1. 引言
拟南芥,学名Arabidopsis。拟南芥是一种实验友好的植物,遗传背景简单清晰,在分子生物学的研究上有着很大的优势。植物基因研究人员们将其视为植物中的“果蝇”。基因序列的测序工作在各国工程组的努力下正在逐渐完善,更多生物种类的DNA,RNA以及蛋白质的序列正在填充各个基因库环境下,拟南芥基因组全序列在2000年底完全测定并公开发表。拟南芥是第一种完成全基因组测序的有花植物、第三种完成测序的多细胞生物、第四种完成测序的真核生物,而人类基因组测序在2001年第一次完成草图,2003年完成测序的最终版本,至今尚未完成真正的全基因组测序。在拟南芥之前完成测序的真核生物,只有酿酒酵母(1996年)、秀丽隐杆线虫(1998年)和果蝇(2000年)。拟南芥的基因组由5对染色体组成,总大小只有1.35亿碱基对;作为对比,人类有23对染色体,32亿碱基对,是拟南芥的23.7倍。从中可以窥见,拟南芥在植物基因序列研究有着极大的科研价值。
随着植物基因组测序的展开,拟南芥基因测序因其巨大的科研价值得到了世界各国的重视,拟南芥基因的序列的研究得到了极大的进展。由于传统的基因图示非常特殊和复杂,本文试图利用一种更为直观和普适的基因变值图示系统给出基因图示。利用该类模式,对从基因库获取到的DNA序列进行预处理后,统计碱基A,C,G,T的数量,计算AG,AT的数量,然后将数量投影到二维或者三维图像中,从而观察拟南芥的DNA序列的特征 [1] 。从给出的系列图示可以看到,新的统计分布结果为后续的基因序列的相似性分析和更高维的特征研究提供基础信息。
Hamori和Ruskin提出了G曲线和H曲线表示方法 [2] 。G曲线是在5维空间下,分别以A、C、G、T四种核苷酸以及DNA序列中核苷酸的位置为坐标。H曲线在G曲线的基础上,为了便于人们理解,将五维降为3维。为了更直观的表示,在此之后,Gates,Nandy,Leong和Morgenthaler分别独立发现了DNA序列有退化性的2维图形表示方法 [3] [4] [5] 。为了克服2维图示较高的退化性,Xiaofeng Guo [6] 等人提出了较低退化的2维表示方法。为了提供一种简单直接的图形方法,既可以消除退化性又可以将序列展示出来,Yonghui Wu [7] 等人提出了DB-曲线。DB-曲线在平面上一次表示2个核酸基的性质。但是DB-曲线不能保证任意一条DNA序列和它的图形表示之间的映射是一一对应的。而为了克服一一对应关系,Stephen S. T. Yau [8] 提出了一种新的2维DNA序列图形表示方法,但是计算冗杂。而本文的变值图示在满足了消除退化性和一一对应的基础上,更为直观和便于计算。
2. 模型处理
2.1. 相关介绍
