1. 引言
大数据分析的方法是近年来非常热门的一种技术手段。在很多领域都使用了大数据的分析方法进行研究。有很多很多这方面的例子。比如每年的双十一购物节,各大电商会通过大数据分析来研究消费者的购物习惯,以此指导物流、仓储和配送等各类服务。比如电信运营商通过研究用户手机的GPS定位信息,就可以知道任何时间段城市的交通状况,进而指导智慧城市的建设 [1]。
冰的溶解热的测定是大学物理教学的基本实验内容。目前已经有了一些相关的研究,对实验进行了优化 [2] [3] [4]。前人在之前的研究中,使用大数据分析的方法,尝试对冰的溶解热的测定实验进行研究 [5]。长期以来,冰的溶解热测定实验的一些参数没有人为的限制 [6],导致不同的人,测量的结果偏差很大。前人的大数据研究发现了长久以来实验中未曾被人发现的关键信息。
在之前的研究中,通过对西安石油大学物理实验中心资料室的历年的几万份实验报告进行了大数据分析,发现那些百分比误差较小的测量有一个共同的特点,那就是其热水和冰块的质量比值为5.23附近。
由此,它引出了几个问题:热水和冰块的质量比值真的是只有在5.23附近才会得到误差小的结果吗?这会不会是幸存者偏差导致的结果?为什么会是5.23这个比值?5.23这个比值的后面隐藏着什么秘密呢?
经过不断地从各个角度的尝试,现在有一种怀疑,认为:5.23这个比值是冰的溶解热测定实验的关键常数;甚至这个5.23有可能是热学领域的基本常数。
因为在之前的研究中采集的大数据是十几年来西安石油大学几万名学生实验过程的无意识状态生成的,这些数据有可能是有瑕疵的,也有可能是有偏见的。这就会导致是否真的存在5.23这个关键常数本身都是存疑的。
针对于此,本文通过严格限定实验参数、大数据量的重复测量的手段,对这个基本常数5.23做实证研究,意图证实是不是只有在热水与冰块质量比值为5.23附近时,测量误差才很小,同时,希望这次实证研究形成的大数据能对大数据的研究方法形成有益的反馈。
2. 实证研究质量比值与误差的关系
5.23这个关键常数的来源,是来自于前人进行的大数据挖掘的结果。本文的研究过程采取如下的方式:有7个独立的测试人员a、b、c、d、e、f和g,每人独立的进行实验测试,每人都对热水与冰块比值为3:1、4:1、5:1、5.23:1、6:1、7:1和8:1的情况进行10次重复测量。

Figure 1. Relationship between hot water to ice mass ratio and percentage error (tester a’s measurement result)
图1. 热水与冰块质量比值和百分比误差之间的关系(测试员a的测量结果)

Figure 2. Relationship between hot water to ice mass ratio and percentage error (tester b’s measurement result)
图2. 热水与冰块质量比值和百分比误差之间的关系(测试员b的测量结果)

Figure 3. Relationship between hot water to ice mass ratio and percentage error (tester c’s measurement result)
图3. 热水与冰块质量比值和百分比误差之间的关系(测试员c的测量结果)

Figure 4. Relationship between hot water to ice mass ratio and percentage error (tester d’s measurement result)
图4. 热水与冰块质量比值和百分比误差之间的关系(测试员d的测量结果)

Figure 5. Relationship between hot water to ice mass ratio and percentage error (tester e’s measurement result)
图5. 热水与冰块质量比值和百分比误差之间的关系(测试员e的测量结果)

