1. 引言
红外被动测距技术由于不向外辐射能量,具有极强的隐蔽性和军事价值。目前的红外被动测距技术主要有基于几何原理的被动测距 [1] [2] ,基于红外图像的被动测距 [3] 和基于光谱吸收的被动测距 [4] [5] [6] 等,这些方法都是通过物理原理或数据分析的方式来建立具体的模型,再利用算法估计模型参数,最后实现测距。这些方法虽然都有着较强的理论基础,但计算相对复杂且距离解算条件都比较苛刻。而机器学习属于一种数据驱动的方法,它能够按照一定的策略,自动地建立输入和输出数据的映射关系,这为红外被动测距提供了一种新的思路。本文首先用MODTRAN获取了不同距离、温度和天顶角下的大气透过率数据,然后结合红外辐射传输理论将这些数据转换为对应的探测器电压值,最后基于这些电压值及其对应的距离建立了集成学习测距模型,并用测试数据检验了模型的预测效果。
2. 红外被动测距原理
自然界中任何温度大于绝对0摄氏度,物体都会发出红外辐射,普朗克在1990年推导出了黑体辐射公式,
(1)
其中
为黑体的光谱辐出度,单位为:W/(m2∙m),
为波长,单位为m,T为黑体的温度,单位为K,c1为第一辐射常数,
;c2为第二辐射常数,
。
物体发出的红外辐射在地球大气中传输时会受到大气的衰减,这种衰减是由大气的吸收和散射共同造成的。假设目标黑体的初始辐照度为
,则在距离R处目标的辐照度变为
(2)
其中
为大气透过率 [5] ,是一个随波长和距离变化的物理量,
(3)
为大气的消光系数,由吸收系数和散射系数组成,消光系数和大气的气象条件密切相关。大气透过率
是一个与波长、距离气象条件等因素相关的量,难以直接计算,该数据可由MODTRAN软件仿真生成。
假设在距离目标R处有一个红外探测器,探测器的电流响应率为rI,单位为
,探测器的有效光敏面积为AS,在不考虑背景和接受电路本身噪声干扰的前提下,探测器最终的输出光电流为
(4)
得到光电流后可以通过I/V变换电路将光电流转换为适合的电压值,再经过对电压放大、滤波等处理后,送入A/D转换器转换为数字信号,最后将数字信号送入微处理器如DSP中,处理器通过一定的算法解算出最终距离。从上面分析可以知道,处理器最终得到的数字电压值是一个和目标距离相关的量,可以首先在实际中建立不同温度、天气和距离条件下对应电压值的数据库,然后基于这些数据库采用数据驱动的方式建立测距模型。
3. 集成学习算法
集成学习是一种将多种学习器结合起来以提升预测效果的机器学习算法,根据学习器集成方法的不同可分为bagging、boosting架构。
Bagging [7] 是一种并行的集成学习方法,它首先对原始训练数据集进行有放回的抽样,从而得到多份数据集,然后对每一份数据集训练一个基模型,这些基模型彼此是独立的,最后采用投票法(分类问题)或平均法(回归问题),将多个基模型的输出结果融合起来得到最终的输出。Boosting [8] 则是一种串行的训练策略,它每轮迭代生成的模型都和前一轮的模型有一定的关系,最终的模型为一系列模型的线性组合,基于boosting架构的方法有GBDT、xgboost、adaboost等。
本文的测距模型主要采用了Boosting的策略,Boosting中采用了gbdt、adaboost、xgboost这3种提升方法。gbdt的全称是Gradient Boosting Decision Tree,是Freeman [9] 提出的一种分步加性模型,在每次迭代中通过用决策树来拟合损失函数的负梯度,以此不断的减小误差,最终模型由一系列决策树相加构成,对于均方损失函数,其负梯度就是真实值和预测值之间的残差。
