1. 引言
随着智能移动设备的迅速普及,基于位置的社交网络(LBSNs, Location-Based Social Networks)数据大量累计,如何利用这些数据成为学术界和工业界共同关注的热点问题。在LBSNs中,用户可以通过在兴趣点(POI, Point-of-Interest)签到来分享他们访问过的地点,例如餐馆、网红景点和商店等。一般的POI推荐任务是向用户推荐新颖有趣且用户感兴趣的POI [1],但是在校园环境下学生用户的行为具有明显的规律性,所以我们给用户推荐POI时不能只推荐学生未访问的新颖有趣的POI,而是从数据集整体中挑选学生可能感兴趣的POI。更应该从数据集整体中挑选学生可能感兴趣的POI进行推荐。其主要目标是通过挖掘学生群体的签到记录和其他可用信息来获得学生在特定时间可能访问的top-N POI。
与传统的无上下文推荐系统不同,POI与用户之间的交互要求用户访问现实世界中真实存在的地点。因此,时空信息(包括地点的经纬度坐标和时间因素等)是影响用户实际签到行为的关键因素。例如,学生通常是在下午或晚上时段去操场散步和体育锻炼,周末通常是在宿舍、图书馆和自习室区域。总之,时空信息对于分析用户行为以获得POI推荐有至关重要的作用。POI推荐在城市规划、商业广告和服务行业中有着重要价值,提出了很多方法来提高POI推荐质量 [2] [3],然而如何根据复杂时空信息准确预测用户在给定时间的POI仍是一个具有挑战性的问题 [4]。
许多研究通过采用传统方法(如,矩阵分解(MF, Matrix Factorization)等)来解决POI推荐问题。MF根据用户POI频率矩阵获得用户和POI潜在因子,该矩阵显示用户的签到次数 [5]。由于一般签到娱乐数据集(如,Foursquare、Yelp等)用户POI签到数据密度较低,基于MF的POI推荐存在数据稀疏性问题 [6] [7] [8]。为了解决此问题并提高POI推荐的准确性,需要在推荐过程中结合其他上下文信息,例如地理、时间和类别信息等 [9] [10] [11]。对用户行为的分析表明,地理信息对于用户偏好的影响要大于其他上下文 [12] [13],因此,提出几种基于地理信息的POI推荐算法研究 [14] [15] [16],然而这些算法仅仅是从用户角度考虑地理信息,例如地理距离是用户位置和POI之间的距离。
在本文中,我们提出一种新的POI推荐算法,该算法从用户和位置两个方面考虑地理信息,其中,将用户的活跃区域视为建议区域;POI被签到次数越多,该POI推荐相关性就越小。将提出的地理信息模型融合到矩阵分解框架中,提高POI推荐的性能。在中原工学院真实的校园学生WiFi签到数据集上进行验证,与其他方法相比,地理模型与矩阵分解算法融合的基于校园地理信息的Logistic矩阵分解(CGLMF, Campus Geographic Information based Logistic Matrix Factorization)算法可以实现更好的POI推荐性能。
2. 相关工作
近年来,POI推荐算法层出不穷,很多算法在工程实践中都有很好的效果。这里主要总结了两类经典的协同过滤算法。它们分别是基于内容的协同过滤和基于模型的协同过滤。基于内容的协同过滤算法在POI推荐中使用用户签到数据来预测用户POI偏好,该算法最重要的问题是签到数据集中可能会存在大量数据元素为空的情形导致数据稀疏 [17] ;基于模型的协同过滤算法有很多,例如矩阵分解 [18],以提高POI推荐的准确性和可扩展性。由于现实中POI个数很多但单个用户访问的POI数量有限,因此基于协同过滤的算法会受到数据稀疏性的制约,其结果通常会导致用户与POI之间没有显着关联的情况下,推荐性能显著下降。因此,许多研究试图通过将附加信息纳入模型来解决协同过滤的数据稀疏性问题 [8] [14]。
