1. 引言
人类生产活动导致的温室气体排放,特别是化石燃料燃烧所产生的碳排放是导致全球气候上升的主要原因 [1]。工业生产活动当中产生的大量的碳使得碳排放问题显得尤为突出 [2]。如今,与碳排放相关的研究层出不穷,包括碳成本 [3] 、碳排放量计算 [4] 以及碳交易市场 [5] 等,但对于具体的某工业生产过程的碳排放研究却寥寥无几。实际上对碳排放量的准确预测能合理使用碳排放设备,提高经济效益,节能减排。而对矿山企业来说,以采矿过程为主,因而将其作为研究重点。
Xiuli Liu等用灰色预测与神经网络反向传播的组合预测模型来预测西班牙经济部门的能源消费 [6],但并未对研究对象的影响因素进行具体的分析,从而会影响预测精度。张俊深等用GM(1,1)与BP神经网络的组合模型对能源消费进行预测 [7],因其研究范围为国家级大地区,该方法不适用于局部地区,其预测效果不理想。Rigoberto等用环境库兹涅茨曲线和物流增长模型对碳排放量进行了预测 [8],但长期预测对于矿山企业不具有实际价值,且该方法在短期预测上无法得到满意的预测效果。
高斯过程回归(GPR)是一种基于贝叶斯框架的非参数概率预测的机器学习方法,适用于高维度、小样本、非线性的复杂时间序列问题 [9]。在建模过程中,协方差函数的超参数将直接影响模型的精度,因而研究如何优化确定超参数是十分有价值的。Dongdong Kong等利用共轭梯度法对高斯过程回归模型中的超参数进行优化确定 [10],但该方法依赖于初始点,且难以确定迭代次数因而其超参数优化确定的结果不理想。Debin Fang等在高斯过程回归模型的超参数优化确定中应用了粒子群算法 [11]。但由于该算法很大程度上取决于控制参数,因而精度不高,从而影响模型的预测效果。甘迪等将遗传算法引入到高斯过程回归模型中实现超参数优化确定 [12],由于遗传算法没有保持种群的多样性,因而容易陷入局部最优,影响模型性能。为了解决以上问题,本文提出了一种基于精英策略的非支配排序遗传算法(NSGAII)的高斯过程回归(GPR)预测模型,NSGAII算法不仅能够保证种群的多样性,还能在降低计算复杂度的同时提高种族质量,将上一代的优秀个体遗传到下一代,增加全局最优的搜索能力后得到最优超参数,结合高斯过程回归模型进而得到了预测精度更高的预测模型,使得模型更具有可靠性,形成一种新的采矿过程碳排放量预测方法。
2. 采矿过程碳排放量影响因素分析
采矿过程可概括为爆破、提升、通风、排水及压风。所涉及的碳排放设备包括提升机、风机、水泵及其附属设备等。根据调研结果可得采矿过程的碳排放设备的能耗主要来源为电机的电耗,因此要对具体的生产过程中电机的启停状况进行具体分析,进而得到碳排放量的影响因素。采矿简化流程如图1所示:
通过对采矿流程的分析后,可以得出以下几点碳排放量的影响因素:
1) 爆破时长:爆破会使得设备的电机停转,减少电机耗电量,因而减少碳排放量,此过程也是采矿过程的特殊所在。
2) 工作时长:各个生产设备的工作时长的不同,使得电机的耗电量有所不同,会对碳排放量产生影响。
3) 产量:采掘的矿石总产量的大小意味着生产设备的电机电耗不同,从而对碳排放量产生影响。
