1. 引言
对于上市公司的投资价值进行科学的评价是价值投资的基础。虽然公司的财务指标能够全面的反映出股票的投资价值,但是财务指标众多,并且之间存在一定的相关关系,因此需要运用统计分析方法进行降维处理,用少数的几个因子来概括众多的财务指标所包含的信息,然后利用这些因子来对投资价值作出评价。
设上市公司的财务指标有m个,记为
,它们是评价体系中的一级指标。为了构造上市公司投资价值的评价体系,首先要根据一级指标概括产生出数目小于m的二级指标,确定每一个二级指标与一级指标之间的对应关系,并且对于各个二级指标的性质作出刻画;其次,要建立度量二级指标的数学模型,由此能够计算每一个上市公司在各个二级指标上的得分,这些得分反映了每一个上市公司在各个二级指标上的表现;最后,根据二级指标上的得分计算每一个上市公司的投资价值的综合评价值。
根据一级指标来概括产生出二级指标,实际上就是按照某种原则对于一级指标进行分类。实践中有主观法和客观法两类,主观法是基于一级指标的属性特征进行分类并且确定二级指标的性质,一般是由专家根据其丰富的专业知识和经验来制定的;客观法是完全基于一级指标的观察数据,利用数学方法,找出变化方向高度一致、或者相关性高的指标组,每一个这样的指标组产生一个二级指标,常用的数学方法是因子分析法。
每一个二级指标都是不可观察的,统计中称为潜变量。潜变量是无法直接测量的,需要用数学工具进行间接测度。令P表示二级指标的潜在的测度值,假设
是此二级指标对应的p个一级指标,则定义此二级指标的测度P为
(1.1)
其中权重
。
定义1.1 假设一个二级指标是由一级指标
所决定的,则称由公式(1.1)确定的P为该二级指
标的评价量。当权重
满足
时,则称此评价量为标准评价量。
如何科学合理地确定权重
,是对二级指标定量测度的一个关键问题。在相关的研究文献中,我们发现主要有四种定权方法:基于层次分析法的定权 [1] 、基于因子分析模型的定权 [2] 、基于结构方程模型的定权 [3] 、熵权法 [4] 。四种定权方法在数学上都有一定的合理性,但是哪一种定权方法更好呢?这就需要建立评价量(1.1)的优良性的评价标准。
决定P的是p个一级指标
,它是p维变量,而评价量(1.1)是
的一个线性组合,实际上是一维变量,所以公式(1.1)是把p维变量上的问题简化为一维变量的事情了,降维的过程必然或多或少地损失了原始数据的信息,若评价量(1.1)损失的
的信息越少,则评价的误差就应该越小,评价的效果就越好。按照这个意义,我们给出评价量(1.1)的有效性的评价标准。
定义1.2 令
表示权重为
的评价量(1.1),
表示
的信息量的度量值,
表示评价量
的信息量的度量值。对于两个评价量
和
,如果
或者等价的,
则称
的评价较
有效。
定义1.3 如果存在评价量
,满足
则称
为最优评价量。
本文的后面是这样安排的,在第二节,我们证明了最优标准评价量是存在的,其权重为
的协方差阵的最大特征值所对应的标准特征向量,然后结合因子分析法构造了上市公司的投资价值的评价模型;在第三节,我们利用所构造的评价模型,对于证券市场上的QFII概念股的投资价值进行实证分析;最后给出结论。
2. 主要结果
2.1. 最优标准评价量
记
的协方差阵为
,则
的迹
反映了
的信息量的大小,由于
是对称矩阵,所以存在p个非负特征值:
,其对应的标准特征向量记为
。
定理2.1设一个二级指标是由一级指标
所决定的,则
1) 该二级指标的最优标准评价量为
其中
,
为
的最大特征值
所对应的标准特征向量。
2) 最优标准评价量的信息损失比为
证 因为标准评价量为
,其中
,
其方差
。由于P的方差就反映了P的信息量的大小,所以最优标准评价量满足
由二次型极值理论知,最优解为
。
又因为
,所以最优标准评价量
所损失的信息量等于
,信息损失比为
2.2. 上市公司投资价值评价的一种新方法
下面我们基于定理2.1,利用因子分析法,构造上市公司投资价值的评价模型。
第一步,利用因子分析,确定二级指标及其对应的一级指标。
设
为全体一级指标构成的m维可观察的随机向量,
为其均值向量,
为其协方差阵,则
因子正交因子分析模型为
(2.1)
其中
是因子载荷阵,
与
是不可观察的随机向量,分别称为公共因子和特殊因子,满足
,
是一个对角阵,
。X的协方差可以表示为
(2.2)
由协方差结构(2.2)可知,
,称
为公共方差,
为特殊方差。协
方差结构意味着X的变化信息完全可以用公共方差和特殊方差来解释,并且绝大部分可以用公共方差来解释,因此由k个公共因子
,我们可以构造k个二级指标。
因子载荷阵
的第j列元素的平方和
反映了第j个公共因子
对于m个原始变量
总变差的贡献程度,当因子载荷阵稀疏化时,第j列中的一部分元素,不妨假设为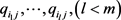 ,显著地大于本列中的其他元素,于是