Figure 6. Relationship between hot water to ice mass ratio and percentage error (tester f’s measurement result)
图6. 热水与冰块质量比值和百分比误差之间的关系(测试员f的测量结果)
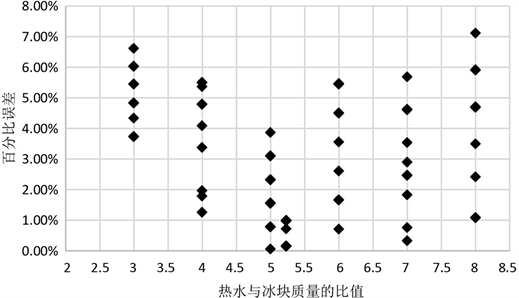
Figure 7. Relationship between hot water to ice mass ratio and percentage error (tester g’s measurement result)
图7. 热水与冰块质量比值和百分比误差之间的关系(测试员g的测量结果)
图1~7分别是7个独立的测试人员a~g进行测量的结果。图1~7的每一张图的横轴是热水与冰块质量的比值m1/m,纵轴是冰的溶解热的百分比误差。比如图1,横轴为质量比值3时,有10个数据点,如果看不到10个数据点,那是因为有些数据的百分比误差很接近,在绘图描点时,自动重叠遮挡了。也就是说,图1~7的每一张图的横轴每个比值对应的点都有10个。
可以从图1~7看到,这7张图有一个共性,那就是横轴在5.23时,绝大多数的数值点都落在纵轴值小于5%的地方。尤其是对于某些测试员的横轴为5.23的情况,其数值点的纵轴值非常的小。例如,比值为5.23时,测试员a的所有测量误差都小于2.5%;测试员c的所有测量误差都小于2%,而测试员g的测量结果几乎都在1.2%之下。当然也有少数的情况,例如图4,比值为5.23时,有1个百分比误差的数据点大概在8%,有2个数据点大概在5%,剩下的7个数据点都在5%之下。
根据之前的大数据研究,西安石油大学几万份历史数据里,比值为5.23附近时,也有百分比误差大于5%的情况。上面7幅图在横轴5.23时,大部分误差都小于5%,这与大数据统计的结果是一致的。证实了大数据研究的发现。
首先,由于有大数据的统计理论的指导,实验过程中已经摒弃了很多误差来源,所以图1~7的数据体现出来的面貌就与大数据结论一致;其次,虽然有7人合计490次重复实验的结果,但是其数据量还远远没达到包罗万象的程度,所以图1~7揭示出来的现象与大数据研究的结果还有差异,大数据研究揭示出来的有些现象,在图1~7里就没有体现。
测试员b、c和g的测试结果,都呈现一种漏斗形状,也就是横轴比值从3到8,中间的5和5.23对应的纵轴值最低,而两边的测试结果升高,呈一种漏斗状。
测试员a的结果又与别的测试员的不一样,虽然它中间依然是低值区域,但是其左端误差高,右端误差低,呈现的是一种勺子状。
而测试员e和f的测试结果在横轴为5时,纵轴的值已经没有相对低的优势了。
为什么会出现这样几种情况呢?这几个测试人员在进行实验的过程中,是独立操作。出现这种现象的原因,应该是这几位测试人员在严格遵守该实验要求的条件下,自由选择了剩余的可选实验条件所导致的。后来的研究发现,之前认为可自由选择(或无需重视)的实验条件,其实并不是可以自由选择(或无需重视)的。
3. 实证研究不同的质量比值对应的溶解热
图8~14从另一个角度(不同质量比值的溶解热的大小)分别描绘了测试员a、b、c、d、e、f和g独立进行冰的溶解热测试的实验结果。
在这7个测试员的实验结果图里,横轴是测量的次序,从第1次、第2次,一直到第10次。纵轴是冰的溶解热的实测值,单位是J/kg。加号、减号、乘号、黑色实体正方形、黑色实体菱形、黑色实体三角形和黑色实体圆形分别代表热水与冰块质量比值为3:1、4:1、5:1、5.23:1、6:1、7:1和8:1的情况。在图8~14里,5.23:1对应的黑色正方形方块始终围绕纵轴的329,000 J/kg波动,这个现象在本文的图1~7也体现过了。

