1. 引言
《红楼梦》是中国古典四大名著之一,清代作家曹雪芹创作的章回体长篇小说。由于其在传播和保留过程中出现缺失,当下普遍的观点是前80回是曹雪芹所著,高鹗续写后40回。
前人的论述已经多从文学用语和数理统计学两大方面反复地论证过,并且得出结论:《红楼梦》前80回与后40回的作者并非同一人,甚至《红楼梦》全书也非一个作者所著。瑞典汉学家高本汉(B. Karlgren) 早在1952 年用统计学方法分析了32个语法和京话与口语词汇的用字习惯,认为全部120回均为曹雪芹所著 [1];而胡适先生在20世纪20年代用文本的文学分析和文献考证方法认定前80回为曹雪芹所著,而后40回为高鹗所著 [2];至今,更加有人认为,前80回也并非出自同一人之手 [3]。
采用统计方法进行研究的主要有:李国强 [4] 等根据《红楼梦》的词频及其相关性进行研究,得到前中后各40回的相关度很高,但两两相关度很低的结论。而施建军 [5] [6] 利用支持向量机方法得到了前80回和后40回在写作风格上存在明显差别的结论,但其聚类方法不能为判断作者提供可靠的依据。叶雷 [7] 则使用文体特征进行K-means聚类,得到了后40回不是前80回作者所著的结论。
本文主要利用特征聚类对《红楼梦》前80回和后40回进行文本分析。分析《红楼梦》120回的词量、词频,确认其是否为同一作者所著,并用等价性检验模型进行验证。
2. 基于等价性检验的《红楼梦》作者分析模型
2.1. 数据预处理
统计全文中“红”、“玉”的字频,得到表1所示数据。根据表1的数据可以绘制“红”、“玉”二字在前80回和后40回的频率,如图1所示。由此,容易看出“红”、“玉”两字在前80回与后40回的频率存在差异。

Table 1. Statistics of frequency of “red” and “jade” in the full text
表1. 全文中“红”和“玉”的频数统计表

Figure 1. The frequency of the words “red” and “jade” in the first 80 chapters and the latter 40 chapters of A Dream of Red Mansions
图1. 《红楼梦》中“红”“玉”二字在前80回频率和后40回频率
2.2. 等价性检验模型的建立与求解
选取等价性检验模型,假设前80章与后40章两个样本并未存在显著差异,即作者为同一人。根据表1,《红楼梦》前80章回和后40章回的“红”字和“玉”字出现的频数分析数理统计学的问题,求解等价性检验模型。这一检验问题可化为两个相互独立的二项总体的等价性检验,此时:
表示前80回的二项分布,其中
,
表示前80章回的“红”字出现的频数,其实测值为
,
表示前80章回“红”字出现的频率;
表示后40回的二项分布,其中
,
表示后40章回的“红”字出现的频数,其实测值为
,
表示后40章回“红”字出现的频率。
采用渐进正态检验,计算检验统计量U,进而计算检验的p值,即:否定原假设而犯错误的概率。解得记“红”字的检验统计量
。重复上述步骤解得“玉”字的检验统计量
。等价性检验模型的U检验值与概率对照表如表2所示。
Table 2. Comparison between U test value and probability
表2. U检验值与概率对照表
通过表2可得:U检验值越大,则可信概率就越大,即:拒绝原假设,差异就越显著。从数值模拟获得的数据分析,“红”、“玉”两字的U检验量足够大,表明前80回与后40回确实存在显著差异。
但无论观察图表,或是对照等价性检验的结论,都可以发现其中明显的问题:等价性检验所呈现的结果存在偏差,寻找其原因也能很容易发现,“玉”字与主角名字有很大的关系,而主角之一的“林黛玉”在后40章已经去世,这就对这个字的频数造成一定的影响。
综上,该方法中存在两个缺陷。其一,适用性差。因为需要抽取样本逐一进行等价性检验,对多个样本重复操作的过程将会十分繁琐;其二,模型稳定性差。针对于“红”和“玉”两个样本,出现了U检验值不小的差异,足以说明不同样本之间存在的差异性会受到其余因素的影响,且每个样本之间可能会出现矛盾。
所以,进一步选取特征聚类验证继续验证猜想。
3. 基于聚类分析的《红楼梦》作者分析
3.1. 数据处理
以每十章回为样本,分别对特征词频进行统计,选取代词进行统计,结果如图2。