染色体的主要化学成分和组成基因的材料是脱氧核糖核酸(DNA)编码遗传信息的生物大分子。DNA的结构是由一对多核苷酸链相互盘绕组成的双螺旋。DNA序列组成的四种核苷酸分别是腺嘌呤(A),鸟漂呤(G),胞嘧啶(C),胸腺嘧啶(T),这四种核苷酸无间隔的排列在一起构成序列。任意长度大于4的一串核昔酸被称作一个序列。近二十年来,序列的图形表示方法不断发展和演变,在研究序列局部和整体的比较分析中起到了很大的作用。序列图形表示方法的主要思想是用4个向量去表示DNA的4种核苷酸,将其映射成3维空间或2维平面上的曲线图形,由此提取序列的数值特征,从而用于DNA序列的相似性分析。
2.2. 研究模型和方法
模型处理过程如图1所示:
方法:
输入:从TAIR官网 [9] 获取TAIR10_genome_release版本的拟南芥1号染色体前36万个碱基的DNA序列。
数据预处理:首先去除基因序列文件中的信息标注;然后将文件格式转换为需要的数据格式,本文将其转换为纯文本文件格式;最后根据需要决定是否拆分数据文件,本文根据需要拆分得到前36万个碱基序列文件。
数据统计:分段处理和统计基因序列,分别以50,60,70,80,90,100,110,120,130,140,150,160和170为数据长度单位对DNA序列中的四个碱基(A, C, G, T)数量进行统计,并计算得到AT和AG的数量,作为可视化模块的输入。
输出:分段统计的DNA序列每段中四个碱基A、G、C、T的数量以及AT和AG的数量。
可视化:利用MATLAB,根据统计的数据进行绘图。
2.3. 变量说明
NUM:数据分段长度,本文中的分段长度采用距离为10的十组长度,其中NUM ∝ {50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150, 160, 170}。
V:两个碱基数据集的集合:V ∝ {AT, AG}。
其中:AT表示AT的数量,AT的数量 = A的数量 + T的数量。
AG表示AG的数量,AG的数量 = A的数量 + G的数量。
Pv:两个碱基数据集的比例。
其中:P(X, Y) ∝ P(AT, AG),X,Y分别为X轴和Y轴的坐标,通过映射生成二维图形上的点。
3. 图示结果
3.1. 图示生成流程
1) 数据预处理:将下载得到的汇编编译文件转换为纯文本格式,去掉文件中的信息标注。
2) 分段并统计:对应段落中的AGCT的数量,分别统计AG,AT的数量,以此作为X、Y轴的坐标。其中分段的长度分别为NUM。
3) 统计数据点的深度作为Z轴的坐标。
4) 运用MATLAB中的绘图函数绘图。
3.2. 图示结果
图示结果分别如下图2~14所示:
3.3. 简要分析
1) 当以50为统计长度单位时,AT和AG的数量主要分布于30到40区域,数据特征最为明显。
2) 当以100为统计长度单位时,AT和AG的数量主要分布于70到90区域,数据特征相对明显。
3) 当以150为统计长度单位时,AT和AG的数量主要分布于80到120区域,数据特征开始离散化,但较长度为200生成的图仍相对明显。

