1. 引言
农产品溯源系统是对农产品从种植到销售的全生命周期进行跟踪的系统。基于农产品溯源数据对相关人员进行追责是保障农产品食品质量安全的重要手段。目前,许多地区已经使用信息系统实现了农产品的溯源跟踪,但相关数据易篡改,溯源信息难可信,事故责任难落实。溯源系统的信用危机严重影响了优质企业的发展。
区块链作为一种去中心化的数据存储技术,其维护的数据具备公开透明、不可篡改等特性。利用区块链技术为相关企业建立信任中心,可以有效地解决农产品溯源系统不安全不可信的问题。
本文总结区块链和溯源技术的发展现状,分析农产品溯源的需求特点,基于Hyperledger Fabric构架 [1],设计一种改进的联盟区块链农产品溯源方案。方案的实施可以进一步巩固相关企业在农产品产销领域的领先地位,对提升全社会农产品安全具有重要意义。
2. 相关研究
近年来,许多科研人员对农产品溯源技术进行了深入研究。文献 [2] 中实现了基于USB Key的水产品企业监管溯源系统,解决了水产品企业的溯源身份认问题;文献 [3] 利用猪肉生产和 HACCP体系相结合的方法筛选出溯源信息,实现了基于HACCP体系的绿色猪肉生产质量监管与溯源系统;文献 [4] 对我国种子质量可追溯系统进行了深入的分析和研究。上述溯源系统将数据存储于常见的集中式数据库内,容易遭到破坏或是企业自行篡改:掌握了集中式数据库的企业,可以为了自己的利益而随意修改数据;数据也可能被黑客窃取,或是因数据库单点故障而受损。这些问题会导致消费者无法溯源到真正的原始信息,使溯源系统失去可信度。
自比特币诞生起,区块链技术不断发展演进并逐渐成熟。目前,区块链生态形成了基于分布式账本、共识信任、非对称加密、智能合约等主要特征的应用范式 [5]。最为核心的特征是,区块链可在无中心权威机构的情况下,可使互相协作的参与方建立起基于数学模型的相互信任,实现去中心化 [6]。区块链的上链过程,是不断地将新数据转化为链上的历史数据的过程;而数据溯源的过程,就是将链上的历史数据按照时序还原为溯源数据,并将其可视化呈现的过程。Ramachandran等基于区块链实现了科学数据溯源管理框架SmartProvenance。该框架利用智能合约、开放溯源模型记录溯源信息,而区块链在其中承担数据的收集、验证和管理任务,以避免数据遭受恶意篡改 [7]。
区块链系统利用共识机制来维护多地数据一致。目前成功应用于公有链、联盟链和私有链中较为典型的共识机制有:工作量证明PoW机制、实用拜占庭PBFT机制、Paxos共识及其各类改进机制等 [8]。区块链天然具有的诸多特性,例如去中心化、流程透明、不可篡改,使得它成为数据溯源领域一大重要的技术趋势。不少研究人员注意到了区块链的特性,将研究方向转移到了基于区块链技术的溯源系统开发上 [9]。
文献 [10] 在区块链的语义下对当前物联网设备中常见的RFID标签数据定义了物联网大数据溯源安全模型。该模型采用了去中心化的思想分析RFID射频识别标签数据及其溯源信息,实现高信任度的权限验证和分布式管理。京东所开发的“智臻链BaaS平台”可以让用户通过简单、灵活的配置方式,快速搭建安全可靠的区块链网络,将商品相关的交易信息加密存储于区块链当中 [11]。天猫国际利用区块链技术、药监码技术以及大数据跟踪进口商品全链路,给进口商品打上唯一的身份证码,将商品生产、检测、运输、通关等环节的信息完整展现在用户面前 [12]。区块链企业VeChain发布了全球第一款基于区块链技术的NFC防伪芯片,并开发了一站式区块链BaaS (Blockchain as a Service)服务平台ToolChain [13]。
区块链溯源虽然已经被诸多企业应用到生产环境当中,但这些方案并没有很好地结合区块链和溯源需求的特点对方案流程及系统架构以进行整体改良。使用区块链技术虽然提高了溯源数据的可信度,但系统本身的可信管理以及弹性部署能力依旧有较大的提升空间。现有的区块链实现中,其数据查询、数据分析功能较为简单,随着区块链平台上应用与数据规模的增长,如何更高效地管理和查询溯源信息将是区块链溯源所要解决的重要问题 [14]。本文提出的基于Hyperledger Fabric构架的区块链溯源系统,充分结合农产品溯源的需求特点,在保证溯源可信的前提下,对系统构架及其查询方法进行了设计,有效提升了大规模数据上链和查询的速度。
3. 方案系统构架
本文实现的基于区块链的农产品质量安全溯源设计方案的系统构架如图1所示。该构架包括:区块链网络层、中间应用服务层、前端应用层。
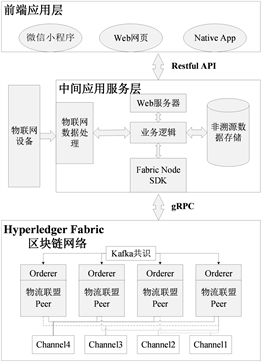
Figure 1. Framework of agricultural products traceability system based on consortium blockchain
