1. 引言
机器学习 [1] 是一门多领域的学科,主要研究计算机如何模拟和学习人类的各种活动,并在储存信息的过程中不断达到自我完善。现如今,机器学习已经广泛应用在实际生活中。分类问题是机器学习领域中最常见的一类问题,也是机器学习领域的研究热点之一,如模式识别 [2] 、文本分类 [3] 、手写字体识别 [4] 、人脸图像识别 [5] 等领域。然而,通常的分类问题的输入是向量的形式呈现的,传统的分类学习机也只是解决输入为向量的分类问题。事实上有些数据是随着时间变化的,应当以动态的角度来看待数据,寻找出数据中隐含的某种函数特性,如果我们利用函数型数据分析技术找出数据隐含的连续函数,也可进一步对函数求一阶或者二阶导数,能挖掘数据中隐含的更多信息。本论文主要针对输入为函数型数据的分类问题提出了一个新的函数型线性判别分析算法。
线性判别分析 [6] (linear discriminant analysis, LDA)是Fisher在1936年首次提出,在人脸识别 [7] 、食品安全 [8] 、医学 [9] 等领域有广泛的应用。在模式识别领域中,贝叶斯分类效果最优,但由于其概率密度函数难以估计,使得线性分类器(如Fisher线性判别分析)被广泛的应用在实际生活中。Li (2011) [10] 等首先将数据利用线性判别分析方法把训练样本投影到子空间中提取数据的相应特征,再利用支持向量机进行分类。实验结果表明,该方法不仅起到降维的作用,同时提高了分类准确率,大大缩短了计算的时间。Li [11] 提出了2–维线性判别分析(2-dimensional linear discriminant analysis, 2D-LDA)的方法,该方法从图像矩阵中提取出重要的特征,进而计算类间散度矩阵和类内散度矩阵。而线性判别分析和2–维线性判别分析存在稀疏性的问题,在特征提取中存在遗漏重要数据信息的情况。但以上的分析方法都无法解决以函数型数据为输入的分类问题。从而需要对函数型数据的内在结构和特性进行了解和分析。
函数型数据的研究是Ramsay [12] 在1982年首次提出,阐述了函数型数据不再是传统的静态数据,而被视为动态数据,当原始数据信息丢失或者缺损时,可利用数据的函数特性进行填补。1991年,Ramsay [13] 提出了一些适用于具有时间序列变化数据的分析方法,如加拿大气象站的日降水量分布情况和温度变化的联系,用函数型主成分分析方法解决了这一实际问题。随后,Ramsay在《Functional Data Analysis》 [14] 中对函数型数据进行了详细的概括和总结,其中包括函数型数据的概念,处理函数型数据的方法,并将主成分分析、典型相关分析、判别分析及线性模型等经典方法引入到函数型数据分析中。
针对函数数据的分类问题,本文提出函数型线性判别分析,该方法把函数型数据表示成光滑曲线或者连续函数,从而我们可以考虑到函数的特性(如连续、求导)。函数型线性判别分析的主要思想是通过给定的训练集,寻找一条投影函数,使同类样本的投影点距离尽可能的接近,同时又使异类样本的投影点尽可能的远离。基函数法是常见的将原始数据转化为函数的平滑技术之一,即将函数型数据在一组基下进行展开。因此寻找这条投影函数,就变成寻找基函数的系数向量。函数型线性判别分析的优点之一是可以求出导数曲线或者微分曲线,并通过求导或者微分我们可从数据中挖掘出隐藏的重要信息,从而得到更好的分类结果。