由于签到数据集中通常包括一些重要的上下文信息,例如,社会影响力 [19] [20] 、地理位置 [10] [21] [23] 、时间 [10] [22] [23] 、序列 [10] [23] [24] 等,Rahmani等 [22] 提出了一种POI嵌入模型CATAPE,该模型考虑了POI类别的POI特性。CATAPE由签入模块和类别模块两个模块组成,以合并用户的序列行为和位置的属性。
有很多研究已经证明,地理环境是用户在POI之间位置变化的重要因素 [20]。过去很多研究已经探讨了如何在推荐过程中对这类信息进行建模 [12] [18] [23]。Ye等 [8] 表明,当考虑地理信息时,用户访问的POI遵循幂律分布(PD, Power-law Distribution)。此外,他们提出了一种基于存储器的协同过滤(CF, Collaborative Filtering)方法,该方法遭受有关大规模数据的可伸缩性问题的困扰。Cheng等 [14] 证明用户的签到围绕多个中心进行,而这些中心是使用多中心高斯模型(MGM, Multi-center Gaussian Model)捕获的。Li等 [25] 考虑了关于成对排名问题的POI推荐任务,他们使用额外的因子矩阵来利用地理信息。Zhang等 [26] 提出了一种方法,该方法分别考虑了对每个用户的地理影响。为此,基于每个用户签入的POI之间的距离分布的核密度估计(KDE),提出了一种模型。Yuan等 [27] 解决了数据稀疏性问题,假设用户倾向于在地理上更接近他们已经访问过的POI的位置上排名较高。
最近,Aliannejadi等 [13] 提出了一种用于POI推荐的两阶段协作排名算法。考虑到同一社区中POI的地理影响,他们将具有单个或多个签到的POI推入推荐列表的顶部。他们表明,在学习中访问过和未访问过的POI都可以缓解稀疏性问题。Guo等 [15] 提出了一种位置邻域感知加权矩阵分解(L-WMF, Location neighborhood-aware Weighted Matrix Factorization)模型,该模型结合了POI之间的地理关系以从位置角度利用地理特征。
以前的方法主要从用户的角度探讨地理信息。与其他POI推荐模型相比,本文提出的方法是基于将用户和位置的观点组合成一个更好的地理信息模型。为此,在建议的模型中使用了用户和POI之间的距离(从用户的角度来看)和相邻POI上的签到频率(从位置的角度来看)。此外,我们在模型的推荐策略中考虑了POI邻居的影响,以解决数据稀疏问题。
3. 数据集
本节主要探讨XXXX大学的学生签到WiFi日志数据集的各项特征,并利用图表的形式来展示数据集的各项特征。
3.1. 数据集
实验研究中主要使用三个数据集:(1) XXXX大学XX校区2018年3月全体在校学生7863人的WiFi签到日志数据;(2) 校区内建筑位置信息和楼层信息;(3) 城市热点数据集(收集与分析匿名)。学生WiFi签到日志数据如表1所示。

Table 1. 20180301_20180331 Data Set
表1. 20180301_20180331数据集
城市热点数据集提供学生MAC地址与学号对应数据集,能够进行有效的学生学号匿名表示。建筑物数据集提供建筑物信息,通常有建筑物序号、名字、类别、坐标、功能。WiFi签到日志数据集通常包含学号(匿名)、MAC、坐标、时间等信息。WiFi签到日志数据集中POI-POI矩阵的密度是67.31%远大于一般娱乐签到数据集(如,Foursquare、Yelp等)。在处理WiFi签到日志信息之前首先对日志数据进行清洗,把全部签到信息少于100条的学生删除,并依据坐标获得建筑物序号和楼层信息,并将重复数据和无效数据删除。最后使用的数据有2300多万条目,更多的数据统计信息展示在表1中,接下来就根据学生的MAC (匿名)、建筑物和校园地理信息通过第4小节的CGLMF算法生成学生的top-N推荐列表。
