1. 引言
随着智能交通系统的发展,以GPS轨迹数据、订单历史等形式的交通数据迅速增加。目前,交通数据的采集,正在以前所未有的速度发展,滴滴出行在成都市仅二环线一条道路每天就会产生超过3 GB的数据。但是,由于采集到的GPS数据来自于司机的手机,再通过手机网络上传到云服务器,所以采集和存储的数据除了有正确的GPS数据以外,还会有由于GPS无信号或者GPS信号弱而由AGPS提供的定位数据,这些数据通常具有较大误差。如果不能有效地清理这些包含误差的数据,就很难对采集到的数据做有效的分析,这对数据处理技术提出了新的挑战。
Jennifer Baur [1] 提出了一个有效的检测缺失数据并改良数据的方法。Patrick Röhm [2] 针对投资数据设计了一种识别企业风险投资者的数据清理程序。Tomer Gueta [3] 提出了用于量化用户级大数据清理价值的分布式模型。Ridha Khedri [4] 则设计了一种基于代数的数据清洗方法。Salem [5] 提出了基于条件函数依赖的数据清理规则。Saul Gilla [6] 针对数据流的清洗设计了一个分布式的计算框架。
由于交通系统固有的复杂性和庞大的数据量,传统的数据清洗方法面对大数据量开始力不从心。随着人工智能和机器学习的发展,大量学者提出了很多基于机器学习的分类的自动数据清洗方法。随机森林算法,作为集成学习中的典型算法,以具有极好的准确率,能够有效地运行在大数据集上,能够处理具有高维特征的输入样本,而且不需要降维,对于缺省值问题也能够获得很好的结果等优秀特性,获得了大量的研究和应用。李传冰 [7] 研究了基于机器学习对电子回旋辐射成像信号的数据清洗问题,并分别使用了支持向量机和随机森林两种方法进行了研究。张西宁 [8] 针对随机森林算法不能处理异常检测问题的局限,提出了一种基于改进Graham扫描法的单类随机森林,实现了随机森林在只有单类样本时的分类应用。徐乔 [9] 为抑制相干斑噪声对极化SAR图像分类结果的干扰,提出一种综合多特征的极化SAR图像随机森林分类方法。郑建华 [10] 针对传统分类算法难以处理不平衡数据的问题,提出了一种基于混合采样策略的改进随机森林不平衡数据的分类算法。刘云翔 [11] 在分析随机森林算法基本原理的基础上,提出一种改进的基于随机森林的特征筛选算法,并将该系统应用于肝癌预后预测。尹儒 [12] 提出了一种模型决策森林算法以提高模型决策树的分类精度。林栢全 [13] 为进一步提高基于多准则评分的推荐算法的推荐性能,着重分析了基于张量分解的推荐算法和基于聚类与降维的模糊推理系统推荐算法并基于这两种算法在目标数据集上的运行结果,提出了基于矩阵分解与随机森林的多准则推荐算法。张宸宁 [14] 为解决SMOTE算法在生成数据时会弱化数据的真实分布,同时考虑到本福特法则在处理自然数据中可以弥补数据弱化这一特点,将SMOTE算法与本福特法则相结合,提出一种新的处理类别不平衡数据的算法,以提高数据分布真实性和准确性。孙悦 [15] 、董娜 [16] 和关晓蔷 [17] 分别设计了基于Spark、贝叶斯模型组合和类别随机化的改进随机森林算法。朱冰 [18] 提出了一种基于随机森林模型的驾驶人驾驶习性辨识策略来辨识驾驶人驾驶习性。
本文基于随机森林算法,设计了一个对滴滴出行,盖亚大数据中车辆GPS轨迹数据进行自动清洗的算法。本文的结构如下,第2节介绍了滴滴出行盖亚开放数据的格式和特征。第3节定义了数据的特征集,并确定了最优特征子集的维度。并以2016年10月~11月成都市二环局部区域轨迹数据作为样本集进行了数据清洗实验。第4节对研究的结果做了总结。
2. 滴滴出行盖亚开放数据集
在过去六年的时间里,滴滴出行日订单已突破3000万,为超过5.5亿用户提供出租车、快车、专车、豪华车、顺风车、公交、小巴、代驾、企业级、共享单车、外卖等全面的出行和运输服务。盖亚数据开放计划,依托于滴滴出行的大数据,面向学术界提供真实的数据资源,其提供的海量出行数据,可以有效的帮助我们了解城市交通状况。
盖亚数据集中提供的车辆轨迹信息数据包括车辆的GPS信息和订单信息,其数据格式如表1、表2所示。