Figure 2. Example of word frequency after word segmentation by part of speech (part of speech)
图2. 按照词性(词性)分词后统计的词频示例
根据分词结果统计每十回的代词词量,如下表3所示。
Table 3. Number of pronouns per decade
表3. 每十回的代词词量
其次,将各个代词的词频按照递减的顺序排列,选取词频排行前50的代词词频来作为第一次选取的特征向量,如图3。
显然在第一特征向量的代词中,并不是每个样本的第一特征向量的元素都相同,因此进一步提取数据。在第一特征向量中,统计在每个样本中都出现的元素,如图4。
根据我们划分样本的方式,上图中的数字为12的即表示每个样本中都包含的元素。因此,将每个样本中都包含的元素作为第二特征向量,每个向量中包含27个元素,即为最终选取的特征向量。并将每个样本中的数据进行提取,最终的数据提取的结果如图5所示。

Figure 5. Finally selected data example
图5. 最终选取的数据实例
根据选取的27个特征值,依次提取相应的词频,组成特征向量,如图6。

Figure 6. 12 eigenvector data of samples
图6. 12个样本的特征向量数据
3.2. K均值聚类和凝聚聚类的聚类结果分析
使用python机器学习模块Scikit-Learn模块进行求解。
将K均值聚类模型实例化,将处理后的特征向量应用到算法模型中,解得:

Figure 7. K-means clustering of two categories
图7. K均值聚类两个类别的聚类情况
从图7来看,容易发现第21回到第80回分自然的分在了一个类别,而前20回却和后40回分在了一起,这说明:前20回合后40回有更好的相似性。这不符合预计结果,猜想可能原因是前80回内部存在相似性存在一定的差异。
为进一步分析上述结论的原因,现将特征向量应用到新的算法模型中,该算法模型训练3个簇,即3个类别。实验结果如下图8所示:
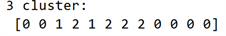
Figure 8. K-means clustering of three categories
图8. K均值聚类三个类别的聚类情况
从图9的实验结果来看,我们很容易发现从第21回到80回内部存在一定的差异性,被分成了两个类别;而前20回和后40回仍被分在了一个类别。该实验结果只说明了:第21回到第80回内部存在差异性。
再次训练新的算法模型,该算法模型训练4个类别,实验结果如图9。

Figure 9. K-means clustering of four categories
图9. K均值聚类四个类别的聚类情况
这个实验结果很明显看出,前80回合后40回内容存在差异,不是同一个人所著。但同时,前80回同样存在差异,因此我们可以以这个结果进一步进行猜想,《红楼梦》不仅有两个作者,可能存在两个以上的编撰者。
凝聚聚类算法的处理方式与K均值聚类的方式相似,将图6的特征向量应用到凝聚聚类算法模型中。分别试验聚成两个类、三个类、四个类的算法模型,实验结果如图10。

Figure 10. Clustering of clustering into 2, 3 and 4 categories
图10. 凝聚聚类分别聚成2,3,4个类别的聚类情况
从图10很容易发现:在采用凝聚聚类聚成3个类别的时候,能够很显然的体现出前80回和后40回作者不一,而在前80回中,前20回和其他60回作者存在差异。
4. 总结与展望
综合上述模型求解结果,等价性检验模型虽然作为数理统计中优秀的模型,但依旧有着不小的局限性,在处理多个样本的情况下,K均值聚类和凝聚聚类反而得到了优秀的结果。从最终的实验结果可以观察出,根据分析《红楼梦》前80回和后40回的部分词量和词频,可以表明《红楼梦》前80回和后40回并不是同一作者所著。除此之外,我们还发现,在前80回内的文章也存在着不小的差异。因此可以一定程度上表明,《红楼梦》不止一个作者所著。
基金项目
闽江学院校长基金(103952018230)。
NOTES
*通讯作者。