4) 检修时长:检修期间会使生产设备停产,表明其耗电量减少而导致碳排放量有所下降。
5) 碳排放系数:本文定义碳排放系数为总耗电量与总产量的比值,即碳排放系数=总耗电量/总产量,表示生产单位矿石所消耗的电量。在总产量一定的情况下该系数越小,碳排放量越小。
2.1. 碳排放量影响因素聚类分析
由于考虑过多的影响因素会给后续预测的建模带来较大的困难,因此要对上述影响因素进行聚类分析。通过对影响因素的分析可得,工作时长,爆破时长以及检修时长均为同类因素,因此对此三种影响因素可以进行聚类分析。本文采取的是灰色聚类分析,其主要是用于同类因素的合并,从而简化复杂问题,删减不必要的因素 [13]。建立上述三个影响因素的指标关联矩阵如表1所示:

Table 1. The incidence matrix table of the influencing factors
表1. 影响因素的关联矩阵表
由指标关联矩阵可以得出:根据具体要求选取临界值为0.7,可以将检修时长与工作时长归为一类,爆破时长归为另一类。
2.2. 碳排放量影响因素相关性分析
为了了解各影响因素对碳排放量的影响是否显著,本文采用灰色关联性分析来对各影响因素的显著性进行定量分析。由于数据样本的大小对灰色关联性分析结果影响不大,并且计算量相对较小,更具便捷性,其量化结果一般与定性结果一致 [14]。因此采用此方法进行相关性分析较为合适。通过灰色相关性的计算公式得到相关性分析的结果来选取相对显著的影响因素,并进行建模。灰色相关性分析结果如表2所示:
Table 2. Correlation analysis results
表2. 相关性分析结果
综合关联度既包含了两者的相似程度与变化速率的相近度,能够更加全面的表示序列之间的联系。在临界值为0.7的条件下,结合影响因素的聚类结果及相关性分析的综合关联度大小可以得到三个主要影响因素:工作时长,碳排放系数,产量。将主要影响因素作为输入,以碳排放量作为输出建立改进的高斯过程回归预测模型。
3. NSGAII -GPR预测模型
3.1. GPR高斯过程回归模型
对于一个给定的训练数据集D以及n个观测值,
,其中
是维数为D的输入向量,记为
,
是目标输出即因变量,记为
,问题可描述为根据给定集合D,预测出在新的输入
下所得到的输出
,即通过归纳法得到可以进行预测的函数关系f。高斯过程可以用均值函数和协方差函数表示 [15]。根据高斯过程的相关定义可以得到
,服从高斯分布,且其联合分布同样也服从概率分布,可记为:
(1)
其中
(2)
为均值函数
(3)
为协方差函数。而在实际应用中需考虑高斯噪声
,
相对于
完全独立。由贝叶斯概率理论,在给定训练数据集
中建立起先验分布函数,因此可得加入噪声后的训练输出分布为
(4)
其中,I为
的单位矩阵,
为Gram矩阵,矩阵元素为
,协差矩阵
(5)
训练数据集
和测试集
的联合分布如下所示
(6)
此时可得到后验分布。根据贝叶斯概率公式可以得到高斯过程回归的预测方程为:
(7)
(8)
(9)
其中
为预测方程的均值,即为高斯过程回归的输出预测值,