Figure 8. Dissolution heat measured by tester a
图8. 测试员a测量的溶解热

Figure 9. Dissolution heat measured by tester b
图9. 测试员b测量的溶解热

Figure 10. Dissolution heat measured by tester c
图10. 测试员c测量的溶解热

Figure 11. Dissolution heat measured by tester d
图11. 测试员d测量的溶解热

Figure 12. Dissolution heat measured by tester e
图12. 测试员e测量的溶解热

Figure 13. Dissolution heat measured by tester f
图13. 测试员f测量的溶解热

Figure 14. Dissolution heat measured by tester g
图14. 测试员g测量的溶解热
在图10和图12,5.23:1对应的黑色正方形方块数据始终在其它数据的上部,也就是说,图10和图12测量出来的5.23:1之外的质量比值对应的冰的溶解热都比理论值偏小。
图13显示大部分的5.23:1对应的黑色正方形方块数据处在其它数据的下部,也就是说,图13测量出来的绝大部分冰的溶解热都比理论值偏大。
在其它剩下图里,例如图8、图9、图11和图14,各种比值对应的数据都是交叉的,这次测量的这个比值的数据偏大,而下次测量的这个比值的数据就可能偏小。反过来的情况也有。
为什么这7位独立测试员会测量得出上面提到的这三种不同特征的结果呢?
实际上冰的溶解热的测定实验有很多需要控制的因素,有些因素被注意到因此被人为控制了(比如热水和冰块质量的比值),有些因素还未被注意到因此被人为疏忽了(比如冰块的形状导致的外表面积差异)。由于7位测试员在制作冰块时,相互独立的进行操作,同时事先未对此进行约束,导致的具体情况就是:有的测试员使用的是块头较大的方形冰盒,有的使用的是块头较小的立方体冰盒,有的加冰块时(为了保证质量比值符合要求)随机挑选了含有扁平形状的冰块来凑够冰块质量,等等。未对这些因素进行人为约束,就有可能会导致出现图8~14的三种不同的特征。
4. 结论
本文对前人发现的冰的溶解热测定实验的关键常数5.23进行了实证研究。前人在对冰的溶解热的大数据研究中,发现了这个关键常数的疑似存在。这些大数据来自于西安石油大学历届本科生物理实验,每个本科生在教学的过程中会做一次实验并提供一份实验数据样本。前人通过对这些存档的实验数据样本进行挑选,剔除了不符合实验操作规范的数据样本,对剩下的数据进行了计算机大数据的研究,进而发现了这个基本常数5.23的疑似存在。前人的发现仅仅是基于计算机平台的大数据研究,未做实验。
本文对这个基本常数5.23做了针对性的大数据量的实证研究。实证研究的过程在西安石油大学物理实验中心展开,完全还原了前人的大数据样本的实验条件,有7位测试员参与到实证研究的实验中来,每人都做了7种不同热水与冰块质量比值的实验测量,每人对每个比值的重复测量次数为10次。因此,每位测试员都提供了70份完整的实验数据样本。7位测试员一共提供了490份实验数据样本。本文做的实证研究完全证实了冰的溶解热测定实验的关键常数5.23的存在。所有的实验都证实,只有当热水与冰块的质量比值为5.23附近时,实验测量得到的冰的溶解热的值才与理论值相差很小。
目前,还没有任何的理论公式能推导出关键常数5.23,也没有任何理论能给出关键常数5.23的物理意义。
本论文采用了设立7位测试员进行独立测试,这种研究过程不是实验研究的经典方法。严格来说,物理学实验必须能在同样的条件下重复,并且误差保持在一定范围内。本文这么做的目的,主要是因为目前没有任何理论和实验数据能证明是何种因素导致了关键常数5.23的存在。目前正在同步推进的研究是通过改变不同的参数(比如限制和不限制冰块外表面积、温度)来探索5.23的来源。所以,本文中不同测试员的实验条件不完全重复的本身,就是这种探索的一部分。
此外,我们使用大数据分析的方法来对这个案例进行研究,目前得到的结果对大数据分析方法本身也能形成有益的反馈。比如,上面的研究发现,也许因为不同的测试员在测量过程中引入了随机因素,进而导致了测量的冰的溶解热的数值呈现出不同的特征,有的数据始终偏大,有的数据始终偏小,有的数据是相互交叉的。它说明,针对大数据分析的结果来进行大数据模拟的时候,有可能带来主观的偏见,或者说有可能存在幸存者偏差。条件限制不完备的大数据模拟,有可能会导致意外的结果。