1. 引言
计算机通过多层次的网络结构,构建简单的“认知”来学习复杂的概念,这种方法被称为AI深度学习 [1]。它的另外一种解释是一种以人工神经网络为架构,对数据进行表征学习的算法。在当前人工智能的发展中,深度学习起到了中流砥柱的作用。我们一般通过构建神经网络来进行深度学习。现如今已有很多种深度学习的框架模型,例如深度神经网络(DNN) [2]、卷积神经网络(CNN) [3]、置信神经网络(DBN) [4] 和递归神经网络(RNN) [5]。它们被应用在计算机视觉、自然语言处理、语音识别与生物信息学等领域并获得极好的效果 [6] [7] [8]。
深度神经网络是一种具备至少一个隐藏层的神经网络。我们在构建多层次的网络模型时,经常会遇到过拟合的问题。如何防止过拟合成为深度学习的关键问题之一。减弱过拟合的方法有L1、L2和Dropout等正则化方法 [8]。L1正则化通过稀疏化权重,而L2正则化通过缩小权重,从而达到减小过拟合现象。Dropout正则化方法通过“模型平均”和减小神经元之间的共适应性从而达到减弱过拟合现象。
最后本文构建了784-1000-500-10的深度前馈全连接神经网络,基于L1,L2和Dropout正则化进行MNIST手写体实验。
2. 正则化
一般正则化方法都是通过对目标函数J添加一个参数惩罚项
,来限制神经网络模型的学习能力 [9]。我们将正则化的目标函数记为
:
(1)
其中
是平衡范数惩罚系数项
和标准目标函数
相对贡献的超参数。当我们的训练算法最小化正则化后的目标函数
时,它会减少标准目标函数
关于训练数据的误差并同时减少参数
的规模。选择不同的参数范数
会偏好不同的解法。
2.1. L1正则化
参数正则化是通过向目标函数函数添加正则项
,使权重更加靠近坐标轴。我们可以将
参数正则化目标函数的二次近似分解成关于参数的求和:
(2)
其中w*是最优的目标解,H是海森矩阵。最小化近似代价函数的解析解是:
(3)
从这个解可以得到两种结果:若
,
正则化使得
趋向0;若
,
正则化使得
增加了
。
下面借助一张图来解释
正则化的思想。如图1所示,坐标轴右上方的同心椭圆表示原始目标函数
的等值线,中心点
是没有正则化的原始最优解。图中(虚线)菱形表示
正则化项的等值线。最小化新的目标函数
,需要让
和
都尽可能小。在
点处,这两个竞争目标达到平衡(
点为新的目标函数的最优解)。
很大时,
直接等于0;
较小时,
被拉向0。并且由于
正则化项图像的特殊性,
很容易就会出现在坐标轴上,即
正则化会让权重矩阵变得稀疏,使得网络复杂度降低,这也是为什么
正则化能够防止过拟合。
2.2. L2正则化
参数正则化是通过向损失函数添加正则项
,使权重更加接近原点。可以得到加入
正则化项的总的目标函数的梯度为:
(4)
使用梯度下降法更新权重,过程如下:
(5)
每次更新梯度前,都会先对权重向量乘以一个小于1的常数因子,这也就是
正则化称被为权重衰减的原因。记加入正则化项之后的最优解为
,有:
(6)
其中可以通过特征分解将海森矩阵H分解成一个对角阵
和一组特征向量的标准正交基Q,即
。解得:
(7)
由上面的情况可以看出,海森矩阵的特征值大小决定这权重的缩放程度。而海森矩阵的特征值表示的意义是该点附近特征向量方向上的凹凸性,特征值越大,对应的凸性越强。目标函数下降快的方向对应于训练样本的通用的特征方向,而下降的慢的方向则是会造成过拟合的特征方向。下面借助一张图来更形象的理解一下
正则化的效果。
如图2,最小化新的目标函数
,需要让
和
都足够的小。在
点处,两者达到平衡。
点为新的目标函数的最优解。当正则化系数
越大时,
越接近零点;
越小时,
越接近
。我们看到,目标函数
的海森矩阵的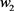 方向上的特征值很小,由图2,我们看到正则化项将
方向上的特征值很小,由图2,我们看到正则化项将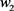 拉向零。再看,代价函数对于沿着
拉向零。再看,代价函数对于沿着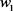 所在方向的移动较为敏感,因为对应海森矩阵的特征值比较大,表现为高曲率。因此,权重衰减对
所在方向的移动较为敏感,因为对应海森矩阵的特征值比较大,表现为高曲率。因此,权重衰减对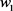 所在方向影响较小。
所在方向影响较小。
通过上面的分析我们发现,保留的相对完整往往是有助于减小目标函数方向上的参数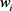 。而无助于目标函数减小的方向上的参数会在训练中逐渐的衰减掉。这也就是说,在目标函数添加
