1. 引言
目前OPNET是世界上最先进的网络仿真开发和应用平台。OPNET采用离散事件驱动的机理,通过模拟“事件”的推进过程描述网络状态的变化,与时间驱动相比,离散事件驱动的计算效率更高 [1] [2] [3] [4] 。但是当网络的规模和流量很大时,OPNET仿真会变慢,严重时会导致仿真无法继续,仿真效率大打折扣。
关于如何提高大规模条件下的OPNET仿真效率问题,文献 [5] [6] 尝试通过软件开发扩展OPNET功能使之在多台计算机上并行运行,将一个大规模网络分散到两台或者两台以上的计算机上运行,使得各台计算机进行协调联合仿真,通过多台计算机分担一台计算机的负荷从而提高仿真效率。这种方法工作量巨大,且耗时耗力,方法不具代表性;文献 [7] 以ATM和FDDI包变换网络下的OPNET仿真为例,从仿真参数设置方面探讨了提高大型网络仿真效率的两种方法;文献 [8] 以大规模无线Mesh网络为背景,设计并实现了网络安全协议仿真平台,对大规模网络条件下OPNET仿真效率的改进和提高问题并没有阐述。
综上所述,有必要对如何提高大规模网络条件下的OPNET仿真效率进行尝试,探讨并形成通用性或具有代表性的解决方案(以话音网络为例)。
2. 网络拓扑的构建
节点数多且网络分布比较复杂的情况下,手工绘制拓扑图的做法不可取。OPNET中的拓扑快速配置(Rapid Topology Configuration)功能只适用于有限种类的拓扑结构,且生成的模型节点可能重叠。针对这种情况,OPNET提供了网络拓扑导入功能。主要分为三种 [9] [10] [11] :
2.1. Import Topology from Circuit Switch Text Files
该功能只适用于promina族节点,且需要对节点、链路分别编写文件,效率较低。
2.2. Import Topology from XML Files
通过XML编程(主要代码)实现图1中拓扑结构如下:

由此可见,当网络节点数很多且分布较复杂时,采用XML编程导入网络拓扑的工作量很繁琐。同时XML只是标记语言,不能通过循环语言实现网络模型的重复构造。
2.3. Import Topology from EMA Files
EMA (外部模型访问)技术通过类C and C++语言使OPNET在没有图形编辑器的情况下实现网络模型的读写控制。
以下为实现一个具有100个交换节点的网络拓扑图的部分EMA代码:
/*坐标x,y的值可通过MATLAB编程,即先生成一组随机数,然后利用K均值方法获取分布均匀的点坐标,剔除间隔太近的点*/


拓扑构建的具体流程如下:
1) 打开OPNET控制台窗口,进入上述EMA代码文件(后缀名为*.em.c)所在目录,输入命令op_mkema -m文件名(本例为tele_circuit-EMA,不加后缀);
2) 执行刚创建的可执行文件<文件名.i0.em.x>。具体如图2所示:
3) 点击菜单File->Model Files->Refresh Model Directories刷新模型目录,然后点击Scenarios→Scenario Components→import...即可。生成的网络节点如图3所示。

Figure 3. Network topology established by EMA technology
图3. 利用EMA技术建立的网络拓扑
由以上三种拓扑构建方法可以看出,在网络节点数多且分布不规律的情况下,利用EMA技术生成网络节点的做法是可取的,减少了仿真前期的工作量。
3. 仿真效率的提高
由于OPNET采用离散事件仿真机制,实现时必须要有一个时钟进程始终在运行,整个仿真过程贯穿着事件发生时刻的生成、存储和扫描,这将占用大量的机器内存和处理时间,尤其对大型网络,仿真运行速度很慢,达不到实时的要求 [12] [13] [14] 。以下为主要的解决方法。
3.1. 混合式仿真(Hybrid Simulation)
OPNET中提供了两种流量模型 [15] :
1) 前景流量模型——application traffic
主要收集IP层以上的性能参数,能够详细刻画每个包的发送与接收过程以及不同协议的影响,但耗时大且占用系统资源多。
2) 背景流量模型——background traffic
采用数学分析的方法,主要收集IP层及以下各层的性能参数,耗时小且占用系统资源少,但精度不高。由于OPNET10.5A中不支持在传统电路交换的环境下的background traffic flow import功能,即不能用flow analysis模块分析整个网络的链路流量利用情况。主要有两种解决方法:
①使用OPNET中的promina节点模块族 [16] ,代替普通的SSP节点(图4所示)。即在promina节点之间导入背景流量,然后利用flow analysis功能分析整个网络的运行情况,这样可节省运行时间。
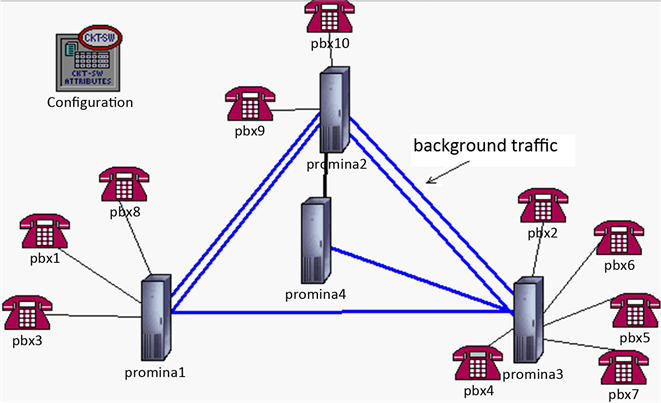
Figure 4. Using promina nodes as circuit switches
图4. 利用promina节点充当电路交换机
②通过编程,构造新的SSP节点,其相对于原有的SSP节点多了如下功能:
支持背景流量的设置,即可以配置相关参数,使其具有background utilization流量,同时也必须构造新的链路模型,使其具有可以设置background loads的功能。分别如图5、图6所示:

Figure 5. Configuration of background traffic of switch nodes
图5. 交换机节点背景流量的配置
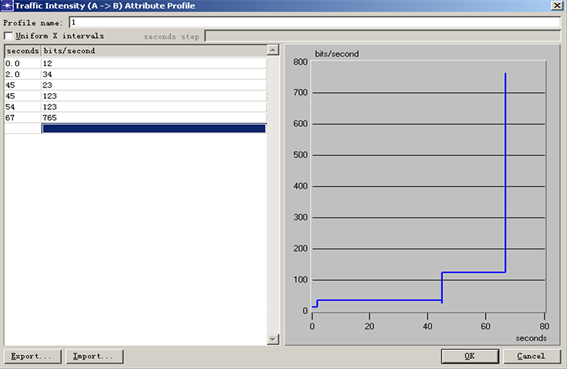
Figure 6. Configuration of link background traffic
图6. 链路背景流量的配置
实际中,利用OPNET中的混合仿真(Hybrid Simulation)机制,可根据要求配置explicit traffic与background traffic的比例,在保证仿真精度的同时也能提高仿真的效率。
3.2. 汇聚网络流量,简化网络模型
用一个子网节点(subnet)代表部分SSP节点,使得两者产生的流量均等,最后将各子网连接起来。如图7所示。
但该方法不能精确到每个SSP节点,精度降低。
3.3. OPNET与其他编程软件相结合
先借助编程软件(如MATLAB),编程得到各局间链路的利用率,再利用OPNET中的color by link loads功能(如图8所示),根据链路的利用率大小用不同的颜色标示(如75%以上标注为红色,50%~75%标注为黄色,50%以下标注为绿色),如图9所示:
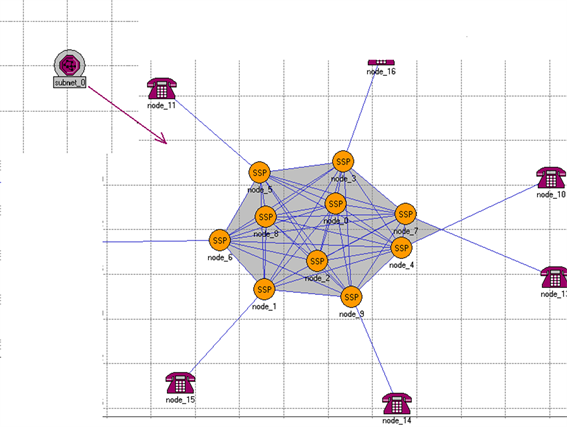
Figure 7. Replacing some SSP nodes with subnet virtual nodes
图7. 用子网虚拟节点代替部分SSP节点
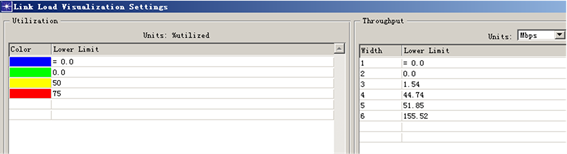
Figure 8. Color settings for link utilization
图8. 链路利用率大小的颜色设置
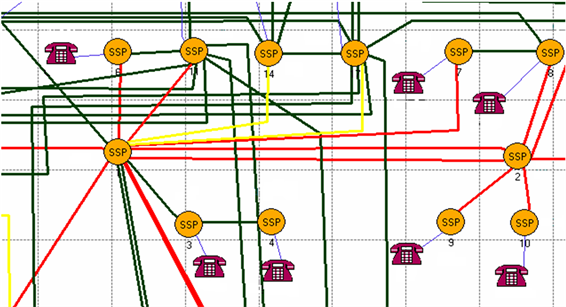
Figure 9. Color labeling of link utilization
图9. 各链路利用率的颜色标示
3.4. 分布式仿真
随着复杂大系统仿真应用的不断扩展以及仿真器的物理分布性的限制,分布式仿真技术应运而生 [17] [18] [19] 。高级体系架构(HLA,High-Level Architecture)以其强大的技术优势成为该领域的主要解决方案。作为新一代分布式仿真标准,目标是要提高不同仿真间的互操作性及仿真、组件的可重用性。
为促进仿真系统间的互操作,HLA采用对象模型描述联邦及联邦中的每个联邦成员,并借助对象模型模板OMT给出联邦在执行过程中需要交换的数据的规范化表达。HLA对象模型分为两类:
1) 联邦对象模型(Federation Object Model, FOM):用来定义联邦成员间公用的数据交换;联邦成员需要公布和定购的数据(实例属性和交互实例)必须事先在FOM中规定,否则无法交互。
2) 仿真对象模型(Simulation Object Model, SOM):用来描述单个仿真应用所能提供给联邦的功能。确定上述两种模型的主要工作是确定联邦中各个联邦成员订购与发布的对象类和交互类。HLA规范规定所有对象模型都应该包含在联邦成员中。
RTI (Run Time Interface)是HLA体系结构的运行支撑系统,是HLA的核心。在HLA框架中,联邦成员之间不能直接通信,必须通过RTI传递信息以实现两者之间的通信,即联邦成员必须向RTI“公布”自己所产生的数据,也必须向RTI“定购”自己所需要的数据。然后RTI根据“公布–定购”关系,对数据的发送方和接收方进行匹配,确保数据只传递给需要它的联邦成员。
联邦运行过程中,RTI根据FOM和SOM的定义传输数据。具体通过MAP文件映射将OPNET中的包映射为RTI总线能够识别的包。OPNET本身提供了与HLA的接口结点,使得OPNET仿真可以和HLA联合实现通信。
对于本例,map文件的部分代码如下:

同时需在fed文件中定义交互类,对于本例,共有两个交互类Order和Order_Reply,即:


但是基于HLA的分布式仿真也存在不足:
1) HLA结构虽然在许多方面改进了原有的体系结构(如DIS协议,ALSP等),但分布式仿真标准由于其广泛适用性、可伸缩性及用户自定制性给数据收集与分析带来了很多新的挑战。比如基于HLA仿真数据的收集与分析、实时查询,态势显示,事后回顾,有效性分析等需求,同时需考虑到数据收集成员对网络带宽的影响,实时分析困难,软件重用性差等等,这也是仿真领域的研究热点。
2) 基于HLA的分布仿真应用中常常会有大量的数据需要通过RTI进行传输。通常在C++程序实现中,由于RTI并没有定义对象模型在编程语言中的具体的数据类型,所以联邦成员在通过RTI提供的服务更新对象类属性或发送交互参数时,由于没有统一的规范,在程序实现时容易造成混乱和大量的代码重复,特别是程序由不同的程序员实现时更容易出现这样的状况。如果传输的属性或交互参数是复杂数据类型且其数量是由程序动态决定时,如果使用C++标准容器存放,则由于标准容器有动态内存分配且隐藏实现细节而导致无法直接由RTI传递,这也使得程序员在发送数据时须经过复杂的处理来完成内存转移拷贝。
3) 分布仿真系统运行中的数据采集要以写文件的方式收集,不能通过OPNET中传统的统计量收集的方法。而写文件的方式中,目前的基于数据库、文本文件和简单二进制文件的存储方法存在空间利用率低、速度慢、难以支持复杂数据类型、读取困难等缺点。
4) 仿真的运行需要手工操作,比较繁琐。
①推进仿真时间:t + 时间,如要将仿真推至5 s,则在HLA控制台中输入t 5即可,且
仿真时间只能向前不能向后,否则报错。
②发送数据包:f + 数据,如f 3 4 9 2 7 0 20 8,表示隶属于子网结点3中的9号节点在4.7 s时向结点2发了一个数据包。用此命令可以方便的在调试中向各个网发送包。同时OPNET工程必须从OPNET控制台启动,不能直接从仿真软件中运行。
5) 利用OPNET软件仿真时,节点间的数据包传送存在时延和丢包,而HLA仿真中,数据包在两个工程间传送时,不存在时延和丢包,因此收集的结果欠准确。
4. 结束语
当网络规模增加、网络业务量提升时,利用OPNET仿真网络性能会增加系统资源消耗、降低仿真效率,严重时会导致仿真无法进行甚至自动退出。本文以话音网络性能仿真为背景,分析了大规模网络条件下利用OPNET仿真可能出现的问题,并从如何构建网络拓扑和提升网络仿真效率等两个方面对可能的解决方案进行了验证说明,给出了相应的解决过程,如可以利用EMA技术生成网络节点的方法构建规模较大且节点分布不规律的网络拓扑,可以根据实际需求择优选取混合式仿真、汇聚网络流量并简化网络模型、OPNET与其他编程软件相结合、分布式仿真等方法提高大规模网络条件下的OPNET仿真效率,相关结论具有一定的参考价值。