3.2. 时间因素
时间是POI推荐中的重要因素,学生群体生活的规律性由此体现。WiFi签到日志中包含学生在日常生活和学习中的WiFi签到数据,通过对比不同区域学生的签到时间,可以观察到不同活动区域显示出的独特时间模式,如图1和图2所示。例如,学生在早上8点和中午12点去食堂吃饭的人数占比为46%和38%,晚餐通常持续时间较长,一般是在5点开始并一直持续到8点左右,显示出校园学生的活动模式区别很大。学生宿舍的签到活动持续时间为24小时,凸显出大部分学生的校园活动中心是宿舍,虽然宿舍在晚上签到的比例较高但是频次在下降,显示学生的日常作息还是比较规范,宿舍持续签到活动凸显宿舍的多功能性和重要性。
通过图1和图2观察,可以发现,教学区域(教学楼、院系楼、图书馆等)在上课时间段签到频次以及签到比例都比较大,然而图书馆签到频次和时长明显多于教学楼和院系楼,表明学生更喜欢在图书馆自习而不是在自习室自习。餐厅就餐时间和签到频次变化表明学生就餐时间段变化和午餐持续时间明显比晚餐持续时间短,学生选择在校园吃午餐的人数比在校园吃晚餐的人数更多。学生在其他区域的时间人数变化表明学生的课外活动时间更多集中在下午5点以后,上午时间在教学区域签到频次和比例明显较大。通过观察学生日常行为作息,本文一方面可以为学生日常生活和学习提供指引,另一方面,可为高校管理提供科学规划和决策支持,优化校内设施和资源利用。
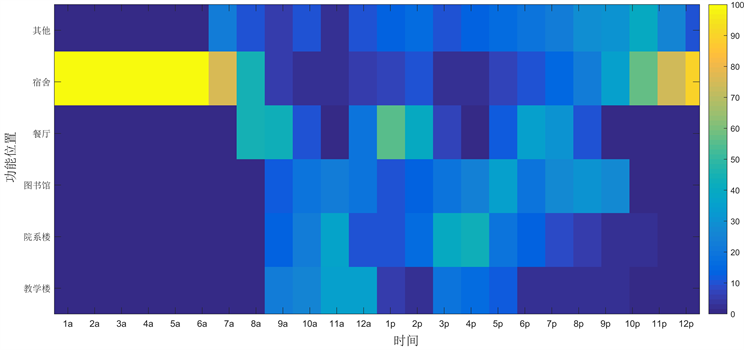
Figure 1. Proportion map of the number of people in hotspots
图1. 热点区域人数比例分布图

Figure 2. Frequent map of the number of people in hotspots
图2. 热点区域人数频次分布图
4. CGLMF
本节介绍我们提出的兴趣点POI推荐方法,称为基于校园地理信息的Logistic矩阵分解(CGLMF, Campus Geographic Information based Logistic Matrix Factorization)。CGLMF包含两个主要步骤。第一步,根据用户和位置的观点,提出一个校园地理模型(CGM, Campus Geographical Model)。然后,在第二步中,将CGM融合到Logistic矩阵分解(LMF, Logistic Matrix Factorization)方法中,使用CGLMF模型预测学生对于POI的个人偏好。
4.1. CGM
学对于校园地理信息建模,我们首先可以根据Tolbers的“第一地理定律” [28] 聚集现象,使用地理信息和聚类算法将历史签到数据形成高活动位置(HAL, High Activity Position)。其次,随机地从签到地点选择K地点作为模型输入,这K地点可能是在HAL范围内,同时也包含未访问的兴趣点POI。再次,根据效用理论设计一个优化函数来刻画这个K地点的关系。通过优化函数,模型可以学习到用户和兴趣点的潜在特征。最后,将效用与位置分数结合,对用户兴趣点POI推荐预测,即可获得top-N推荐列表。
校园地理模型(CGM, Campus Geographical Model),假设
是学生集合,而
是LBSNs中的POI集合。然后,令
是具有m位学生和n个POI的用户-POI签入频率矩阵。
表示学生i到POIj的签到频率,给定学生u和学生u先前兴趣点POI集
,目标是获得学生u的兴趣点POI推荐列表top-N。
