和Ward法处理样本信息的能力较强,聚类间距的紧缩性或舒张性也更为合理,聚类结果与实际情况也非常接近 [11]。因此,在判定该矿突水水源类别时,可以以质心法和Ward法系统聚类谱系图为基础,参考组内联接法、组间联接法与最远距离法的聚类结果来作出相对合理地分类判别。
3.2. 突水水源的Bayes逐步判别分析
Bayes逐步判别法的前提是已知全部样本划分为几类,然后对一个未知类别的样本进行统计分析,并根据Bayers判别准则予以类别判定。判别过程中选用的Bayes准则要求具有多个总体(3个及以上)。设N (N ≥ 3)类样本为N个总体T1,T2,……,TN (所有总体满足正态分布),假设某预判样品Y有X1,X2,……,Xn等n个判定变量,接着根据Wilks准则,从n个变量中挑选出极具代表性与判别能力强的变量作为判别函数因子,构建判别函数。比较样本Y代入哪一判别函数所得函数值最大,就归为哪一类(或比较Y属于哪一总体的后验概率最大,就归入哪一类)。
通常含水层离子间并非完全独立地存在于含水层中,往往各离子间会存在某些关联性,这说明离子之间会产生某些地质信息的重叠。如果直接用这7种离子判定突水水源,将会造成离子信息的多余或重复,使计算量变大及计算结果出现错误,也会引起突水水源的误判。
为判断所选样本各离子之间是否存在相关性及大小,先采用因子(主成分)分析对样本进行分析评价 [12] [13] [14]。通过SPSS软件对7种离子指标进行相关性统计分析,得到了如表2所示的相关系数矩阵。
Table 2. Correlation coefficient matrix
表2. 相关系数矩阵
由表2可知,Cl−与Mg2+、SO2− 4与Ca2+之间有着较强的相关性,其余离子变量之间也具有一定的相关关系,即存在信息重叠问题,在这种情况下,贝叶斯逐步判别法是可选方法之一。
该矿突水水源组成分别是煤层底板砂岩水1、煤层顶板砂岩水2、太原组灰岩水3。但贝叶斯逐步判别分析要求建立3个含水层的水化学判别函数,且母体变量测算值须满足多元正态分布及协方差阵无明显的不同。可当最大一组的样本容量与最小样本容量差距在合理范围时,假使母体的协方差阵不相等,对结果影响亦不会太大 [13]。
为了建立判别函数,以来自3个含水层的共计30个水样作为训练样本。通过SPSS软件对3个含水层的30组水样离子数据进行变量的正态分析,各变量正态分布显示较好,母体协方差阵虽不相等,但样本容量的差距在合理范围内。因此,为规避信息重合带来的计算错误,选取合适的分析变量作为判别函数的因子,可采用贝叶斯逐步判别分析对样本进行研究,从而得到表3。
Table 3. Identify the input variables step by step
表3. 逐步判别输入的变量
由表3可知,HCO− 3、Ca2+、Mg2+ 3个离子指标经逐步判别分析选为判别函数的计算变量,来对样品进行判别。假使各母体的先验概率大小一致,且选择合并的类内协方差阵作为分类矩阵 [15]。利用SPSS的逐步判别分析,得到3个含水层的贝叶斯逐步判别函数系数(如表4所示)。
Table 4. Classification function coefficients
表4. 分类函数系数
根据表4中的分类函数系数建立Bayes判别模型,所得的判别公式如下:
式中,X2、X3、X6所代表的含义同表1;Y1、Y2、Y3分别表示煤层顶板砂岩水、煤层底板砂岩水与太原组灰岩水的判别函数计算值。
根据样本判别原则,将待预测样品中HCO− 3、Ca2+、Mg2+的真实离子浓度量直接引入判别公式,计算得到函数结果并比较,水样代入哪一方程所求得的判别函数值最大,那么此水样就划入哪一含水层。
为对Bayes 逐步判别法判别突水水源的准确性进行验证,将初始水样相关离子浓度值回代入前已构建的Bayes判别函数中,按Bayes样本判别原则得出如表5所示的样本回代判别结果。
Table 5. The judgment result of sample back generation
表5. 样本回代判别结果
从表5中可以看出,Bayes逐步判别法对初始样本水源的判别结果与表1中初始样本真实水源完全相同。说明采用Bayes逐步判别法判别该矿突水水源具有极高的准确性,可用来对该矿突水水源情况作出判别。
4. 判别模型的应用
为了进一步验证所建立的突水水源系统聚类判别模型与Bayes逐步判别模型的准确性,选择如表6所示的待判样本数据,对该矿突水水源进行判别。
注:1、2、3所代表的含义同表1。
4.1. 系统聚类判别模型的应用
由前述已知,质心法和Ward法对突水水源类别的判定效果相比于系统聚类法中的其它方法更好。因此,选用这两种方法对表6中的待判水样数据进行判别验证,以说明该模型的可靠性。所得谱系图如图4~5所示。
由图4与图5的树状图,并结合待判样本来自3个含水层的实际情况可知,两种方法都将1与2聚为一类,3与4聚为一类,5与6划分为一类,即这两种方法对水样来源的分析判别结果与表6中待判水样所属水源的真实结果相同。从而,进一步说明系统聚类法中的质心法和Ward法对水源识别具有很高的准确性,可用来判别该矿突水水源。
4.2. Bayes逐步判别模型的应用
将表6中待判水样的Ca2+ (X2)、Mg2+ (X3)与HCO− 3(X6)离子浓度值代入到判别式中,求得判别函数值,并依据判别原则得出如表7所示的突水源判别结果。

Figure 4. Density diagram of centroid method
图4. 质心法树状图
Table 7. Bayes step-by-step discrimination results of samples
表7. 样品的Bayes逐步判别结果
据表7所示,待预测水样的Bayes逐步判别结果与实际结果相同,对突水水源的判别结果全部正确。这表明基于SPSS软件采用Bayes逐步线性判别法能够对地质信息进行很好地处理与分析,可在很大程度上避免因信息重叠造成的识别效果差的问题,对矿井突水水源的识别具有很高的准确性及实用性。
5. 结论
采用系统聚类法中的组内联接法、组间联接法、最近距离法、最远距离法、质心法和Ward法等6种方法对某矿区突水水源进行分析判别,其中质心法和Ward法判别效果最好,在判别突水水源时最近距离法判别不清,较为混乱,其余方法的判别结果较好,可为该矿突水水源判别时作参考。
采用因子分析说明水中各离子之间具有一定的相关性,存在信息重叠。而Bayes逐步判别法可以规避信息重合问题,提高判别结果的准确性。经过严格的分析验证,表明Bayes逐步判别法对该矿突水水源的判别效果很好。
综合对比两种判别方法可知,Bayes逐步判别法判别该矿突水水源准确率很高,基本无错误,而系统聚类在判别时出现误判情况。因而建议该矿判别突水水源时首选Bayes逐步判别法。