1. 引言
《中国心血管疾病报告2018》 [1] 指出:中国心血管疾病死亡率占城乡居民总死亡率之首,其高达45%如图1(a)所示,图1(b)显示2002~2016年中国城乡居民心血管疾病死亡率仍处于上升趋势,因此防治心血管疾病刻不容缓。随着电子计算机信息处理技术的迅猛发展,利用电子信息处理技术对心电(ECG)信号进行处理来诊断心脏病,由于其不但可以避免传统诊断中对医生的主观依赖性,并且可以提高诊断的精度经验,因此其成为一种强有力的分析手段而取得了广泛的研究。
 (a) (b)
(a) (b)
Figure 1. (a) The main cause of death in China; (b) Changes of Cardiovascular Mortality rate in China from 2002 to 2016
图1. (a) 中国人口主要疾病死因构成;(b) 2002~2016年中国城乡居民心血管病死亡率变化
如图2所示的心电信号,其波形主要有由P波、Q波、R波、S波、T波及U波组成,而各波都具有不同的频率特性,以及不同的时间间隔:PR间期、QRS间期、RR间期等。其波形的高度、时间宽度反映心房和心室的电位变换,而QRS波群、P波、T波为其最主要的特征波。因此正确检测出QRS波,再将心电数据划分为各个心拍作为心电特征数据进行分类识别取得诊断信息。
关于ECG信号分类识别,其算法包括:小波变换,多层感知器(MLP),极限学习机(ELM) [2] ,径向基函数神经网络 [3] ,支持向量机(SVM) [4] 和基于深度特征学习的方法 [5] ,但存在运算复杂度高、检测结果不准确、检测范围小且不能完全自动诊断和监测等缺陷,并且对目前数据分析还必须依赖于以前的数据样本,针对以上缺点,增量高斯混合模型(Incremental Gaussian Mixture Model,简称IGMM)是一种广泛应用于数据挖掘、统计分析和机器学习等领域的非监督式算法,其方法是使用一种近似于期望最大(Expectation Maximization,简称EM)的算法进行训练,其变量分布可分解为若干个高斯分布的统计模型。IGMM的增量特征体现在其高斯成分可跟随新引入的数据点而不断获得更新,这意味着IGMM能够挖掘出与数据点相匹配的数据模型。因此,IGMM已经成功地应用在时间序列预测、强化学习、移动机器人控制与映射以及数据流中的离群点检测等领域。然而,IGMM在协方差矩阵求逆和行列式计算时存在立方阶时间复杂度的问题,这使得该算法不利于高维分析,进而限制了其应用范围。鉴于此,本文提出一种快速增量高斯混合模型算法,以实现心电分类研究,其可以不断调整输入和输出空间高斯混合模型,无需存储任何过去数据点实现心电自动检测分类。本文结构安排:1) 介绍心电信号的基本构成;2) 心电信号处理;3) 实验结果与分析。
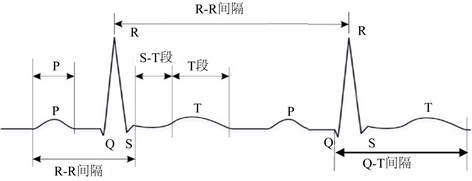
Figure 2. The basic constitution of ECG signal
图2. 心电信号的基本构成
2. 方法
实现基于增量高斯混合模型的心电信号分类主要分为如下四部分如图3所示。

Figure 3. ECG signal processing flow diagram
图3. 心电信号处理流图
2.1. 基于小波变换预处理
小波变换作为一种数学工具,可用于从许多不同类型数据中提取信息,由于其时频域局部化优良特性而被广泛用于信号和图像处理。在研究中由于Daubechies (Db)小波具有正交性、指数多项式消失距和连续紧支性等特性,因此采用该小波作为母小波进行小波变换。鉴于心电信号基线频率为0.15~0.3 Hz,特选用Db8小波对心电信号预处理。
2.2. 心电信号特征波形检测提取
QRS复合波段选择并找到QRS窗口通过阈值处理:
1) 从DWT分解细节系数和去噪阵列ECG_DENO的映射中找出QRS区域。
2) 对有高噪声含量信号,添加分量D4和D5形成阵列QRS_DET。
3) 从QRS_DET找出QRS波群:设定确定的阈值 [6] ,令该阈值等于QRS_DET阵列平均振幅值的15%。
准确检测R (Q或S)峰值(效果如图4所示):