Adaboost [10] 的全称是adaptive boosting,它通过给不同的样布赋予不同权值的方法来改变样本的分布,每次给分类错误的样本较大的权重,在训练过程中该样本会被更多的关注到,并且每次训练中给予误差较大的模型较小的权重,最终的模型为多个基模型的加权组合。
Xgboost的全称为extreme Gradient Boosting,它是由陈天奇 [11] 提出的在GBDT基础上的一种改进算法,利用了损失函数的一阶、二阶导信息,同时为了防止过拟合,在损失函数中引入了正则化项。Xgboost引入了并行化的训练方法,相对于gbdt有着更快的训练速度。
集成学习算法的基学习器采用了决策树,预测时不需要复杂的数学运算,所以相对神经网络,集成学习具有更快的预测速度。本文首先基于仿真生成的数据集建立了上述3种模型,并对每种模型的参数进行了优化,最后采用了stacking策略将3种模型融合起来以提升测距精度。
4. 训练数据的获取与处理
本文中用来建模的数据是通过仿真生成的,假设目标发热物体是标准黑体,由公式(1)可知,只要知道发热物体的温度和对应的波段,就可以计算出物体的光谱辐出度,本文中设置目标的温度范围为273 K~373 K,其中温度增加的步长为5 K,所以总共有21个温度段。3 um~5 um的中波波段有较高的大气透过率,同时又可以携带很高的能量,所以本实验用到的2个波段分别为3.5 um~4.0 um、4.5 um~4.7 um,通过公式(1)可以计算出不同温度段,对应波段的光谱辐出度。公式(2)中的大气过率数据由MODTRAN生成,MODTRAN是由美国空军地球物理实验室研发的一款专业的大气辐射传输模拟软件包 [12] 。本文在MODTRAN中设置的波长范围为3.5 um~4.7 um,波长增加的步长为0.0016448 um。天顶角范围为5~90度,天顶角的增加步长为5度,季节分别为中维度夏季和冬季,每个季节又分为3种气溶胶条件,乡村23 km,城市5 km,以及海洋23 km,距离增加范围为500 m~23 km,增加步长为50 m,具体设置如图1所示。
在MODTRAN中分别按照上面的距离段设置好参数,然后运行得到不同距离和天顶角下对应的透过率,再结合公式(2)可以计算出不同经过大气衰减后的辐出度。假设探测系统的光伏探测器选用滨松的P-13243,其有效光敏面积为0.7*0.7 mm,电流响应率为4.5 mA/W。再按照公式(4)可以计算出不同距离条件下2个波段的光电流值
和
,然后在后级处理电路中将
放大一定的倍数作为采集到A/D转换器的电压值U1和U2的放大倍数为1e6,U1和U2以及目标的高度角在实际中都是可测的,把它
们作为训练数据的特征,距离作为预测值,为了增加模型的准确性,将
也作为训练数据的一个特征,最终用于训练的数据格式如下表1。

Table 1. The format of training data
表1. 用来训练的数据格式
5. 本文建模的流程与预测结果
本文建模时采用了python的scikit-learn库,scikit-learn是一款基于python的第三方开源机器学习库,它涵盖了几乎所有的主流机器学习算法,并且提供了易于使用的python接口。本论文中用到的集成学习模型有gbdt、xgboost、adaboost,这些模型在scikit-learn库都有对应的接口函数,分别为GradientBoostingRegressor、XGBRegressor以及AdaBoostRegressor。
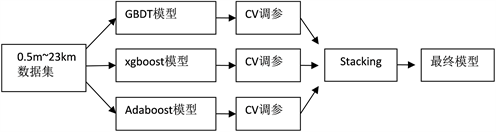
Figure 2. The flow chart of stacking model