Figure 2. Calculate with 50 as the data length unit
图2. 以50为数据长度单位统计

Figure 3. Calculate with 60 as the data length unit
图3. 以60为数据长度单位统计

Figure 4. Calculate with 70 as the data length unit
图4. 以70为数据长度单位统计
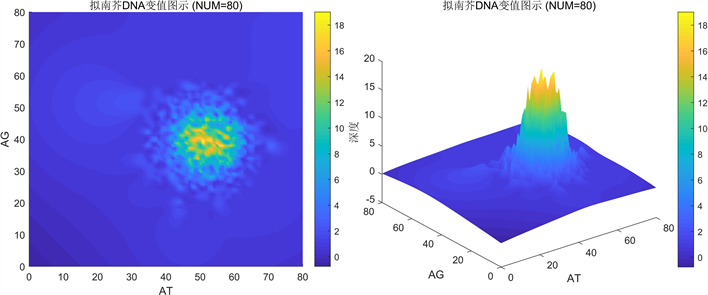
Figure 5. Calculate with 80 as the data length unit
图5. 以80为数据长度单位统计
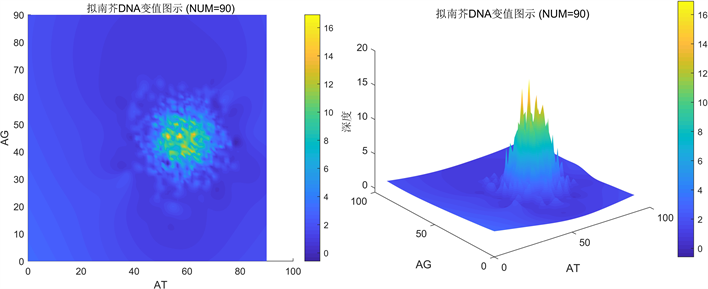
Figure 6. Calculate with 90 as the data length unit
图6. 以90为数据长度单位统计
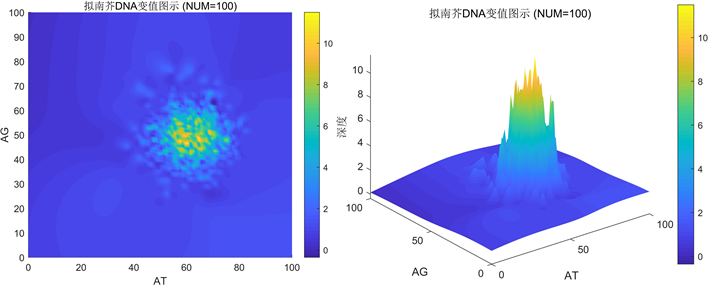
Figure 7. Calculate with100 as the data length unit
图7. 以100为数据长度单位统计
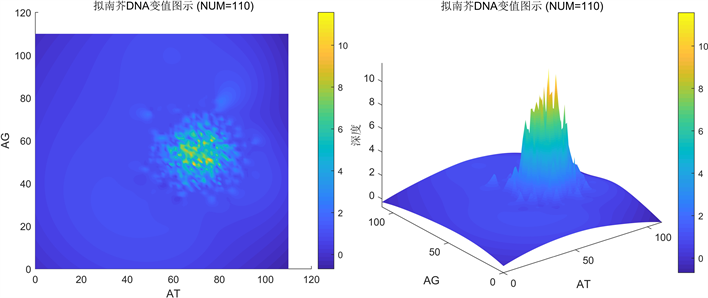
Figure 8. Calculate with 110 as the data length unit
图8. 以110为数据长度单位统计

Figure 9. Calculate with 120 as the data length unit
图9. 以120为数据长度单位统计

Figure 10. Calculate with 130 as the data length unit
图10. 以130为数据长度单位统计

Figure 11. Calculate with140 as the data length unit
图11. 以140为数据长度单位统计
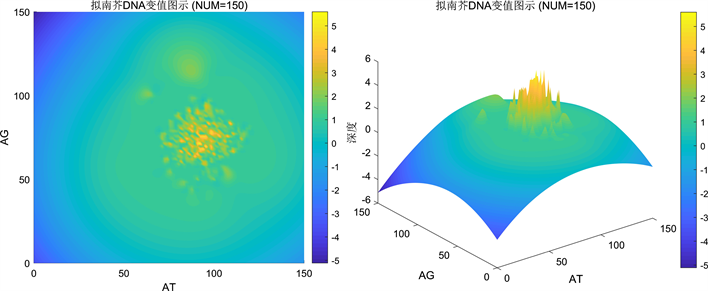
Figure 12. Calculate with 150 as the data length unit
图12. 以150为数据长度单位统计

Figure 13. Calculate with 160 as the data length unit
图13. 以160为数据长度单位统计

Figure 14. Calculate with 170 as the data length unit
图14. 以170为数据长度单位统计
4) 数据中心点与数据分段长度有关,体现了一一对应关系,避免了因不同碱基序列得到相同图示的问题。
4. 总结
拟南芥的基因在植物基因研究上的作用类似于果蝇在真核生物研究上的作用。本文所做的拟南芥变值图示系统可以更方便和清晰地看到拟南芥DNA序列的特征。随着植物基因序列的研究领域里更多新型测序和研究方法的出现,变值图示系统在将来也许能为植物基因的高维研究与序列分析提供更有效的参考。
致谢
感谢郑智捷教授对本文工作的悉心指导,感谢云南大学软件学院和云南省重点工程实验室的支持。