1) 在QRS_DET阵列中标记超过阈值水平的指标,QRS复合波区域从绝对QRS_DET值变为大于阈值的第一点开始。由于患者QRS复合波最大宽度不超过160 ms,因此在QRS_DET中搜索相同宽度的固定窗口以检测满足阈值条件。在两次连续搜索之间,提供200 ms消隐期。
2) R (Q或S)峰值是QRS窗口内最大(最小)幅度值,通过去噪信号ECG_DENO设置。将QRS起始索引中的每一个都映射到ECG_DENO,搜索每个QRS_START:QRS_START + 160 ms窗口内局部最大(最小)值来获得实际R (Q或S)峰值。
3) 再次从ECG_DENO检查每个R索引幅度,如果是阳性(阴性),则识别R峰(细长或病理性Q或S) Q和S点具有QRS起始和偏移检测:一旦准确地检测到R峰值,就在阶段E中检测Q和S点以找到完整的QRS复合波。
4) 检测Q (和S)点位置,在R_INDX:R_INDX-80的窗口内从R峰向左(右)开始搜索,以检查斜率符号反转。对于ECG_DENO上每点,通过三点微分计算斜率,其中h是时分,如公式(1)
 (1)
(1)
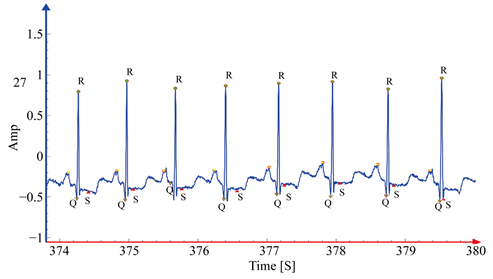
Figure 4. R (Q or S) peak location diagram
图4. R (Q或S)峰定位图
2.3. 增量高斯混合模型算法
根据给定的D维样本集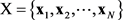 ,IGMM [7] 算法处理步骤如下:首先,计算每个分量k的马氏距离平方
,IGMM [7] 算法处理步骤如下:首先,计算每个分量k的马氏距离平方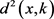 如公式(2)
如公式(2)
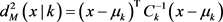 (2)
(2)
其中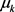 是第k个成分均值,
是第k个成分均值,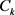 是其完全协方差矩阵。
是其完全协方差矩阵。
如果有任意 小于
小于 (具有D自由度的卡方分布
(具有D自由度的卡方分布 百分位数)就会发生更新,其中D是输入维数,
百分位数)就会发生更新,其中D是输入维数, 是用户定义的元参数,每个组件后验概率如下:
是用户定义的元参数,每个组件后验概率如下:
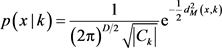 (3)
(3)
 (4)
(4)
其中M是成分的个数。
此时,算法参数按照以下方程进行更新:
 (5)
(5)
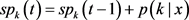 (6)
(6)
 (7)
(7)
 (8)
(8)
 (9)
(9)
 (10)
(10)
 (11)
(11)
 (12)
(12)
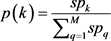 (13)
(13)
其中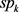 和
和 分别为累加器和k成分寿命,
分别为累加器和k成分寿命, 为其先验概率。
为其先验概率。
2.3.1. 通过顺序同化数据点进行模型更新
与新颖性标准不匹配的瞬时数据点需要通过当前混合分布来同化,由于其所承载的信息而导致其参数值的更新。IGMM遵循用于通常迭代过程的增量版本,以基于两个步骤估计混合模型的参数:估计步骤(E)和最大化步骤(M),因此迭代过程的增量转换用于估计混合模型的参数。更新过程开始计算数据点的组件隶属度的后验概率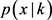 估计步骤。使用当前分量条件密度
估计步骤。使用当前分量条件密度 和先验概率
和先验概率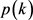 如公式(14)
如公式(14)
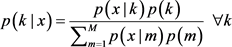 (14)
(14)
然后使用后验概率来计算每个分量密度 的平均矢量
的平均矢量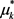 和协方差矩阵
和协方差矩阵 的新估计值,并且在最大化步骤中计算优势