图2. stacking融合建模的流程图
本文建模的流程图如图2所示,首先将第三节中生成的数据集划分为训练集和测试集2部分,其中训练集站70%,测试集占30%。然后利用训练集分别建立gbdt、xgboost和adaboost模型,因为预测距离属于回归问题,所以模型迭代时的损失函数为均方损失,即
(5)
在建立单模型时,采用网格搜索+5折交叉验证的方式对每个模型的参数进行调整以保证单个模型达到最优。在得到单模型后,再采用stacking的方式将所有模型融合。Stacking是由Wolpert于1992年提出的一种模型融合方法 [13] [14] [15] ,它一般由多层模型组成,将前一层模型的输出作为后一层模型的输入,最后一层的模型为最终的输出结果。Stacking的流程如图3所示。
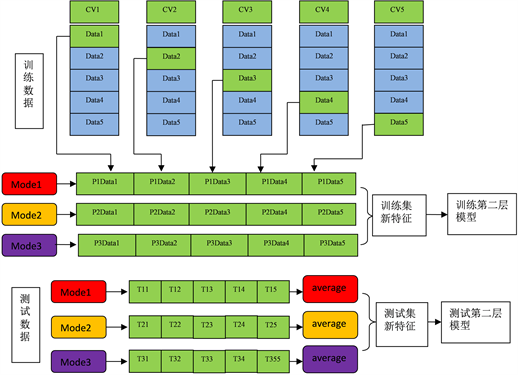
Figure 3. The schematic diagram of stacking method
图3. stacking方法原理图
首先将训练数据分成5份,分别为Data1、Data2、Data3、Data4和Data5,在cv1步骤,使用Data1作为测试集,其余四份数据作为训练集,训练Mode1,然后用Mode1预测Data1得到P1Data1,同时用Mode1预测测试数据得到T11。在cv2步骤,使用Data2作为测试集,其余四份数据作为训练集,训练Mode1,然后用Mode1预测Data2得到P1Data2,再用Mode1预测测试数据得到T12,以此类推,将每个cv的Mode1对测试集预测的结果P1Data1、P1Data2…P1Data5堆成一列作为下个模型的一个训练集特征,同时将5个cv对测试数据的预测结果T11、T12…T15取平均作为下一个模型测试集的特征。对model2和model3重复上述的步骤,可以得到下个模型测试集和训练集剩余的特征。然后用新得到的测试集和训练集训练第二层的模型,该模型的输出为最终的预测结果,本文中第二层模型选用了GBDT算法。为了与stacking融合作对比,本文还使用了average融合的方式,average融合流程如图4所示。
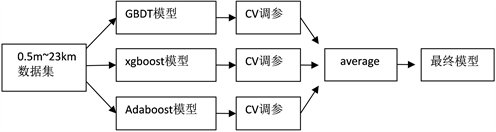
Figure 4. The flow chart of average model
图4. average融合建模的流程图
Average融合的算法相对于stacking较为简单,它只是将所有基模型的输出结果取平均后作为最终结果。
以下是按照上述方法建立的模型对中纬度夏季–乡村能见度23 km的测试数据集进行预测的结果,测试数据集总共有43,246个点,距离范围500 m~23 km。
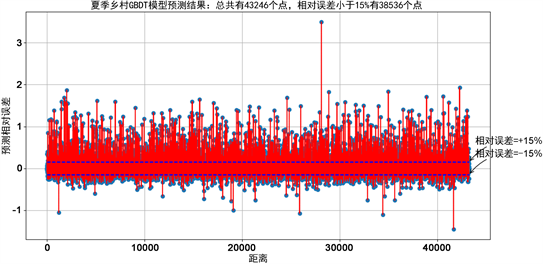
Figure 5. The error of GBDT model
图5. 使用单GBDT模型预测误差
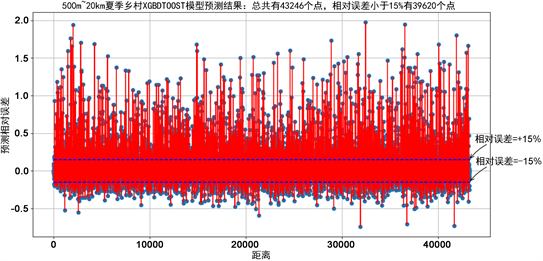
Figure 6. The error of xgboost model
图6. 使用单xgboost模型预测误差
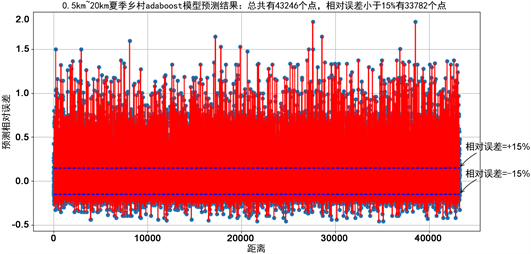
Figure 7. The error of adaboost model
图7. 使用单adaboost模型预测误差
Figure 8. The error of stacking model
图8. 将三种模型stacking融合的预测结果