为高斯过程回归的方差。由于平方指数(SE)函数的强光滑性与电机对象的拟合度并不高,相较之下M5/2函数的光滑性在以电机为研究对象的物理过程建模中更具有现实意义,因而选用M5/2为协方差函数,其表达式为
(10)
其边缘似然函数可由先验分布表示为
(11)
其中
为超参数集合。先验分布取对数后可得
(12)
对式(12)求偏导可得
(13)
,其中tr表示矩阵对角线元素之和。
3.2. NSGAII带精英策略的非支配排序遗传算法
非支配排序遗传算法(NSGA)是在传统的遗传算法上演变而来的,主要是在选择之前对种群进行了分层,其分层的依据为个体之间的支配关系。
对于极大化目标优化问题,f(X)为目标函数,X,X'均属于解集U,若X支配X' [16],则同时满足以下条件:
。
带精英策略的非支配排序遗传算法(NSGAII)是一种以Pareto最优为基准的遗传算法 [17],是在NSGA的基础上对种群的分层进行进一步改进,将上一代的优秀个体遗传到下一代,从而保证种群的质量,增加全局最优的搜索能力。除此以外,提出拥挤度的概念来代替NSGA中的共享半径,提高了计算效率,更快的收敛到最优 [18]。将拥挤度定义为在种群中给定个体的周围密度,通常用id表示拥挤度,其表示包含个体i本身但不包含其他个体的最小正方形的大小 [19]。NSGAII算法具体的流程如下:
1) 随机产生初始种群P0,大小为M,计算目标函数值并按照支配定义对于P0中的每一个个体进行非支配排序分层得到P1。
2) 对非支配排序分层后的每层种群个体进行拥挤度计算。
3) 通过选择、交叉、变异等基本遗传算法步骤后得到子代S1,大小为M。
4) 将第i代产生的Si与Pi组合为Ai,大小为2M。此时对组合集Ai进行非支配排序并计算拥挤度。将排序后的第一层子集即父代与子代中最好的个体优先放入Pi + 1中,若第一层子集大小小于M,则将下一层子集向Pi + 1中充填,当子集大小大于M时,则再依据拥挤度大小选择较不拥挤即id大的个体充填,直到Pi + 1大小为M停止。
5) 得到Pi + 1后重复上述步骤,直到满足终止条件后结束。NSGAII的流程示意图如图2所示 [20] :
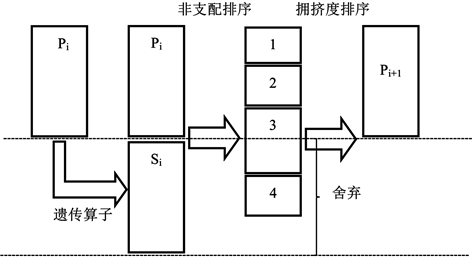
Figure 2. NSGAII process schematic
图2. NSGAII 的流程示意图
3.3. NSGAII-GPR预测模型
对于高斯过程回归模型,协方差函数的超参数将直接影响模型的精度。因此在确定了协方差函数的表达式后,需要对方程中的超参数进行优化确定,本文采用NSGAII进行参数的优化确定,算法的具体流程如下:
1) 对样本数据初始化处理,即将所采集的数据分为两部分,一部分为训练集
,另一部分为测试集
。
2) 根据高斯过程回归的理论知识及已确定的协方差函数M5/2,用训练集
初步构建相应的预测方程。
3) 预测方程的超参数优化确定,根据目标函数式(12)执行NSGAII算法流程。
4) 将测试集
中
作为输入,输出值
,将每种预测结果与测试值
做比较。具体的算法流程图如下所示:
4. 模型验证
本文采集了某大型铅锌矿山企业的采矿部门近32个月的数据,通过影响因素分析后整理出32组样本数据如下表所示,并将前26组数据作为训练集,后6组数据作为测试集对模型进行验证。原始数据如表3所示。