图1. 基于联盟区块链的农产品溯源系统构架
3.1. 联盟区块链
参与农产品溯源链条的各方成员是权限角色地位不等的机关和企业,每个成员都是得到准入许可的可信参与方,这些成员组成拥有共同目的的企业联盟。联盟区块链的共识过程受若干个主要参与方管理,这种形式既能够保证系统运行的效率,又可以兼顾系统安全性和成员共同维护的特性。因此,联盟区块链也被称为“多中心”区块链。选用联盟链的具体原因有:1) 降低去中心化程度,减少共识过程中的资源浪费。2) 维护农产品安全溯源系统是联盟链中各参与节点的责任,区块链系统的运行无需激励机制。使用联盟区块链可以不依赖数字货币,简化记录账簿,降低系统运行所需算力与带宽。Hyperledger Fabric是开源的联盟区块链,提供完善的准入与安全机制。本文的联盟区块链构架基于Hyperledger Fabric。
本文的系统将农业基地、物流、销售、监管机构等参与方规划进入Hyperledger Fabric 联盟区块链的相应Channel,对相应信息进行查询和管理。Channel的结构如图2所示。每一个Channel都是一个虚拟的区块链网络,Channel和Channel之间相互隔离;Peer是参与区块链网络的服务节点。对于每一个Channel里的所有Peer,都会为该Channel维护相同的账本数据。此外,Channel中还运行着链码。链码是运行在区块链上的不可篡改的代码,是一种智能合约。Channel的账本数据分为两部分,一部分数据是链码调用记录,这部分数据以区块链的形式存储;另一部分数据是账本的当前状态,这部分数据以key-value数据库的形式存储。
对于消费者,第三方监管机构是数据可信的基础,因此,在联盟链中引入第三方监管机构的成员角色,任何数据都应该与监管机构共享。农业基地、物流、销售三方组织都和监管机构单独建立Channel,以分享需要被监管的信息。为维护农产品的声誉,农业基地也将大部分信息公开给所有用户。根据上述特征,本文的方案建立了四个Channel。
Channel1:农业基地、监管机构;
Channel2:物流、监管机构;
Channel3:零售、监管机构;
Channel4:农业基地、物流、零售、监管机构。
所有新加入系统的参与方都需要通过Fabric-CA (Certificate Authority)证书管理服务器为自己的节点和管理员用户创建证书。证书管理服务器基于非对称秘钥签名技术。服务器向每个参与方分发一对公钥和私钥,参与方在数据上传过程中使用私钥签名,以此来保证数据的可验证性。其他成员将可以用其公钥验证该参与者的身份与信息的来源是否真实。上传的每块数据均采用哈希算法给出校验,来判断数据内容是否被篡改。
所有溯源信息均存储在区块链中,并且支持被授权的节点对其进行访问。参与方在供应链中所拥有的职能决定其在区块链中所拥有的权限。每一次对区块链数据的操作都必须得到有权进行该操作的参与方的背书签名,才能够通过判断,分发到其他参与成员所在的区块链分布式存储模块中,因此数据的存储公开、透明。此外,区块链的协议规则由代码定义并存储在区块链中,无法被区块链中的某一参与者所篡改,从而保证数据的真实性与有效性。
每一方组织各自维护自己的Orderer和Peer节点。Orderer节点是用于对事务进行排序的节点。事务主要是对链码的调用记录。事务记录被Orderer节点排序后打包成区块,分发给对应的Channel上链。Kafka是开源的分布式消息队列。所有组织的Orderer节点都在同一个Kafka集群中,以此确保在复杂的网络环境下所有的Orderer节点都能得到一致的事务记录排序、分发相同的区块。Peer节点加入对应的Channel,作为区块链网络的成员维护账本数据,并对外提供服务。
数据的上链和查询通过Channel中的链码进行。在本文的设计中,联盟链中的每一个成员方根据自身的业务需求,选择需要进行上链的数据,编写链码。区块链存储相较于传统的数据库,操作耗时更长。因此,仅选择最关键的农产品溯源数据存储其中,其他溯源无关的业务数据则由对应的应用层来维护。
3.2. 中间层与前端应用
本文所提出的方案中,任何一个参与方都可以在联盟区块链存储的基础上,维护自己的B/S架构的应用服务。gRPC是一种高性能的开源的RPC框架 [15],应用服务通过gRPC来向底层的区块链网络来请求服务。
在本文的样例应用服务中,通过Hyperledger Fabric提供的SDK来向底层的区块链网络发送gRPC请求,调用智能合约,以实现业务逻辑。业务逻辑位于中心位置,和所有的数据源交互,满足实际的业务需求。