Table 1. The fields of GPS trajectory data of Didi Chuxing GAIA Open Dataset
表1. 盖亚数据集车辆轨迹信息数据数据格式
Table 2. The fields of order data of Didi Chuxing GAIA Open Dataset
表2. 盖亚数据集车辆订单信息数据数据格式
图1中展示了盖亚开放数据集中依据原始数据绘制的典型车辆速度变化曲线,从图中我们可以看到部分速度数据的剧烈变化显然是不正常的。
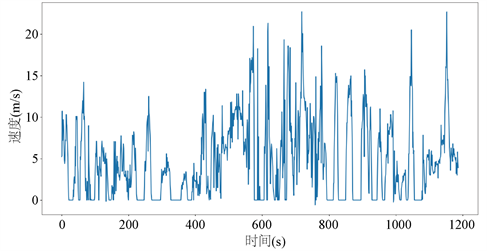
Figure 1. Typical patterns of vehicle speed from raw Didi Chuxing GAIA Open Dataset
图1. 盖亚开放数据集中典型车辆速度变化曲线
3. 盖亚轨迹数据集的自动清洗方法
滴滴出行盖亚开放数据中的GPS轨迹数据来自于驾驶员的手机GPS,其信号容易受到天气和环境的影响,精度很难得到保证。为了有效的利用这些数据,可以将盖亚数据集中的数据分为如下三类:正确数据,弱信号数据和无效数据。无效数据可以直接去除,弱信号数据可以进一步进行修正。为了识别这三类数据,首先需要找到数据的特征集。在盖亚轨迹数据集中,相邻两点的距离
可以定义如下:
(1)
,其中
和
分别是点i在GCJ-02坐标系下的经度和纬度坐标,
车辆在i时的时间,其数据为unix时间戳格式。
根据(1),我们可以得到车辆在点i和点
之间的平均速度
。
(2)
以及加速度
:
(3)
进一步的,我们可以得到车辆在点i和点
之间的平均速度
:
, (4)
对于任意的一点i,可以得到其对应的一组M维特征集
。
在随机森林算法中,最重要的参数是选定的特征子集的维度m。减小特征选择个数m,树的相关性和分类能力也会相应的降低;增大m,两者也会随之增大。所以关键问题是如何选择最优的m,为了解决这个问题需要对不同的m分别计算包外错误率。在选定的样本数据集中,m的取值范围为
,从图2中可以看出,当m = 16时,包外错误率就降到了比较低的水平,所以最终选择的特征子集的维度是16。
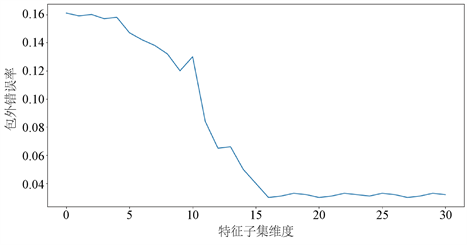
Figure 2. The influences of the number of feature variables on the out-of-bag classification error
图2. 特征子集的维度对包外错误率的影响
这里选取了2016年10月~11月成都市二环局部区域轨迹数据作为样本集(数据来源:https://gaia.didichuxing.com),该样本集包括约180 GB数据,大约1993642054条记录。该自动清洗程序基于Python中的pandas和scikit-learn来实现随机森林。图3显示了在样本数据集中,各部分数据的比例。其中,无效数据占总样本数的3%,信号弱数据占样本总数的2%,有效数据为95%,该开放数据集质量较高。
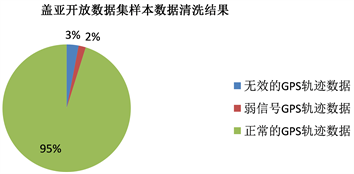
Figure 3. The results of the automatic cleaning of Sample Data Set
图3. 盖亚开放数据集盖亚开放数据集成都市二环样本数据清洗结果
4. 结论
在对交通大数据的研究中,对于数据进行有效的清洗是一个重要的研究方向。本文针对滴滴出行的盖亚开放数据集中的GPS轨迹数据,设计了一种基于随机森林算法自动数据清洗方法用来识别盖亚开放数据集原始GPS轨迹数据中的无效数据,弱信号数据和正常数据。该方法根据数据集中三类数据的数学特征选择其特征集并确定其最优的特征子集维度并以盖亚数据集中的2016年10~11月成都市二环数据集作为样本进行了实验来验证该数据清洗方法的有效性。
致谢
数据来自滴滴出行,数据出处:https://gaia.didichuxing.com。
基金项目
河北省科技计划项目No.15456135。