的新估计值,并且在最大化步骤中计算优势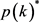 。接下来,我们通过IGMM使用其他方法来连续估计这些参数。参数
。接下来,我们通过IGMM使用其他方法来连续估计这些参数。参数 ,对应于平均值
,对应于平均值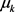 ,协方差矩阵
,协方差矩阵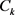 和先验
和先验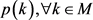 ,涉及D维高斯分布
,涉及D维高斯分布 混合模型。可以从t数据向量的序列估计,假设
混合模型。可以从t数据向量的序列估计,假设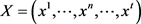 独立于该混合分布绘制。在最大化步骤中,基于数据可能性的最大化来更新当前模型参数 [8] 。在这种情况下,给定Χ,
独立于该混合分布绘制。在最大化步骤中,基于数据可能性的最大化来更新当前模型参数 [8] 。在这种情况下,给定Χ,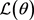 中
中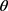 的似然性是整个数据流Χ的联合概率密度,其中最大似然技术 [9] 通过最大化
的似然性是整个数据流Χ的联合概率密度,其中最大似然技术 [9] 通过最大化 来设定
来设定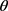 值,如公式(15)
值,如公式(15)
 (15)
(15)
通过样本均值向量和样本协方差矩阵估计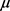 和C,并且X是正态分布的随机向量时,联合密度函数
和C,并且X是正态分布的随机向量时,联合密度函数 已知是可重复的Gauss-Wishart分布,是自然共轭密度。在这种情况下,当我们估计单个分布的预期向量和协方差矩阵时,从具有预期向量
已知是可重复的Gauss-Wishart分布,是自然共轭密度。在这种情况下,当我们估计单个分布的预期向量和协方差矩阵时,从具有预期向量 和协方差矩阵
和协方差矩阵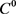 的先验分布开始,这些参数通过n个观测值进行变换,该函数的表达式如公式(16)
的先验分布开始,这些参数通过n个观测值进行变换,该函数的表达式如公式(16)
 (16)
(16)
其中 和
和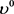 分别反映了
分别反映了 和
和 的初始估计值,用于计算这些初始估计值的样本数。
的初始估计值,用于计算这些初始估计值的样本数。
另一方面,当输入数据的概率密度是具有M个分量的高斯混合模型时,通过相应后验概率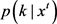 将其随机地分配给分布k。此时,用于计算第k个分配组件的参数的等效数量的样本对应于此时数据后验概率的总和,IGMM将该求和存储为变量
将其随机地分配给分布k。此时,用于计算第k个分配组件的参数的等效数量的样本对应于此时数据后验概率的总和,IGMM将该求和存储为变量 ,并周期性地重新启动避免最终饱和。IGMM用于更新模型分布的递归方程如公式(17)
,并周期性地重新启动避免最终饱和。IGMM用于更新模型分布的递归方程如公式(17)
 (17)
(17)
其中 指的是在时间
指的是在时间 (即在更新之前)
(即在更新之前)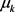 的值。
的值。
IGMM算法只有两个配置参数, 和
和 。参数
。参数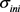 并不重要,它对
并不重要,它对 的唯一要求是足够大以避免奇点。在实验中,我们使用公式(18)
的唯一要求是足够大以避免奇点。在实验中,我们使用公式(18)
 (18)
(18)
其次,对参数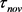 要求更加严格,它表明x与