系统中的数据有多个来源,并通过不同方式采集和存储。基础数据来源于农产品种植养殖、生产加工、包装、运输、销售和消费的完整生命周期。对于这些溯源相关的基础数据,其一部分是来自生产加工的数据,该部分数据可以通过智能传感器和物联网设备采集,经由udp通信发送到中间应用服务层中。中间应用服务层对数据进行结构化处理之后,通过gRPC请求将该部分数据发送给联盟区块链网络进行上链。而另一部分数据是难以通过物联网设备采集的数据,该类数据由相关企业的员工使用客户端扫描产品二维码,输入产品溯源信息。另外,对于现存于其他系统的信息,例如物流信息,则通过物流联盟提供的统一接口,定期获取,自动上链。
Web服务器对外提供Restful API接口。Restful API是一种通用性强的Web API规范,易于开发人员理解,方便调用。提供给终端用户使用的应用,如小程序、安卓应用、Web网页等,都可以通过Web服务器开放的接口,调用业务逻辑。
4. 方案实现方法
4.1. 区块链集群部署
按照上节给出的系统构架,本文的方案遵循以下步骤部署联盟链网络:
命令1:使用cryptogen工具为每一个Orderer和Peer节点和它们的管理员用户创建必须的证书。
cryptogen generate --config=/path/to/ cryptogen_config --output /path/to/output/dir
这些证书包括各个组织的根证书、节点或管理员的身份证书与私钥等。它们存储在固定结构的文件树里。通过这些证书,系统可以使用tls来加密请求,并对所有的对链操作进行签名。
命令2:使用configtxgen工具为Orderer节点生成初始块文件。
configtxgen -configPath /path/to/config -profile OrdererGenesisProfile -outputBlock /path/to/output/block
初始块是区块链中的一个特殊区块,它作为最开始的区块,没有指向前一个区块的指针。Orderer集群会共同维护相同的区块链,这个区块链中会存储对整个区块链网络的操作记录,包括建立Channel,在Channel上安装与实例化链码等。
命令3:对于每一个Channel,都先使用configtxgen工具,生成用于建立Channel的事务文件。
configtxgen -configPath /path/to/config -profile AllChannelProfile -outputCreateChannelTx /path/to/AllChannel.tx -channelID allchannel
这个文件内结构化地描述了Channel的信息,尤其是包括了Channel所属的区块链网络的成员方的信息。
命令4:对于每一个组织,都使用configtxgen工具生成用于更新Anchor Peer信息的事务文件。
configtxgen -configPath /path/to/config -profile AllChannel -outputAnchorPeersUpdate /path/to/anchors.tx -channelID allchannel -asOrg OrgName
在同一个组织里可能有多个Peer,这些Peer中会有且只有一个Anchor Peer。Anchor Peer接受其他组织的节点发来的网络信息,并广播给自己组织的Peer,以确保不同组织的Peer之间知道互相的位置。
命令5:在部署任何一个Orderer节点之前,为将部署该节点的主机准备Kafka与ZooKeeper环境。
docker-compose -f docker-compose-zk.yml up -d
docker-compose -f docker-compose-kafka.yml up -d
Kafka是一个高吞吐的分布式的消息队列,它的运行依赖ZooKeeper。ZooKeeper是一个分布式协调服务,可以为分布式系统提供一致性服务。
命令6:完成了上述所有的准备工作后,分别使用如下所示的命令,启动所有的Orderer和Peer节点。
orderer start
peer node start
Orderer节点在启动时,会读取初始块文件,并以此开始维护该区块链。
命令7:在所有的Orderer节点和Peer节点启动后,Peer节点消费先前生成的事务文件,以建立Channel和更新Anchor Peer信息。
configtxgen -configPath /path/to/config -profile OrdererGenesisProfile -outputBlock /path/to/output/block
命令8:Channel建立完成之后,则在Channel上安装和实例化链码。
