1. 引言
在云计算、物联网等技术的带动下,社会已经步入大数据时代。计算机实验在其组织、运行、实施过程中会产生丰富的文本数据,如学生遇到的理论知识点问题、实践操作问题、实验进度、实验时间、实验结果和创新性想法等,且实验中的问题往往依靠师生口头交流解决,缺乏相应数据记录,更无法进行数据分析。如何从产生的文本大数据中提取出隐含的、有价值的信息,提升学生对知识点的理解、提高学生的学习效率和教师的教学质量,是目前高校计算机实验教学亟待解决的问题。
为了解决上述问题,本文提出了一种DBSCAN优化算法;同时,设计了一种文本聚类流程。首先,将文本进行分词处理以提取特征;接着,利用SVM将文档映射为一个特征向量,并且通过SD-TF-IDF算法对特征项的权值进行优化;利用DBSCAN优化算法对文本进行聚类,计算文本相似度,将相似度低于阈值的文本作为孤立点进行处理 [1],来寻找核心数据对象的密度可以达到的数据点过程,从而实现对高校计算机实验文本大数据的智能化管理。
2. DBSCAN聚类算法
DBSCAN全称为Density-Based Spatial Clustering of Applications with Noise,这是一类基于密度的聚类算法,由Martin Ester、Hans-PeterKriegel [2] 等人在1996年提出。其与划分和层次聚类方法不同,不需要预先指定簇的个数,将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类 [3],通过过滤低密度的样本区域,来发现稠密的样本区域。
该算法是基于一组“邻域”参数(Eps, Minpts)来描述样本分布的紧密度,假设给定样本集合
,DBSCAN聚类算法涉及的相关定义如下:
定义1 Eps-邻域:空间中任意给定对象半径Eps内的邻域称为该对象的Eps-邻域;
定义2核心对象:如果给定对象Eps-邻域内的样本点数大于等于密度阈值Minpts,则称该对象为核心对象;
定义3直接密度可达:对于样本集合D,如果样本点q在p的Eps-邻域内,并且p为核心对象,那么对象q从对象p直接密度可达;
定义4密度可达:对于样本集合D,给定一串样本点
,p = p1,q = pm,假如对象pi从pi-1直接密度可达,那么对象q从对象p密度可达;
定义5密度相连:存在样本集合D中的一点o,如果对象o到对象p和对象q都是密度可达的,那么p和q密度相连;
定义6边界点:若对象p不是核心点,对象p密度可达其他核心对象,则将对象p称为边界点。
定义7噪声点:既不是核心点也不是边界点的点为噪声点。
DBSCAN聚类算法的核心思想是:先发现密度较高的点,然后把相近的高密度点逐步连成一片,进而生成各种簇。
3. DBSCAN聚类算法的优化
3.1. DBSCAN优化算法的思想
根据聚类假设原理,同一类的文本相似度比较大,不是同一类的文本之间的相似度就比较小 [4]。聚类算法是一种自主的无监督机器学习方式,聚类不用提前对文本进行手工标注类别,也无需经过训练样本。因此,它具有比较高的自动化处理能力和灵活性,是现在对文本信息进行有效组织、导航和摘要的重要手段之一 [5]。
然而,传统的DBSCAN算法需要在无先验知识情况下人工设定Eps和Minpts参数,如果参数选择不合理将导致聚类结果不理想;同时,DBSCAN算法虽然聚类速度快,且能有效处理噪声点以及发现任意形状的空间聚类,但当数据集的数据量比较大的时候,查找邻域数据对象所消耗的时间会变得越来越多,降低算法运行效率。
因此,本文提出了一种DBSCAN优化算法,较好地解决了算法参数自适应和算法速度问题。首先,将数据对象放入一颗KD树中,加快查找到邻域对象,使得算法的运行时间大大减少;同时,在查找邻域数据对象的过程中,将数据对象之间的欧几里得距离与Eps参数做比较,以确定其是否为当前数据对象的邻域对象。在每次比较中,计算所有邻域对象的数学期望,即可实现Minpts参数自适应。
3.2. DBSCAN优化算法的步骤
根据上述算法思想,DBSCAN优化算法的具体步骤如下:
输入:含有n个数据对象的数据集D,半径参数Eps。
输出:生成满足密度要求的簇。
步骤1:将数据集合D中n个数据对象构建成一棵KD树;