要求更加严格,它表明x与 必须有一定距离才能被认为是k的成员。例如,
必须有一定距离才能被认为是k的成员。例如, 表示
表示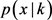 必须低于高斯高度的1% (高斯中心的概率),x被认为是k的非成员。如果
必须低于高斯高度的1% (高斯中心的概率),x被认为是k的非成员。如果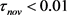 ,将创建很少的模式单位,并且回归将是粗略的。如果
,将创建很少的模式单位,并且回归将是粗略的。如果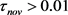 ,将创建更多模式单位,因此回归将更精确。在限制中,如果
,将创建更多模式单位,因此回归将更精确。在限制中,如果 个单位,则每个训练模式都将被创建。
个单位,则每个训练模式都将被创建。
2.3.2. 基于新颖性和稳定性标准创建新组件
为创建一个新组件,IGMM使用公式(4)给出的新颖性标准,但也使用稳定性标准来测试是否已经有一个最近创建组件应该同化当前呈现的数据点。为此,我们存储每个模型组件k的时间, ,包括自创建组件以来已经呈现给学习系统的数据数量。仅当没有时间小于特定阈值
,包括自创建组件以来已经呈现给学习系统的数据数量。仅当没有时间小于特定阈值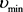 的模型组件时才会创建新组件,即稳定性标准可由以下定义:如果数据变化太快,则这些数据点被当前模型同化为噪声,并且不会创建新组件。事实上,稳定性标准避免了在嘈杂环境中连续创建组件,但它无法避免产生最终的虚假组件。但如果
的模型组件时才会创建新组件,即稳定性标准可由以下定义:如果数据变化太快,则这些数据点被当前模型同化为噪声,并且不会创建新组件。事实上,稳定性标准避免了在嘈杂环境中连续创建组件,但它无法避免产生最终的虚假组件。但如果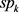 仍然非常小,可以很容易地识别出伪分量,在参数
仍然非常小,可以很容易地识别出伪分量,在参数 给出后,在创建后的一些时间步之后,指定参数
给出后,在创建后的一些时间步之后,指定参数 。
。 的一个很好的选择是
的一个很好的选择是 ,因为根据Tråvén提出的算法,需要至少多于D个样本才能获得对于受限制的协方差矩。基于相同原则可以设置为任意值的指标,而不是指数。识别后,可以从当前模型中删除杂散组件。调整
,因为根据Tråvén提出的算法,需要至少多于D个样本才能获得对于受限制的协方差矩。基于相同原则可以设置为任意值的指标,而不是指数。识别后,可以从当前模型中删除杂散组件。调整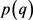 对于所有的
对于所有的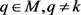 ,用公式(19)
,用公式(19)
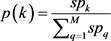 (19)
(19)
每当数据点 与公式(4)给出的新颖性标准匹配,并且稳定性标准被填充时,创建新的分量k以该数据向量为中心并且与基线协方差矩阵i一致。最后,我们必须调整所有
与公式(4)给出的新颖性标准匹配,并且稳定性标准被填充时,创建新的分量k以该数据向量为中心并且与基线协方差矩阵i一致。最后,我们必须调整所有 以满足约束公式(20)和公式(21)
以满足约束公式(20)和公式(21)
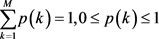 (20)
(20)
 (21)
(21)
由于 即
即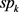 初始化为1,因此该新组件的先验等同于公式(22)
初始化为1,因此该新组件的先验等同于公式(22)
 (22)
(22)
在Arandjelovic和Cipolla中得出的结论是:若所有可用的信息都是当前的GMM估计值,那么单个新颖点就不会携带足够信息导致高斯分量增加。但我们对此有不同看法,因为在IGMM中我们允许增加组件数量,若使用稳定性标准,我们删除虚假字母这比保持历史GMM内存或使用拆分或合并操作来改变GMM复杂性更好。IGMM更新模型算法流程如图5所示。