根据表中数据,将产量、碳排放系数与工作时长作为模型的输入,由于在实际运用中对于碳排放量的直接测量相对困难,所以采用耗电量与碳排放量的换算公式来计算得到实际的碳排放量数据。在本实验中将耗电量作为采集的原始数据,将换算公式计算后得到的碳排放量作为模型的输出,并与测试值作比较得到误差大小。为了验证该模型的可靠性,本文采用共轭梯度法、粒子群算法及遗传算法三种常用的超参数优化确定方法进行建模,其预测结果如图4所示。
根据表4与图4进行分析可得,相较于其他的超参数优化确定方法,带精英策略的非支配排序遗传算法(NSGAII)有着明显的优势,基于NSGAII的高斯过程回归模型能够将预测误差降低到6.3%,能够获得较为理想的预测结果。
为了进一步验证改进的高斯过程回归预测模型的可靠性,本文将选取灰色预测模型GM(1, 1),支持向量机SVM以及人工神经网络三种常用的预测模型来进行实验对比。其对比实验结果如表5所示。
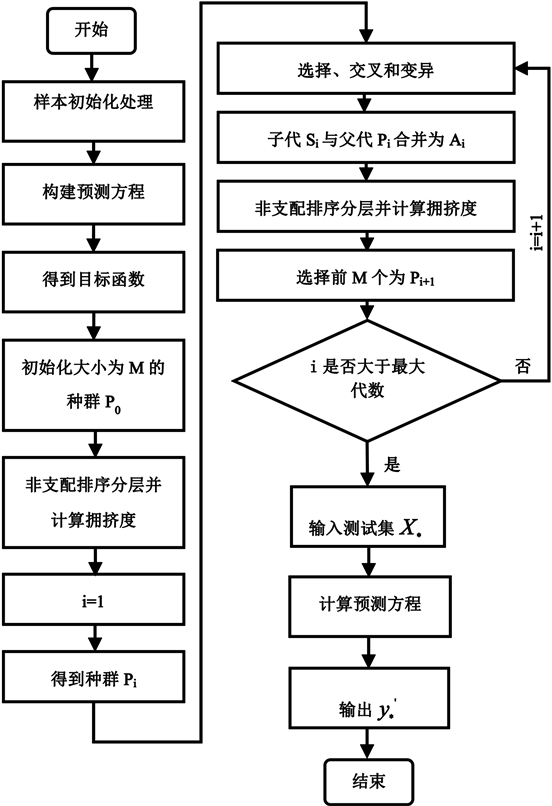
Figure 3. Process schematic of the NSGAI-GPR prediction model
图3. NSGAII -GPR预测模型的流程示意图
Table 3. Raw data of mining process
表3. 采矿过程原始数据
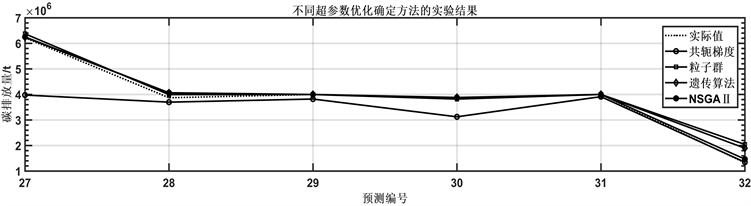
Figure 4. Experimental results of different super parameter optimization methods
图4. 不同超参数优化确定方法的实验结果
Table 4. Experimental results of different super parameter optimization methods
表4.不同超参数优化确定方法的实验结果
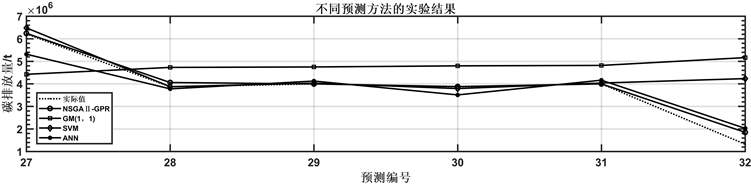
Figure 5. Experimental results of different prediction methods
图5. 不同预测方法的实验结果
分析上述实验结果可知,用NSGAII-GPR模型进行预测大型铅锌矿山企业的采矿过程碳排放量的均误差为6.3%,相较于其他常用的预测模型有着明显的优势,其预测精度更高,误差更小。因此相较于其他常规模型,该模型更加可靠,模型性能更好。
Table 5. Experimental results of different prediction methods
表5. 不同预测方法的实验结果
5. 结束语
本文采用了高斯过程回归模型,并在此基础上对超参数的优化确定进行了改进,进而得到NSGAII-GPR模型,从实验结果来看,NSGAII-GPR模型有着较高的预测精度,能够很好地预测采矿过程的碳排放量。为企业进行碳排放量的计划和管理提供了有效的帮助,能更好的进行企业规划及生产设备调度与工况选择,带来更高的经济效益,积极响应国家政策,达到节能减排的目的。