本文的组织结构如下:第二章:给出了一些准备工作,对线性判别分析进行了简单的回顾。第三章:详细的介绍了本文提出的方法。第四章:把函数型判别分析与线性判别分析方法进行比较,用数值实验说明本文方法的可行性和优势。最后第五章是本文的结论与展望。
2. 相关工作
线性判别分析方法的主要思想是将样本投影到一条直线上,使其同类样本的投影点更聚集、不同类样本的投影点尽可能的分离,从而最终确定投影方向
,其主要过程如下:
给定训练集
,
,令
分别表示第
类样本的集合、均值向量、协方差矩阵。则第
类均值为
,其中
表示第
类样本的个数。
类内散度矩阵表示该类样本到中心的距离即:
(1)
类间散度矩阵表示各类中心到总体中心的距离即:
(2)
为使每类在
方向投影后的样本距离尽可能的大,则优化模型为:
(3)
其中式(3)是类间散度矩阵
相对于类内散度矩阵
的广义Rayleigh熵。由于式(3)的分子和分母都为二次项,因此与长度无关,只与方向有关。令
(不失一般性),则式(3)等价于最小化
,利用拉格朗日乘子法,最终式(3)等价于
,即为一般特征值问题。
3. 函数型线性判别分析
函数型数据两分类问题描述如下:
给定训练集
,我们的目的是找一条投影曲线
,使同类样本的投影点尽可能接近,使异类样本的投影点尽可能的远离。找到投影曲线后,再对新样本进行分类,将其投影到同样的曲线上,最终根据投影点的位置来确定新样本的类别。则优化模型如下:
(4)
其中
,
分别表示第
类样本的均值函数,协方差矩阵。将数据投影到函数
上,两类样本的中心在函数上的投影分别为 和
;则让类中心之间的距离尽可能的大,即
尽可能的大。将所有样本点都投影到这条曲线上,则同类样本的协方差矩阵分别为
和
。我们需使同类样本的距离尽可能的接近,即让两类样本的协方差的和尽可能的小。
和
;则让类中心之间的距离尽可能的大,即
尽可能的大。将所有样本点都投影到这条曲线上,则同类样本的协方差矩阵分别为
和
。我们需使同类样本的距离尽可能的接近,即让两类样本的协方差的和尽可能的小。
通过上式(4)求得投影函数为
,则对新来的样本
投影到函数
下的得分定义为
,即
。最终计算得分
与均值函数
的距离,根据所在投影点的位置确定新样本的类别;也就是说,新的样本与哪一类中心点越接近,就被分到这一类,即
。
由于函数型数据是无穷维的,则需对函数型数据进行降维处理。常见的降维方式为函数型数据在一组基下进行展开。具体如下:由
个已知的基函数的线性组合来拟合已知的曲线样本
,公式如下
(5)
其矩阵形式表示如下
(6)
其中
表示
维基函数,其系数向量为
。当
取的越大,近似的精度越高。本文的目的是寻找函数型线性判别分析下的投影函数
,则将
同样用基函数线性组合的形式展开为
,因此寻找投影函数就变成了寻找基函数所对应的系数向量
。
因此通过基底函数法,把函数型数据用基函数的线性组合展开,所得第1类的协方差矩阵表示如下:
(7)
同样地,
类的协方差矩阵可以表示为:
(8)
其中矩阵
为
阶对称阵其元素表示为
。
分别是关于系数矩阵
的协方差矩阵。同样地,把
也用基底函数法进行转换公式表示如下:
(9)
其中
是第i类样本的均值函数,表示为
,
为
的系数向量,则优化模型为
(10)
由于式(10)的分子和分母都是关于
的二次项,因此式(10)的解与
的长度无关,只与其方向有关。不失一般性,令
,则式(10)等价于:
(11)
定义拉格朗日函数:
(12)
其中
为拉格朗日乘子,并利用
条件可得:
(13)
由拉格朗日乘子法,上式等价于
(14)
令