。而无助于目标函数减小的方向上的参数会在训练中逐渐的衰减掉。这也就是说,在目标函数添加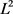 正则化项会使模型的参数倾向于比较小的值,针对参数减小了模型拟合各种函数的能力,从而减弱模型的过拟合现象。
正则化项会使模型的参数倾向于比较小的值,针对参数减小了模型拟合各种函数的能力,从而减弱模型的过拟合现象。
2.3. Dropout
下面通过两张图来简单了解一下标准神经网络和应用Dropout之后的差异 [10]:
图3为一个含有两个隐藏层的标准神经网络。而图4则是图3的神经网络应用Dropout之后的产生的稀疏网络,其中带叉的神经元已经被剔除。
下面介绍Dropout的具体工作流程,假设我们要训练图5所示神经网络:
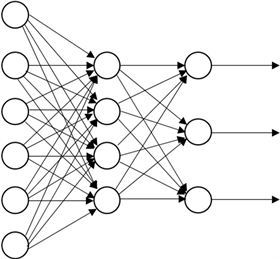
Figure 5. Schematic diagram of neural network
图5. 神经网络示意图
步骤一:遍历网络所有的隐藏层,随机删除掉网络中隐藏层的部分神经元,输入层和输出层保持不变,如图6所示,在最简单的情况下,每个单元都以固定的概率p保留;
步骤二:接着,输入x通过图3、图4所示的神经网络传播,然后反向传播。按照随机梯度下降法更新没有被删除的神经元对应的参数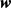 和b;
和b;
步骤三:最后重复如下过程:恢复被删除的神经元,随机删除的神经元的参数不会更新,没有被删除的神经元的参数得到更新。再从隐藏层随机删除一部分神经元,并备份被删除神经元的参数。在划分的小的训练集执行完这个操做之后,按照随机梯度下降法更新没有被删除的神经元对应的参数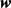 和b。被删除的神经元的参数保持原来的结果。而在测试的时候,网络的神经单元一直存在,而权值要乘于p。这样做是为了保证测试时的输出与训练时的输出期望相同。
和b。被删除的神经元的参数保持原来的结果。而在测试的时候,网络的神经单元一直存在,而权值要乘于p。这样做是为了保证测试时的输出与训练时的输出期望相同。
下面是这两种情况的示意(图7):
将Dropout应用到神经网络中相当于从神经网络抽取一个稀疏网络。稀疏网络由所有Dropout存活的单元组成(见图6)。一个有n个单元(隐藏层单元)的神经网络,可以看作是有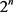 个可能的神经网络的集合。这些网络共享权重,因此参数的总数仍然是
个可能的神经网络的集合。这些网络共享权重,因此参数的总数仍然是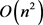 或更少。对于每次训练集的输出,将对一个新的稀疏网络重新训练。因此,训练一个Dropout神经网络可以看做是训练
或更少。对于每次训练集的输出,将对一个新的稀疏网络重新训练。因此,训练一个Dropout神经网络可以看做是训练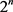 个具有大量权重共享的稀疏网络的集合,每个稀疏网络很少接受训练,如果这种情况发生的话(训练单独的稀疏网络)。在测试时,使用单一的神经网络而不Dropout。该网络的权值是训练权值的“缩减版”,这样就类似于
个具有大量权重共享的稀疏网络的集合,每个稀疏网络很少接受训练,如果这种情况发生的话(训练单独的稀疏网络)。在测试时,使用单一的神经网络而不Dropout。该网络的权值是训练权值的“缩减版”,这样就类似于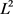 正则化的权重缩减。如果一个单元在训练过程中以概率p保留,则该单元输出的权值在测试时乘于p,如图8所示。这可以确保对于任何隐藏单元,预期输出(在训练时用于删除单元的分布下)与测试时的实际输出相同。在测试使用时,经过这样的交织,
正则化的权重缩减。如果一个单元在训练过程中以概率p保留,则该单元输出的权值在测试时乘于p,如图8所示。这可以确保对于任何隐藏单元,预期输出(在训练时用于删除单元的分布下)与测试时的实际输出相同。在测试使用时,经过这样的交织,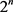 个共享权值的网络可以组成一个单独的神经网络。
个共享权值的网络可以组成一个单独的神经网络。
那么Dropout是如何防止过拟合,从而实现正则化的呢?总结为以下两点:
平均的作用:在标准的神经网络模型(没有用任何正则化方法)中,我们利用相同的训练集去训练m个不同的神经网络,一般会得到m种结果。如果我们采用取均值的方式来决定最终的模型,那么这种综合多个模型取均值的策略可以有效的减小过拟合。因为不同的网络可能会产生不同程度的拟合效果,取平均值会在一定程度上使过拟合和欠拟合相互抵消。Dropout在训练时忽略部分神经元,训练不同的稀疏网络,并让这些网络共享权重,这样付出的代价要低。在测试的时候,恢复所有的神经元,相当于很多不同的神经网络取平均。这样在一定程度上使过拟合和欠拟合相互抵消达到整体上减小过拟合。
降低了神经元之间的适应性:一个100个人一起完成的计划,要比100个人均分为20组完成20个任务要困难的多。因为前者需要50个人的默契配合,后者显然提高了这方面的容错率。Dropout在训练过程中,两个神经元不一定每次都会在一个Dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐藏层神经元的共同作用,一定程度上避免了一些特征只有在特定特征下才有效果的情况,迫使网络学习更加鲁棒(指系统的健壮性)的特征,从而降低了神经元之间的适应性,达到减小过拟合的效果。
3. 正则化在MNIST手写体识别中的应用
MNIST手写体是NIST提供的用来进行神经网络实验的数据集,包含60,000张手写数字的二进制数据组成的训练集和10,000张相同规格的二进制图像组成的测试集。在本文实验中,我们训练和测试用的数据,用的是MNIST数据集的784维的二进制数据,输入的像素是灰度级的,值为0表示白色,值为1.0表示黑色,中间值表示逐渐暗淡的灰色。因此我们构建的全连接前馈神经网络的输入层的神经元的个数为784个。为了实现更好的拟合效果,我们把第一个隐藏层的神经元的个数设置为1000,第二个隐藏层的神经元的个数设置为500。最后是输出层,因为手写体上包含0~9十个数字,因此我们的输出层的神经元的个数设置为10。网络的示意图如下(图9):
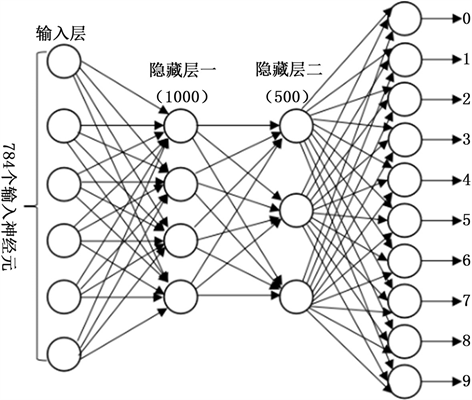
Figure 9. 784-1000-500-10 net
图9. 784-1000-500-10网络
隐藏层激活函数我们选用双曲正切函数: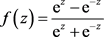 。输出层的激活函数我们选用Softmax函数,它的主要作用是是将多个神经元的输出,映射到0~1的区间上,按照概率的高低进行分类,各个输出神经元的概率之和为1。形式如下:
。输出层的激活函数我们选用Softmax函数,它的主要作用是是将多个神经元的输出,映射到0~1的区间上,按照概率的高低进行分类,各个输出神经元的概率之和为1。形式如下: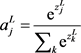 。目标函数们采用交叉熵函数,在犯错的情况下能够学习的更快,其具体形式如下:
。目标函数们采用交叉熵函数,在犯错的情况下能够学习的更快,其具体形式如下:
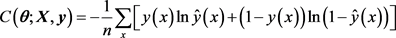
在本文实验中,我们采用的学习速率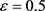 ,Dropout的存活概率为0.5,
,Dropout的存活概率为0.5, 正则化的惩罚系数
正则化的惩罚系数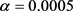 。本文实验的平台是Ubuntu,运用的python版本是3.6.7,TensorFlow的版本是1.13.1。下面是运行结果:
。本文实验的平台是Ubuntu,运用的python版本是3.6.7,TensorFlow的版本是1.13.1。下面是运行结果:
我们分别取上述四种情况的测试准确率进行比对,如下(图10):
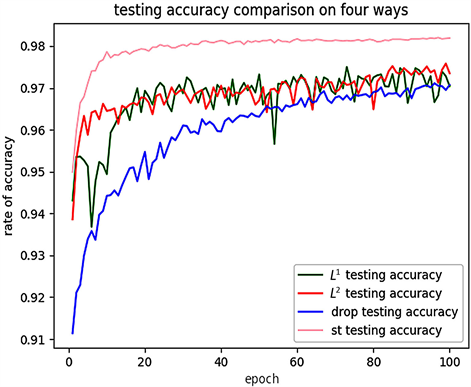
Figure 10. Comparison of test accuracy in four cases
图10. 四种情况下的测试准确率对比
对应的表格如下(表1):

Table 1. Four cases test accuracy rate partial training cycle results
表1. 四种情况测试准确率部分训练周期结果
由图10,我们看到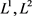 正则化测试准确率上下震荡比较厉害,而Dropout只有小幅度的震荡,并且由表4.5,在80~100个epoch,三者的测试准确率都在97%左右,由此看出Dropout作用后拟合效果(相对于