3. 实验结果与分析
3.1. 数据
美国医疗仪器促进协会(AAMI)把心拍分为五类 [10] :正常或者束支传导阻滞节拍(N)、室上性心率异常节拍(S)、室性心率异常节拍(V)、融合节拍(F)、未确定的节拍(Q)。AAMI还规定了心律失常分类检测算法的评估标准,以及准确率(Acc)、灵敏度(Sen)、特异性(Spec)真阳性率(Ppr)等作为衡量分类器分类性能的参数。使用AAMI标准有利于各种算法的横向比较,并且对今后研究的规范化进程有很大辅助作用。下面我们将介绍如何将MIT-BIH心拍类别转换成AAMI心拍类别,如表1所示。
3.2. 性能指标
本文采用MIT-BIH心率数据库对研究算法进行检测,由于数据量过大,我们从数据库中随机抽取10000列样本数据进行分类,MIT-BIH中心拍类型及数目如表2所示。
识别和分类中的性能通常通过以下四个性能指标来评估 [11] :分类准确率(Acc)、灵敏度(Sen)、特异性(Spec)和阳性预测值(Ppv)。对于计算中所要用到的运算符号及意义详见表3所示。
(1) 分类准确度表示分类的准确性,它衡量的是真阳性事件和真阴性事件,正确分类的心电数据越多,数值越高,表示该方法性能越好,计算公式如(25)
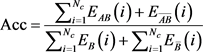 (25)
(25)
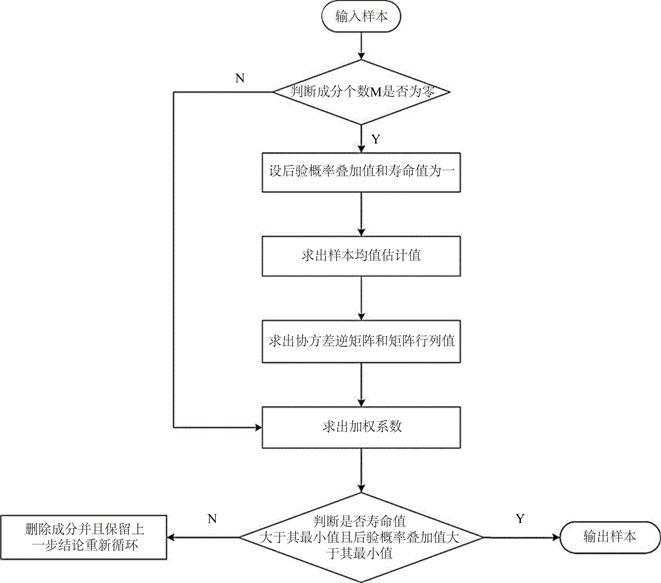
Figure 5. Algorithm flow diagram of IGMM update model
图5. IGMM更新模型算法流程

Table 1. MIT-BIH heart beat category converted to AAMI
表1. MIT-BIH心拍类别转换成AAMI心拍类别
Table 2. Check the type and number of heart beats
表2. 检测心拍类型及数目
(2) 灵敏度表示第i类的真阳性事件发生概率,体现判断病变心电数据的能力大小,计算公式如(26)
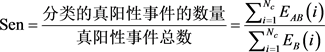 (26)
(26)
(3) 特异性是衡量i类真阴性事件发生率指标,表示该方法对正常心电数据判断能力,计算公式如(27)
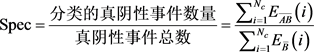 (27)
(27)
(4) 阳性预测值是i类中所有分类事件中真阳性事件的比率,计算公式如(28)
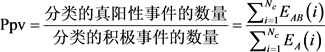 (28)
(28)
Table 3. Operation symbol and meaning
表3. 运算符号及意义
3.3. 结果分析
我们对从MIT-BIH数据库中随机抽取的10000个样本数据进行分类,得到了检测结果,检测数据样本如表5所示。观察表(4)我们会发现:N型确诊:2112列,误诊:604列,确诊率p1 = 77.7614%;S型确诊:1210列,误诊:371列,确诊率p1 = 76.5338%;V型确诊:1236列,误诊:423列,确诊率p1 = 74.5027%;F型确诊:1675列,误诊:45列,确诊率p1 = 97.3837%;Q型确诊:2095列,误诊:229列,确诊率p1 = 90.1463%。采用增量高斯混合模型对5种不同心电图信号的10,000个心跳进行分类,正确检测出8102个心跳,其中有1898个心跳被误检,平均灵敏度达82.844%,特异性达95.76%,分类准确度达93.312%。
4. 结论
本研究基于无监督式增量高斯混合模型算法实现了心电信号分类,用MIT-BIH数据库对5种不同心电信号的10,000个心跳进行分类检测,正确检测出8102个心跳,平均灵敏度达82.844%,特异性达95.76%,分类准确度达93.312%,验证了该算法的可行性。并且此分类算法无需特殊初始化,实现数据流方式对以前的分类结果进行修正而不需要以前大量的数据,这样既可实现便于分类器存储又可节省大量的计算成本提高运算速度,并且具有好的处理稳定性。今后要扩大其应用范围如中药材识别、搜索引擎查询分类、非人恶意流量识别、商业、生物、保险行业和电子商务领域等等,能够使得增量高斯混合模型计算更为准确提高定位准确率是我们今后的方向。