,即求
的一般特征值问题。
综上所述,函数型线性判别分析的算法为:
算法:函数型线性判别分析算法
输入:训练集
输出:
1) 选择基函数,求解样本函数的系数
。
2) 计算协方差矩阵
和基矩阵
。
3) 计算(14)式得出
。
4) 代入
并计算
。
4. 数值实验
4.1. 人工数据的数值实验
我们用人工数据测试本文的方法,本节数值实验分为两部分,第一部分为线性可分的,第二部分为线性不可分的;首先介绍本节数值实验的第一部分,我们构造2个多项式曲线,多项式的最高次数为4次幂,其区间为
并且随机加了噪声,为了使模型几何意义更加明确,我们选取一组多项式系数构成多项式曲线。
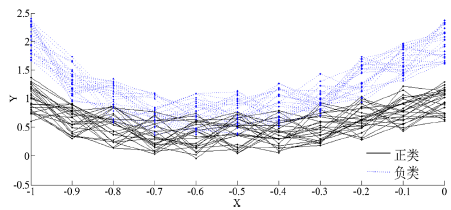
图1(a)表示由离散点构成的50条不同类曲线,每类各有25条曲线,黑色线表示正类曲线,蓝色表示负类曲线。并对曲线随机加上噪声。从图1(a)可看出我们很难用肉眼分清哪条曲线属于哪一类。图1(b)表示通过函数型数据拟合后的曲线,我们可以很显然的看出经过基函数法后的曲线不仅变得光滑而且能清晰地区分两类,其中图中蓝色虚线表示负类,黑色实线表示正类。
图2表示随机一次五折交叉验证过后的分类情况,其中“△”表示正类的训练集,“〇”表示负类的训练集。我们可从图2看出同类样本点的距离都很接近,并且不同类样本点的类间距离很远,能够清晰地区分两类。
 (a)
(a) 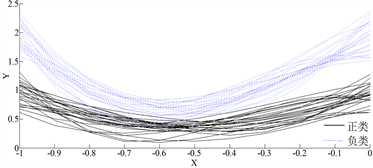 (b)
(b)
Figure 1. (a) Curves of 50 different types of artificial data sets, (b) Curves fitted by basis function method
图1. (a) 50条不同类的人工数据集构成的曲线,(b) 用基函数法拟合过后的曲线
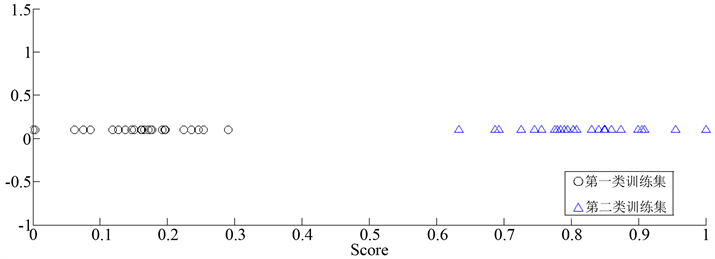
Figure 2. Classification of 50 curves using functional linear discriminant analysis
图2. 50条曲线运用函数型线性判别分析方法后的分类情况
第二部分数值实验是线性不可分的曲线,如图3(a),我们从肉眼角度观察曲线有重叠的部分,很难区分各个曲线属于哪一类,图2(b)经过基函数法过后曲线变得较为光滑,能够大致看清分成两类的曲线趋势。表1为经过函数型线性判别分析方法过后的两次人工数据的准确率,线性可分的准确率接近于100%,说明在本文方法中,很好的把类内的样本点聚在一起,同时,不同类的样本点的类间距离较远;线性不可分的准确率为91.5%,由此可见在曲线重叠的部分导致类间距离变小,从而影响了线性不可分曲线的准确率。而把函数型数据离散化后,用原始的线性判别分析方法进行分类,无论是线性可分的数据还是线性不可分的数据,结果都没有函数型线性判别分析方法的准确率高。
 (a)
(a) 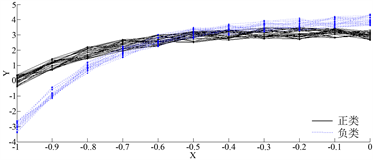 (b)
(b)
Figure 3. (a) Curves of 50 different types of artificial data sets, (b) Curve fitted by basis function method
图3. (a) 50条不同类的人工数据集构成的线性不可分曲线,(b) 用基函数法拟合过后的曲线