,这说明第j个公共因子
主要反映了m个原始变量中
的信息,因此可以把一级指标
作为一类,由它决定第j个二级指标(不妨就记为
)。基于这样的方法,对于k个公共因子,分别确定对应的一级指标,从而产生k个二级指标,并且根据一级指标来刻画二级指标的性质。
,显著地大于本列中的其他元素,于是
,这说明第j个公共因子
主要反映了m个原始变量中
的信息,因此可以把一级指标
作为一类,由它决定第j个二级指标(不妨就记为
)。基于这样的方法,对于k个公共因子,分别确定对应的一级指标,从而产生k个二级指标,并且根据一级指标来刻画二级指标的性质。
第二步,计算二级指标的最优标准评价量。
二级指标
对应的一级指标为
,令
表示
的协方差阵,
为
的最大特征值所对应的标准特征向量,令
,则由定理2.1知,
为二级指标
的最优标准评价量。
第三步,综合评价。
令
表示k个二级指标的最优标准评价量
的协方差阵,
为
的最大特征值所对应的标准特征向量,令
,则
为投资价值的综合最优标准评价量。
3. 实证分析
本文作者曾经在文献 [5] 中,结合因子分析方法和熵权法,提出了一种改进的熵权法,并且基于2016年上市公司的财务数据,对于QFII持有的股票的投资价值进行了多维评价和综合评价。为了便于比较评价效果,我们就利用文献 [5] 的原始数据,使用本文提出的新评价模型,对于QFII概念股(见表1)的投资价值进行评价。

Table 1. QFII held part of the awkwardness in 2016
表1. 2016年QFII持有的部分重仓股
令
表示净利润,
表示净利润增长率,
表示营业总收入,
表示营业总收入增长率,
表示资产负债率,
表示净利润现金含量,
表示基本每股收益,
表示每股未分配利润,
表示每股净资产,
表示每股经营现金流量,
表示经营活动现金净流量增长率,
与
分别表示2014到2016年三年的净利润平均增长率和营业总收入的平均增长率。从华泰证券网上证劵交易分析系统(专业版II)采集表1中20只股票对应的财务数据,得到了20 × 13的原始数据阵
。利用MATLAB按照新评价模型的步骤进行计算。
第一步,计算原始数据阵
的相关阵和特征值,相关阵的特征值从小到大依次为:4.3368, 2.9449, 1.8656, 1.5417, 0.7902, 0.7123, 0.4662, 0.2048, 0.0683, 0.0516, 0.0122, 0.0039, 0.0014,由于大于1的特征值有4个,累积贡献率也达到82.22%,因此取公共因子的个数
,建立4因子正交因子分析模型。MATLAB输出的因子载荷阵为表2所示。
Table 2. Factor loading matrix after rotation
表2. 旋转后的因子载荷阵
根据因子载荷阵中高负荷的分布情况(见表2的加粗部分),可以把指标分成4类,从而确定公共因子(即二级指标)的性质。具体结果列在下表3。
Table 3. Common factors interpretation
表3. 公共因子解释
第二步,由于各个一级指标的单位不同,需要对于数据作无量纲化处理,此处使用标准化变换:
,
其中
。
下面计算表1中20个上市公司的评价值。为了计算盈利能力的评价值,先计算一级指标
,
,
经过标准化处理后的数据的协方差阵,协方差阵的特征值为
,最大特征值对应的特征向量
,则盈利能力的最优评价值
同理计算
,为了便于比较,对于
利用公式
,
作归一化处理,结果列于表4,另外,表4的最后一行给出了信息损失比。
第三步,为了进行综合评价,令
表示4个二级指标的最优标准评价量的协方差阵,计算可得
的最大特征值所对应的标准特征向量
,由于综合最优标准评价量中的
第4个权重为负,这是不合理的,因此我们按照二级指标的方差大小来确定权重,
,
得到综合评价量的表达式为
计算所得的20个公司的综合评价值列于表4的第5列。
4. 结论
根据实证分析,得到如下结论:
1) 各个二级指标的信息损失比可能相差较大,其中盈利能力的信息损失比仅仅为1.4%,说明盈利能力的评价结果是很准确的,而成长能力的信息损失比高达47.2%,所以它的评价结果是不够准确的,并且受它的影响,导致了综合最优标准评价量出现负权重的不合理现象。
2) 我们的评价方法不仅能够得到最优标准评价量,而且还能够根据信息损失比,分析评价结果的准确性,信息损失比越小,则评价结果越准确。
3) 与文献 [5] 中的评价结果相比较,在盈利能力指标上,两者在位次上的一致性达到90%,而在其余的三个指标上,两者的一致性不高。说明当信息损失比很小时,改进的熵权法的评价效果能接近于最优标准评价量。