configtxgen -configPath /path/to/config -profile OrdererGenesisProfile -outputBlock /path/to/output/block
实例化的链码是一种智能合约,运行在Docker容器中。链码被用于对所属的Channel的账本进行读写操作。
至此,就完成了整个联盟链网络的部署。对于测试和开发环境,使用Docker作为应用程序引擎,打包所有的应用程序,并编写脚本完成上述步骤,实现一键启动开发环境。对于生产环境,每个Peer、Orderer和其他应用服务都直接运行在单独的主机上,根据各自配置文件中指定的地址来尝试连接其他节点网络。
4.2. 中间层egg.js
egg.js是一个高可定制的Web应用层框架 [16]。在本文的样例应用服务中,egg.js被用于设计一个应用层和区块链网络之间的中间层。其向上提供Web应用服务,向下与区块链网络进行通信,以调用智能合约,修改账本。

Figure 3. Communication between the middle layer and the blockchain network
图3. 中间层与区块链网络的通信
如图3所示,当应用服务需要与账本中的数据进行交互时,该中间层会向区块链网络发送多次gRPC请求进行通信。在第一次通信请求中,请求体的内容包括:待调用的链码所属的Channel、待调用的链码名称及具体的函数名、提供给这次链码调用的参数、临时生成的事务ID。并且,这次请求会使用当前执行操作的用户的私钥进行签名。这次请求仅向区块链网络提交了一个提案。如果这个提案通过,则意味着请求方的身份符合该链码的调用策略,且该链码的模拟调用过程中也没有发生其他错误。
提案通过后,区块链网络会返回一个响应,该响应是相关节点对提案的背书。响应体的内容包括:该提案的模拟运行结果、区块链网络中与该链码相关的节点对该结果的签名。需要注意的是,区块链网络虽然会根据这次提案模拟地调用链码,但并不会因此实际更新账本。
该中间层在拿到这份背书响应后,会以该背书作为请求体,向区块链网络发起第二次gRPC请求。这次请求会发起一次正式的事务。区块链网络的Orderer节点对该事务完成排序后,会返回成功的状态信息。成功的状态信息表明该事务被网络一致排序,即将打入区块并分发给维护该账本的所有节点。从请求回执中拿到状态信息之后,该中间层会认为这次对账本数据的交互已经结束,向上层应用返回响应。上述中间层与区块链网络通信的伪代码如下所示。
代码1:中间层与区块链网络通信
async function invokeChaincode(ca, channelMeta, chaincodeMeta, invokeArgs){
const txId = generateTxId();
const proposalRequest = combineProposalRequest(ca, channelMeta, chaincodeMeta, invokeArgs, txId);
const proposalResponse = await sendTransactionProposal(proposalRequest);
const transactionRequest =generateTransactionRequest(proposalResponse);
const transactionResponse = await sendTransaction(transactionRequest);
return transactionResponse;
}
每当该中间层试图与账本数据进行交互,都必须进行上述流程。然而,如果一个业务逻辑希望与账本数据进行多次交互,很可能会因为频繁进行上述流程而拖长应用服务的响应时间。在为该中间层设计与编写业务逻辑时,应当针对这一点进行优化。
此外,该中间层还负责解决一些横切关注点。例如,在本文的样例应用服务中,在该中间层编写了一些额外的中间件,用于鉴权和记录系统运行状况。
4.3. 链码设计
基于实践经验,本文的方案建议将业务逻辑从区块链网络层分离,降低开发成本。但如上一节所述,当一个业务逻辑需要中间层与账本数据进行频繁交互时,可能会严重地拖长响应时间。对该问题的一个解决方案是将这种多次交互的逻辑移入链码中。
例如,当业务需要批量查询或添加一批数据时,可以将该逻辑从中间层移入链码。如此一来,中间层只需要进行一次链码调用,仅进行一次上一节所述的通信流程,以避开损耗时间的线性增长。该逻辑的伪代码如下所示。
代码2:合并批量请求
function putBulkKeyValue(asset){
kvlist := unmarshal(asset)
for index := 0; index < len(kvlist); index++ {