步骤2:遍历数据集合D,从KD树中搜索当前数据对象p的最近邻域对象也就是对象p的密度可达对象,得到当前数据对象p的邻域;
步骤3:统计每个数据对象p的邻域数据对象数量,得到数量i;
步骤4:计算邻域数据对象的数学期望,得到Minpts=i/n,返回Minpts;
步骤5:从数据集合D中随机抽取一个为被处理的对象p,且在它的Eps-近邻满足密度阈值要求称为核心点;
步骤6:遍历数据集合D,从KD树中搜索当前数据对象p的最近邻域对象也就是对象p的密度可达对象,形成一个新的簇;
步骤7:通过密度相连产生最终簇结果;
步骤8:重复执行步骤3和步骤4,直到数据集中D中所有数据对象都标记为“已处理”。
4. 基于DBSCAN优化算法的文本聚类
为了测试本文算法性能,设计了一个基于DBSCAN优化算法的文本聚类流程。
4.1. 文本预处理
对文本数据进行聚类前,需要对其进行预处理。
4.1.1. 文本特征提取
首先,对文本进行分词处理。如中文文档就通过使用砌词和字典等方式进行分词操作,计算机会自动运行分词的过程 [6]。因为文档数据中会存在没有太大意思的符号和词汇等 [7],所以在分词的过程中,应去除掉这些没有意义的符号和词汇;同时,文档中还有存在多个同义词的情况,因此需要将这些同义词合并操作,如“信息”与“讯息”就是属于同义词,所以可将它们合并成“信息” [8]。
经过分词操作后,出现一大推的特征词汇,如词组或者词条等,大部分的特征词汇对文本的挖掘没有太大的意义,就需要对这些词汇进行按需的筛选,这样才能有效地提高聚类算法的性能和精确性 [9];接着,本文使用TF-IDF算法找出文本中的关键词,将权值最大的n个关键词作为特征项代表文本进行聚类。
4.1.2. 文本特征向量化
本文使用空间向量模型VSM (Vector Space Model)将文档转化成n维特征向量空间。VSM把每篇文档都表示为特征项-权值向量,把文本看作是一系列特征项t的集合,对每个特征项赋予对应的权值 [10]。
文档x映射为n维向量
:
(1)
其中,n:维度,特征项的数量;
;
:文档x的第k个特征项;
:文档x的第k个特征项的权值;
通过TF-IDF算法计算权值,公式如下:
(2)
其中,
:词频,指文档x中某个特征项
出现的次数;
:逆文档频率,表示一个特征项在整个文本集合中分布情况,计算方法如下:
(3)
其中,N为文档集合中的总文本数,
为文档集合中出现特征项
的文档数目。
4.1.3. 文本特征的权值优化
上述TF-IDF算法将文档集合作为整体来考虑,不足之处在于不能反映特征项在类间和类内的分布信息对权值计算的影响,故本文对特征项的权值计算方法进行优化,利用SD-TF-IDF算法优化权值计算。
特征项的分布信息又称为特征项频率分布的离散度。离散度可分为类间离散度
(distribution information among classes)和类内离散度
(distribution information inside a class)两种,分别表示特征项在类间与类内文档间的分布差异。
特征项的类间离散度
,表述特征项
在各类文档中分布的均衡度,公式如下:
(4)
m:文档类别数;
:特征项
在第i类文档中出现的频度;
:特征项
在各类文档中出现频度的平均值;
:特征项
在各类文档中出现的总频度。
特征项的类内离散度
,表述特征项
在某类文档中分布的均衡度,公式如下:
(5)
n:第i类中文档总数;
:特征项
在第i类第j篇文档中的出现频度;
:特征项
在第i类各篇文档中出现频度的平均值;
:特征项
在第i类各篇文档中出现的总频度。
在数学中非线性函数
和Sigmiod函数
具有良好的收敛性和稳定性。
但相对于非线性函数而言,Sigmiod函数的收敛性和稳定性更好。因此,本文结合上述类内、类间离散度公式,将传统的TF-IDF公式进行Sigmiod函数运算,优化后的算法公式为SD-TF-IDF:
(6)
当特征项分布相对均匀时,其权值较大;反之,其权值较小。
4.2. 文本相似度计算
文本间的相似度是通过使用空间向量余弦来计算的,两个文档的相似度是通过两个向量夹角的余弦值来对比,余弦相似度比距离度量更加强调两个向量方向上的差异 [11]。余弦相似度的计算公式如:
(7)
文档x与文档y的空间向量分别为:
与
。
因余弦相似度是从方向区分差异,缺少绝对值的敏感度,因此通过调整余弦相似度在所有维度数值上都减去一个均值来修正余弦值无法衡量维数差异的问题 [12]。调整余弦相似度的公式如:
(8)
n:维度;
:文档x的第k个特征项的权值;
:文档x所有特征项的平均数;
:文档y的第k个特征项的权值;
:文档y所有特征项的平均数。
4.3. 文本聚类步骤
在文档集合中任意选取一篇没有经过处理的文档p,然后对文档p进行标示已经处理,文档处理流程见图1所示。具体步骤如下:
1) 对文档p进行特征提取,并在提取的过程中对特征进行去噪处理,得到特征集合。
2) 使用SD-TF-IDF算法对文档集合中的所有文档进行特征集合的权值优化,得到一个n维特征向量。
3) 利用文本相似度算法计算文档p与文档集中其他的文档的相似度,假如和文档p相似度大于或等于设定阈值,就将存放在文档p的领域中,等着特征向量所有的数据全部处理结束。
4) 根据文档p领域中的文档数量,与Minpts值进行比较,假如大于Minpts设定值,则p为核心对象,继续往下执行,否则就需返回上一层,从文档集合中再抽取一篇未被处理过的文档,重新对新抽取文档进行处理。
5) 判断文档p是否属于某个簇,假如文档p没有属于那个簇,再建一个簇,并将文档放入这个簇中。
6) 从文档p领域中抽取一篇新的未处理多的文档r,并将标记文档r已被处理,对文档r得到领域的方式与文档p处理方式相同,判断r领域中文档的数量,是否大于Minpts设定值,大于就将文档r领域中的文档存放在文档p的簇中,一直将p领域的文档都处理完为止。
7) 文档集中的所有文档都已经处理完,算法结束。
5. DBSCAN优化算法在实验文本大数据分析中的应用
5.1. 实验
高校计算机实验在其组织、运行、实施过程中会产生丰富的数据。其中,文本数据处理具有一定难度。本文基于Hadoop和Spark混合框架设计并实现了一个面向高校计算机实验教学的大数据管理平台,用于采集、处理、分析和挖掘实验大数据。按照图1所示流程,首先,随机抽取464篇文档,包括面向对象程序设计文档相关文档44篇,数据结构与算法相关文档74篇,数据库原理及应用相关文档76篇,大数据技术相关文档270篇;然后,分别对每一个类别的文档进行预处理后,利用本文所提DBSCAN优化算法进行文本聚类,一共进行了8次聚类,结果见表1所示。
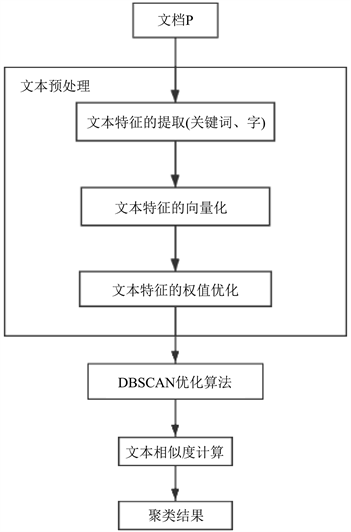
Figure 1. Text clustering based on DBSCAN optimization algorithm
图1. 基于DBSCAN优化算法的文本聚类

Table 1. Results of clustering calculation
表1. 聚类计算结果
5.2. 实验结果分析
从表1可以看出,文档集中的有些文档没有和其他类的文档聚在一起成为一类文档,而是单独成一些孤立的噪点,并且有些文档通过计算分析后,也没有准确聚到相似的簇中。当然,出现这些问题的因素比较多,例如有些文档中的特征不能很准确地反映出文档的特征,特征词汇对文档间的区分反应也不是很明显。但是,整体上来看,DBSCAN优化算法的聚类效果比传统算法的聚类效果要好,它可以能够很好将相似的文档聚类,有效地对文档数据进行分类管理。
6. 结束语
本文提出了一种DBSCAN优化算法,实现了参数的自适应选择,提高了聚类准确率,且兼顾了算法的运行效率;同时,设计了一种文本聚类流程。在实验文本大数据的应用中,通过DBSCAN优化算法对相似的文档进行聚类分析。实验结果表明,DBSCAN优化算法能有效地对大部分的文档进行聚类,实现了高校实验文本大数据的智能化管理,借此可以帮助教师完成实验教学文档的整理归类,为调整优化实验课程内容和方法提供可靠依据,有利于提高学生的学习效率,提升老师的教学水平,达到“智慧学”、“智慧教”的目标。
基金项目
教育部科技发展中心高校产学研创新基金——新一代信息技术创新项目(2018A01015),教育部科技发展中心高校产学研创新基金——新一代信息技术创新项目(2018A02027),国家自然科学基金项目(61871475,61471133)。
NOTES
*第一作者。
*通讯作者。