CGM涵盖从学生和位置两个角度来考虑地理信息。以学生角度,可以通过考虑学生的活动区域来对地理信息进行建模。从位置角度来看,可以将地理信息建模为所选POI邻居的登记频率,从而可以表明一个位置相对于其邻居节点满意度较高。算法伪代码如下。
Algorithm 1. Campus Geographical Model
算法1. 校园地理模型(CGM, Campus Geographical Model)
该算法由四个内部循环组成,以对校园地理信息进行建模,前三个循环对学生区域进行建模,第四个循环计算学生访问区域内POI的概率,并考虑对其相邻POI访问的可能性。为了对学生区域进行建模,我们需要找到每个学生的活动频繁位置,在校园中,这可能是教学楼、宿舍或食堂等区域,我们会获得多个高活动位置点,在不同区域使用不同的学生最常签到的POI,然后,我们扫描未签到的POI列表,以找到与该学生最高活动位置点位于同一区域的POI,这些POI位于距学生活动频繁的位置
米(学生角度)。此外,根据每个学生区域内POI,我们考虑到相邻POI的影响,该位置距未签到兴趣点POI的距离小于
米(位置角度)。POI位置定义如下:
(1)
式中,
是学生u访问
的邻居数,
表示学生u已经访问POI的基数。
4.2. CGLMF模型架构
传统推荐系统(TRS, Traditional Recommender Systems)主要依赖显式反馈数据作为输入,然而在LBSNs中通常不存在明确的显式反馈数据。因此,签到数据可以被视为针对TRS的隐式反馈数据,从而形成了不同的推荐问题 [17]。
C.C. Johnson [5] 首先提出了Logistic矩阵分解(LMF)模型,利用Spotify音乐数据集的隐式反馈数据集取得了显著成果。LMF使用概率的方法,通过逻辑函数对用户对某项商品的偏好进行建模,但是LMF在建模推荐过程中无法考虑到上下文信息。
我们通过将CGM作为上下文信息融合到Logistic矩阵分解,提出了一种基于LMF的新型矩阵分解方法。一般情况下,通过矩阵分解的推荐模型的目的是找到两个低阶矩阵,分别是用户-因子矩阵
和项目-因子矩阵
,其中k是潜在因子的数量。
假设
表示用户u在POIp上签入的次数,参数V和L分别表示用户和POI的两个潜在因素,
和
为用户偏差和POI偏差。概率
表示用户u在POIp上的偏好,定义如下:
(2)
式中,
表示学生u在兴趣点POIi处有签到活动。
参数V和L的优化可通过如下式子:
(3)
其中
定义如下:
(4)
最后,我们将CGM融合到LMF方法中。因此,可以如下计算用户u访问POIp的概率:
(5)
式中
由式(2)计算,
由算法1计算得出。通过概率函数,可以为每个用户u提供POI推荐列表top-N。不同于传统LMF方法,CGLMF模型通过融合CGM将地理上下文信息纳入POI推荐过程。
5. 实验
实验所用数据集为中原工学院2018年3月的全体学生WiFi签到日志数据,其中学生数7863,兴趣点POI数202,签到条目2300余万条。我们将数据划分为二个数据子集,其中80%数据作为训练集,剩余20%作为测试集。
5.1. 评测指标
POI推荐算法评价指标很多,为使得实验效果评价易于理解和解释,选用top-N推荐最常用的两个指标:准确率(Precision)和召回率(Recall)。准确率指推荐结果中用户将来实际要去的地点占推荐结果的比例,反映推荐结果的准确性;召回率指推荐结果中占用户将来真正去到的兴趣点总量的比例,反映推荐结果的全面性。公式如下:
(6)
(7)
式中,R(u)是针对用户u推荐的兴趣点集合;T(u)是用户u在测试集的实际签到集合。
5.2. 实验对比
将CGLMF模型与考虑推荐过程中地理影响的其他POI推荐方法进行比较。比较方法的详细信息如下:
· LMF [5] :一种结合逻辑函数的Logistic矩阵分解方法。
· LRT [29] :一种模型,该模型将时间信息合并到潜在排名模型中,并了解用户对每个时隙位置的偏好。
· CGLMF:我们提出的将LMF与提议的校园地理模型CGM融合的方法。
5.3. 实验结果
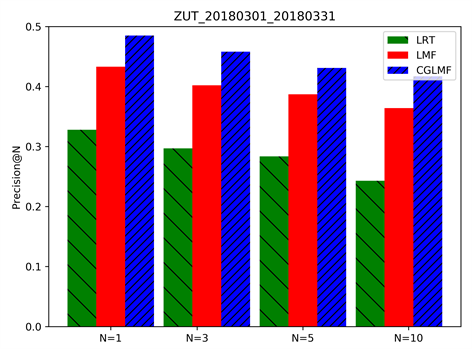
为验证CGLMF算法的推荐效果,本实验将CGLMF算法与LMF、LRT进行比较和分析。推荐结果的准确率和召回率如图3所示。
由图3可以看出,不论N取何值时,本文的CGLMF算法在推荐准确率和召回率上明显优于对比算法LRT、LMF。CGLMF算法有效利用校园地理信息的高可用性,提高了POI推荐的综合质量,对于智慧校园建设可以起到一定促进作用。
 (a)
(a)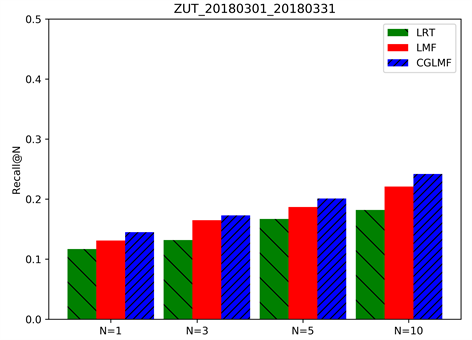 (b)
(b)
Figure 3. Recommended performance for each algorithm TOP-N. (a) Precision of school dataset recommendation results; (b) Recall of school dataset recommendation results
图3. 各算法top-N (N = 1, N = 3, N = 5, N = 10)推荐性能。(a) 学校数据集推荐结果的准确率;(b) 学校数据集推荐结果的召回率
5.4. 参数调整
对于LMF我们将潜在因子参数设置为k = 30。对于LRT,我们将T设置为时间状态为24,将
和
作为正则化参数设置为2.0。我们根据验证数据调整CGLMF参数。我们使用训练数据找到参数的最佳值,并在测试数据中使用它们。
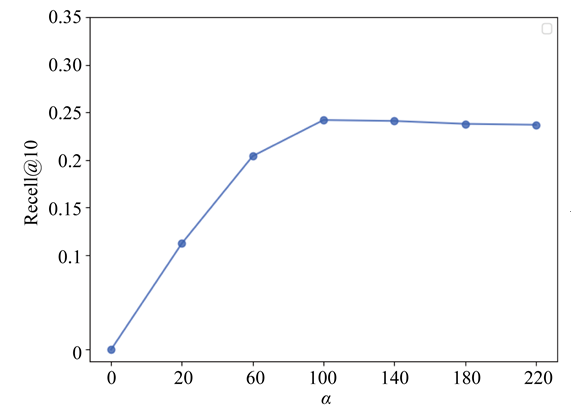
图4显示了基于
和
的不同值对于CGLMF性能的影响。在图4(a)中,我们固定其他值后基于Recall @ 10指标可以明显看到不同的
值对CGLMF性能的影响,从图中我们可以清晰看到
的最佳值为100。在图4(b)中固定其余值后,不同的
值对CGLMF模型性能的影响,可以看出,数据集的最佳
值为13。上述结果表明,学生用户倾向于访问POI附近的位置兴趣点,并且可以从他们从活动频繁的位置中划出一个区域。
 (a)
(a)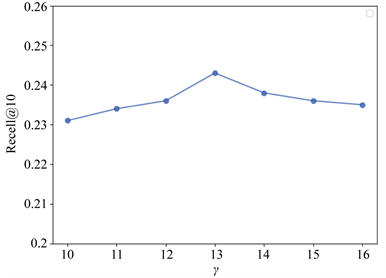 (b)
(b)
Figure 4. Effects of different parameters on the CGLMF algorithm. (a) Effect of α; (b) Effect of γ
图4. 不同参数对CGLMF算法的影响。(a) α的影响因子;(b) γ的影响因子
6. 结束语
在本文中,我们针对校园地理信息的高可用性提出一种新颖的CGLMF模型,充分考虑学生和校园位置信息等地理信息。我们通过Logistic矩阵分解合并了用户的偏好,并提出一种融合矩阵分解方法,以包含我们CMF所捕获的地理信息。在校园真实数据集上的实验结果表明,与其他对比实验相比,该方法利用了地理信息中更多的条件,从而优于其他方法。未来的研究方向可以从两个方面进行拓展:一是将更多不同校园学生信息如网络访问、一卡通消费、图书借阅等综合利用起来提高兴趣点POI推荐性能;二是考虑如何给学生推荐朋友或活动,拓展成为一个完善的智慧校园下的应用软件。
基金项目
国家自然科学基金项目(61702503);河南省科技攻关项目(172102210591);河南省教育厅重点科研项目(19A520048);河南省教育厅青年骨干教师项目(2017GGJS118)。
NOTES
*通讯作者。