stub.PutState(kvlist[index].key, kvlist[index].value)
}
}
function getBulkValue(asset){
klist := unmarshal(asset)
kvlist := new KVList()
for index := 0; index < len(kvlist); index++ {
value := stub.GetState(klist[index].key)
kv := combineKeyValue(klist[index].key, value)
kvlist.push(kv)
}
return kvlist
}
5. 区块链苹果溯源系统
基于上文提出的方案,本文以苹果溯源为例实现了一个系统原型。
5.1. 流程分析
图4展示了该原型系统的基本运作流程,下文对该流程进行分析。
在苹果成熟采摘前,以苹果树为单位进行维护。果树的发芽、花开、结果等生长观测信息需要追溯,应当上链;果农对果树所进行施肥、修剪、浇水、除虫、采摘等操作信息需要追溯,也应当上链。
苹果在果树上生长成熟后,即可作为基础单位进入系统维护。苹果的来源信息,即该苹果从具体某棵果树上采摘的信息上链;对该苹果所进行的除梗、包装、打蜡等粗加工操作也上链溯源。
在粗加工完成后,苹果被打入物流包裹中,运输至客户仓储。负责运输的物流公司、物流单号、运输状态等信息上链;此外,运输包中所包含的苹果信息也上链。

Figure 4. Flow chart of apple traceability
图4. 苹果溯源记录流程图
上述过程涉及三种主体:苹果树、苹果、物流包。在逻辑和物理上,每一个苹果树、苹果、物流包都有自己的唯一标识。
本应用使用二维码作为物理标识。在果园中,苹果的产量十分巨大,相对于传统的昂贵的RFID卡,二维码更适应每一个苹果都需要单独标识的情景。
在溯源过程中的任何一环,都可以对某个具体的溯源单位进行查询。如图5所示,如果用户扫描苹果树或物流包的二维码,即可获取目标的溯源记录;如果用户扫描苹果的二维码,除获得苹果自身的溯源记录外,也获取该苹果对应的果树和物流包的溯源记录。
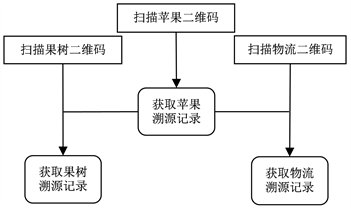
Figure 5. Flow chart of apple traceability
图5. 苹果溯源记录流程图
5.2. 数据模型分析
代码3:溯源主体数据模型
Apple: {
Meta: {
product_id: id of the product,
product_name: name of the product,
description: description of the product,
org: organization the product belong to,
previous: [product id of apple tree, product id of package]
},
Transactions: [
{
tx_id: hashed transaction id,
block_id: hashed block id the transaction belong to,
transaction_time: when transaction committed into the block,
operation_type: type of the operation,
operation_user: who make the operation,
operation_time: when the operation happened,
description: description of the operation,
},
]
}
苹果树、苹果、物流包三种主体的数据都需要保存。如上所示,它们的数据形式类似,可以大致分为两部分:一部分是Meta字段,它描述主体本身的属性,例如品名、所属公司等;另一部分是Transactions字段,它描述主体被进行的操作,包括操作类型,操作描述,操作执行人,操作时间,上链时间等。
此外,苹果树和物流包只需要维护自身的溯源信息,而每个苹果除了自身维护的信息外,溯源时还需要得到所属苹果树和物流包的溯源信息。因此,苹果主体的Meta字段中,有一个额外的previous属性。该属性是该苹果的所有额外信息源的编号。在对苹果进行溯源查询时,递归地查询该列表中的所有编号,将额外信息源的溯源信息与苹果的溯源信息合并。
存在两个可能改变该previous属性的时间点。果树采摘操作时,在所采摘苹果的previous属性中添加该果树的唯一编号;苹果打包成物流包裹时,在这些苹果的previous属性中添加该物流包的唯一编号。