4.2. Spectrometric数据集
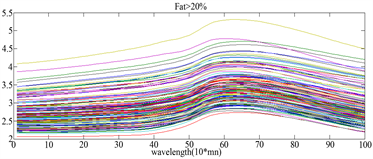
本节介绍的Spectrometric数据集来自食品工业,每个观测值是肉类样本(经过精细切碎后)的近红外吸收光谱,一共有215个光谱样本。观测值中包括了在波长为850~1050 nm范围内的100个吸收光谱。此数据集的分类问题在于从脂肪含量低(低于20%)的肉类样品分出高脂肉类(高于20%)。
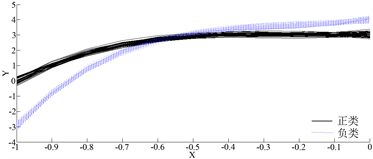
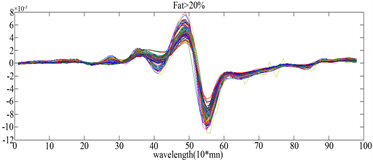
图4表示一阶求导后的图像,图5(a)表示脂数低于20%的曲线,图5(b)表示脂数高于20%的曲线,因为图5(a)、图5(b)中的曲线波动基本一致,我们无法从一阶求导后的曲线中肉眼看出类别。而图(5)表示二阶求导后的图像,从图中可看出经过二阶求导后的函数曲线有明显不同的波动。因此我们可从求导后的曲线得出隐性的函数条件,从而运用函数型线性判别分析的方法进行分类。
 (a)
(a) 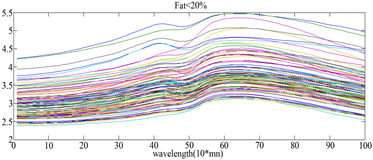 (b)
(b)
Figure 4. First-order derivation of spectrometric data
图4. 对spectrometric数据进行一阶求导
 (a)
(a) 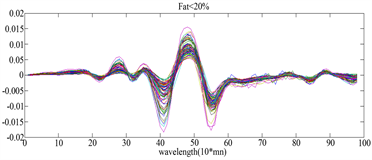 (b)
(b)
Figure 5. Second-order derivation of spectrometric data
图5. 对spectrometric数据进行二阶求导
图6取20%的spectrometric数据一阶求导后的分类情况,发现虽然同类样本距离较为接近,但异类样本的距离没有区分开,因此分类不是很明显。图7取20%的spectrometric数据二阶求导后的分类情况,明显地,我们可以看出求完二阶导后的异类样本区分开了,但仍然会有3个异常点分错类别。表2是5次五折交叉验证后的准确率,其平均准确率为98.30%。
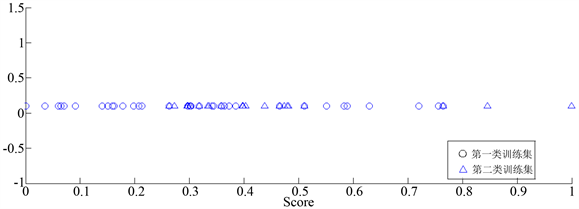
Figure 6. Take 20% of the spectrometric data after the first-order derivation classification
图6. 取20%的spectrometric数据一阶求导后的分类情况
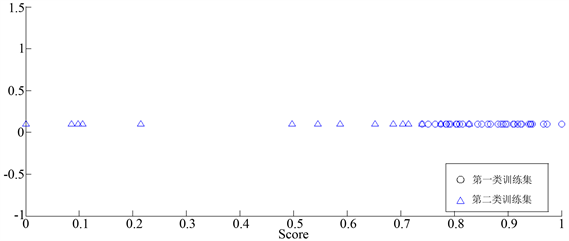
Figure 7. Take 20% of the spectrometric data after the second-order derivation classification
图7. 取20%的spectrometric数据二阶求导后的分类情况
5. 结论
本文是在传统的线性判别分析的基础上,针对函数型数据,提出了函数型线性判别分析算法来解决函数型数据的两分类问题。该方法证明函数型数据可以挖掘其函数特征,例如连续,求导。实验结果表明,spectrometric数据集经过二阶求导过后分类效果才明显提高。该方法不仅能对函数型数据分类,还可以对离散数据进行分类,通过拟合估计出的函数转换成函数型数据,同理对其数据进行分类。