正则化测试准确率上下震荡比较厉害,而Dropout只有小幅度的震荡,并且由表4.5,在80~100个epoch,三者的测试准确率都在97%左右,由此看出Dropout作用后拟合效果(相对于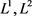 )比较好。我们分别取上述四种情况的训练准确率进行比对,如图11。
)比较好。我们分别取上述四种情况的训练准确率进行比对,如图11。
对应的表格如表2。
下面我们对比部分周期四种情况下的训练误差和测试误差的差值。
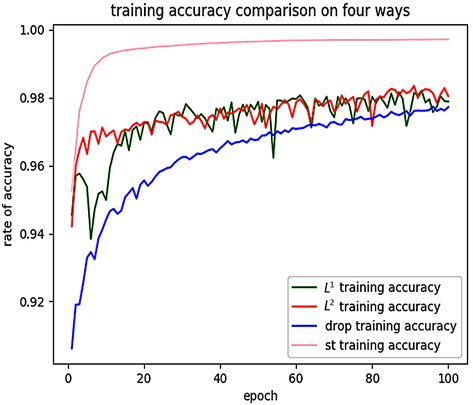
Figure 11. Comparison of train accuracy in four cases
图11. 四种情况下的训练准确率对比
Table 2. Four cases train accuracy rate partial training cycle results
表2. 四种情况训练准确率部分训练周期结果
Table 3. Four cases of accuracy rate difference part of the training cycle results
表3. 四种情况准确率差值部分训练周期结果
由表3,我们发现Dropout最终将准确率的差值缩小到0.65%,相比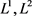 正则化的0.69%,0.84%效果较好。综上对于784-1000-500-10的深度神经网络,Dropout的正则化效果相对较好。
正则化的0.69%,0.84%效果较好。综上对于784-1000-500-10的深度神经网络,Dropout的正则化效果相对较好。
4. 结论
1)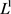 参数正则化会趋于生成少量的权重,而其他权重都变为0。如图1,由于
参数正则化会趋于生成少量的权重,而其他权重都变为0。如图1,由于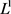 正则项函数的特性,参数的最优值很大概率会出现在坐标轴上。这样就会导致
正则项函数的特性,参数的最优值很大概率会出现在坐标轴上。这样就会导致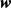 的某一维变为0,使得权重矩阵变得稀疏,并且网络复杂度降低,从而一定程度上减小过拟合。
的某一维变为0,使得权重矩阵变得稀疏,并且网络复杂度降低,从而一定程度上减小过拟合。
2)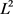 参数正则化则会保留更多(相对于
参数正则化则会保留更多(相对于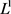 参数正则化)的权重,但是这些权重都会在不同程度上逼近于0。如图2,
参数正则化)的权重,但是这些权重都会在不同程度上逼近于0。如图2,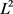 参数正则化的最优的参数只有很小概率会出现在坐标轴上,因此
参数正则化的最优的参数只有很小概率会出现在坐标轴上,因此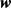 的每一维基本都不会是0,而是在正则化下逼近于0。它通过衰减参数减小了模型拟合各种函数的能力,从而减弱模型的过拟合现象。
的每一维基本都不会是0,而是在正则化下逼近于0。它通过衰减参数减小了模型拟合各种函数的能力,从而减弱模型的过拟合现象。
3) Dropout则是在训练时忽略部分神经元,训练不同的稀疏网络,并让这些网络共享权重。在测试的时候,恢复所有的神经元,即所有的稀疏网络交织在一起,相应的权重乘以概率p,相当于很多不同的神经网络取平均。这样在一定程度上使过拟合和欠拟合相互抵消达到整体上减小过拟合。并且在训练不同稀疏网络时,两个神经元不一定每次都会在一个Dropout网络中出现。这样权重的更新不再依赖于有“逻辑关系”的隐藏层的神经元的共同作用,一定程度上避免了一些特征只有在特定特征下才有效果的情况,迫使网络学习更加鲁棒(指系统的健壮性)的特征,从而降低了神经元之间的适应性,达到减小过拟合的效果。
4) 在MNIST手写体实验中,我们构建784-1000-500-10的深度神经网络,并进行正则化处理。结果表明Dropout的正则化效果会更好,最终的准确率稳定在97%,训练误差与测试误差的差值为0.65%。