5.3. 实现结果
在本应用系统上为苹果树建立数据时,会为该苹果树生成唯一编号和对应的二维码。果园员工将该二维码贴在果树上,每当对果树进行操作或观察到果树进入新的生长阶段,扫描二维码,进入如图6所示的果树数据录入表单页,将过程和结果录入进去。

Figure 6. Traceability information input interface (partial)
图6. 溯源信息录入界面(部分)
在二维码中,编码了溯源查询网站的链接,并把产品的唯一标识码加密地编码在内。任何用户只要扫描二维码,就可看到对应实体的溯源信息;任何登录系统的操作员,只要通过系统提供的页面扫描二维码,就可进入对应的数据录入页面。对于气温、空气湿度等易于智能监控的生长数据,通过物联网设备进行数据采集,发送给系统自动上链。
当果树上的苹果成熟,扫描果树二维码,可生成对应数量的苹果唯一编号与二维码。
在采摘到的苹果的简易包装上贴上苹果的二维码,每当对该苹果进行加工操作后,扫描二维码,将结果录入进系统内。
当苹果准备打包装箱时,操作员进入系统,生成物流包所对应的唯一编号与二维码。将二维码贴到包裹上,扫描二维码,进入物流包溯源页,扫描每个要被打入包中的苹果的二维码,为这些苹果的previous属性添加该物流包的编号。物流包打包完成后,中间层会定时调用物流公司的物流查询接口,如有物流进度更新,自动将物流数据录入。
消费者收到苹果后,可以扫描其上的二维码,看到如图7所示的从果树到苹果到物流的完整溯源记录。

Figure 7. Traceability query interface (partial)
图7. 溯源查询界面(部分)
5.4. 性能测试与分析
本节进行性能测试。将系统部署在一个具有4核1.5 Ghz CPU、16 GB内存的主机上,在中间层模拟用户行为,持续向区块链网络发送上链事务请求。完成固定上链事务请求数的平均所用时间和单个请求的平均延迟如表1所示。从表1可以看出,该系统在该环境下的吞吐量能够稳定在100 TPS以上,具有承载溯源应用的能力。
在本文的系统中,单个功能可能需要顺序地进行多个请求,响应时间随请求数线性增长。基于3.3节的思路,本文对该系统的业务代码和链码设计进行了优化。优化前后部分功能的区块链事务请求数如表2所示。从表2可以看出,需要多次请求的功能都被降低为仅需1或2次请求,有效提升了大规模数据上链和查询的速度。

Table 1. Statistics on the time taken by the system to complete the fixed request
表1. 系统完成固定上链请求所用时间统计表
Table 2. Comparison of the number of blockchain requests before and after optimization
表2. 系统功能优化前后上链请求数对比
5.5. 安全性分析
本节结合场景特点,从业务层面和数据层面展开分析,从安全角度评估本文所提出的方案的可行性。
业务逻辑集中于中间应用层,中间应用层是传统的Web应用。在传统Web应用中,存在许多常见的安全威胁,如XSS攻击、CSRF攻击、流量劫持、钓鱼攻击等。对于这些威胁,都可以由传统Web应用已有的防范措施进行应对。
溯源数据存储在区块链网络中,这些数据的真实性、完整性和隐私性是溯源可信的基石。对于真实性和完整性,中间层作为传统的Web应用,以RBAC确认用户的操作权限;所有向联盟链网络请求都由发起请求的用户私钥进行签名,并且请求用户和请求内容都符合链码的背书策略,保证了相关信息来源的真实性;在此之外,由Hyperledger Fabric提供的CA和MSP (Membership Service Provider)等机制可以确保链上数据无法被伪造或篡改。对于隐私性,依照不同的保密要求,利用多Channel实现不同种数据的隔离,联盟内的成员只能访问有权访问的数据,保证成员的隐私信息。综上,在数据存储层面,可以认为存在足够的安全保障,使得溯源数据高可信。
6. 结束语
本文设计并实现了一种联盟区块链农产品溯源系统,充分结合农产品溯源的需求特点,有效提升了大规模数据上链和查询的速度,形成多方参与的多层次、多中心农产品安全解决方案。该系统的区块链存储网络基于超级账本,未来将跟随相关技术的发展状况进行维护。下一步拟将该方案进一步在农产品种植基地推广,并结合实际业务需求加以优化。
基金项目
本文受苏州大学“大学生创新创业训练计划” (编号201810285032Z)、国家自然科学基金(61672370)、赛尔网络“下一代互联网技术创新项目”(编号:NGII20190314)资助。
NOTES
*第一作者。
#通讯作者。