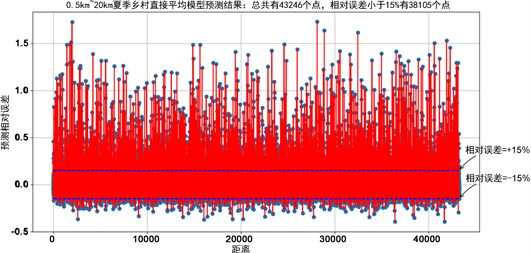
Figure 9. The error of average model
图9. 将三种模型average融合的预测结果
上面的图5~9为分别采用单gbdt、单xgboost、单adaboost、stacking融合以及average融合的预测误差,纵轴表示的是相对误差。从图中可以看出,在单模型预测中,xgboost的预测正确率最高,其次是GBDT模型,但GBDT模型预测的方差较大,采用average融合的错误率可能高于单个模型,但average的模型预测的数据比较稳定,而采用stacking融合预测的结果是所有模型中准确率最高的。
Table 2. The statistical characteristics of the five models’ predicting error
表2. 5种模型的预测误差统计表
其中Error:相对误差小于15%的点所占比例,Mean:所有测试数据相对误差均值;Median:所有测试数据相对误差中位数;Var:所有测试数据相对误差的方差。
表2为5种模型预测相对误差的统计特性,从表中能看出stacking模型的错误率和方差都是最小的,这说明该模型的准确率和稳定性都比较好,其次是xgboost模型,averge融合和adaboost预测的错误率较高,但预测较为稳定,该结论从下面的误差分布图也能看出来。
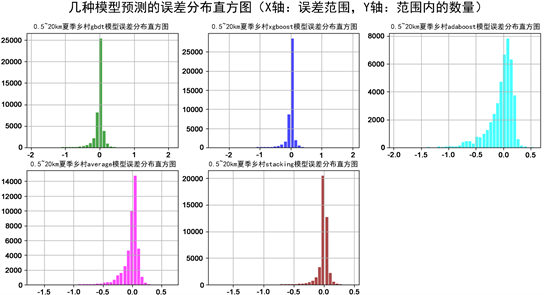 231:单gbdt模型预测误差分布;232:单xgboost模型预测误差分布;233:单adaboost预测误差分布;233:average融合的误差分布;234:stacking融合的误差分布。
231:单gbdt模型预测误差分布;232:单xgboost模型预测误差分布;233:单adaboost预测误差分布;233:average融合的误差分布;234:stacking融合的误差分布。
Figure 10. The histogram of the five models’ predicting error
图10. 几种模型的预测误差分布图
从图10可以看出,adaboost和average模型融合的误差范围比较集中,这说明预测较为稳定,但误差较低时对应的样本数量不多,所以错误率较高。Xboost和GBDT模型的正确率较高,但误差分布范围较大,而stacking融合模型的误差分布范围小,而且正确率很高。
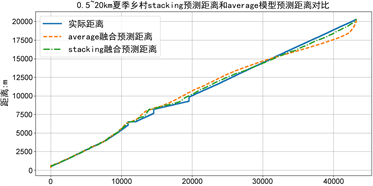
Figure 11. The comparison of stacking and average model
图11. average和stacking融合的预测距离对比
从图11可以看出,stacking预测的结果更加接近真实的距离值。
6. 结论
本文首先用MODTRAN生成了不同季节和能见度条件下的大气透过率和距离数据,然后结合红外辐射传输理论利将这些数据转换为不同距离下双波段探测器的输出电压,然后用这些数据分别建立了GBDT和xgboost以及adaboost集成学习测距模型,并对模型参数进行优化,最后通过stacking的方法将3种模型融合起来,实现了更高精度的预测,并与average融合结果作了对比,该方法具有一定的理论和实用价值。但本文的训练数据是通过软件生成的理想数据,在计算时没有考虑探测系统的噪声和背景干扰,而在实际应用过程中,一方面传感器测得的数据可能包含着噪声等因素,需要在现场进行标定,重新计算模型参数,另一方面为了提升模型的精度,需要建立更加精确的数据库。
NOTES
*通讯作者。