1. 引言
油气产量预测是油气田制定长期规划的主要依据。由于影响油气产量的因素众多,这给建立理论模型带来一定的困难。根据系统分析的原理,利用生产数据进行建模预测是目前被广泛采用的方法,其中选择科学合理的模型是研究的重点。在20世纪90年代及以前,就已经提出了多种预测模型,例如Arps模型 [1] 、翁氏模型 [2] 、t模型 [3] 、Weibull模型、贝塔旋回模型 [4] 、HCZ模型、伽马旋回模型等一系列模型。但目前在现场应用最广的仍是Arps模型 [5] [6] [7]。但Arps模型选择标准曲线受主观因素影响大,尤其对于非光滑序列,选择初始递减率和递减指数困难,误差大。随着计算机技术的发展,智能算法也逐渐被用来预测油气产量,例如神经网络算法、遗传算法等 [8] [9] [10]。但智能算法需要样本量大,对于少数据的情况难以推广应用。
油气田产量影响因素错综复杂,因此油气生产系统可以看成一个不确定系统。针对该系统“小样本”、“贫信息”的特征,灰色预测模型也在产量预测中得到广泛应用。相对GM(1,1)模型,GM(1,1)幂模型可以满足更多形状序列的模拟 [11]。笔者在分析Arps产量递减模型的基础上,采用GM(1,1)幂模型进行油气产量和产量递减率预测,取得了很好的效果。
2. Arps产量递减模型
Arps产量递减模型是目前应用最广的一种模型,该模型形式如下:
(1)
式中:a、
分别为时间t和初始时刻的产量递减率,mon−1或a−1,表示单位时间内产量的变化率。定义式为:
(2)
式中:Q、
分别为时间t和初始时刻的产量,单位是t/mon或t/a;n为递减指数,当
时称为指数递减;当
时称为调和递减;当
时称为产量衰减;当
且
时称为双曲递减。该次研究不考虑指数递减,即取
。
联立式(1)和式(2)可以得到:
(3)
取递减初始条件,
时
,则可以得到产量和递减率随时间变化的公式:
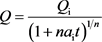 (4)
(4)
(5)
如果令
,
,则式(3)可以写为:
(6)
3. GM(1,1)幂模型
设
为原始产量序列,
,
;
为
的一次累减生成序列,其中
,
。
为
的均值生成序列,
,其中
,则称:
(7)
为GM(1,1)幂模型。
根据最小二乘法,GM(1,1)幂模型的参数可按下式求解:
(8)
其中:
(
),
,
。
GM(1,1)幂模型的白化方程为:
(9)
根据式(6)和式(9)可以看出,Arps产量递减模型也是幂模型,是GM(1,1)幂模型在
时的特例。
GM(1,1)幂模型白化方程的通解为:
(10)
式中:C为任意常数。取递减初始条件,
时
可以得到产量随时间变化公式:
(11)
根据式(2)和式(10)可以得到:
(12)
将式(11)代入式(12)即可得到GM(1,1)幂模型的产量递减率随时间的变化公式:
(13)
4. 模型的求解方法
不同油田产量的递减规律不同,表现在初始递减率
和递减指数n不同,而又主要取决于n的变化情况。影响n的因素很多,如岩石性质、驱动方式、地质条件以及开采方式等,所以n变化范围很广,其选择和应用都比较麻烦。Arps产量递减模型采用标准曲线对比法求解
和n,受主观影响大,误差大,尤其对于不规则序列,难以选择标准曲线。GM(1,1)幂模型可以满足多种形状序列的模拟,这主要取决于A、B和m的大小,但同样存在m求解难的问题。笔者通过构建最优化模型,利用智能算法求解m。
油田产量递减规律一般是随着时间推移,产量递减变慢,最后趋近于0。根据GM(1,1)幂模型的性质,进行产量递减预测时应有
、
。由式(7),参数A、B可以看成m的函数,即
,构建相对误差函数,建立以相对误差最小为目标的优化模型:
(14)
式中:
,
为预测值。
粒子群算法由于理论计算简单,收敛速度快而得到广泛应用。采用文献 [12] 提出的多种群多极值粒子群算法进行求解。
由于GM(1,1)幂模型和Arps产量递减模型形式不同,A、B和m只代表一个数值,没有实际意义,所以不能直接采用
和
计算Arps模型中的初始递减率
和递减指数n。对于初始递减率,
正确的求解方法是根据式(12),取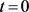 进行求解。在GM(1,1)幂模型中没有递减指数的概念。
进行求解。在GM(1,1)幂模型中没有递减指数的概念。
5. 实例分析
取文献 [1] 中某油田在生产后期的产量数据(表1)。文献 [1] 将产量变化曲线与标准图版对比,确定递减指数
、初始递减率
,从而得到产量和递减率随时间变化的关系分别为:
采用GM(1,1)幂模型求解,得到
、
、
,从而得到产量和递减率随时间变化的关系分别为:
预测结果见表1。

Table 1. The results of model prediction (data taken from reference [1] )
表1. 模型预测结果(数据来自文献 [1] )
*样本平均相对误差是根据式(14)计算得到,即
。
从表1中的结果可以看出,相对Arps产量递减模型,GM(1,1)幂模型相对误差小,建模精度高。另外计算时发现在
、
和
、
两个区域,也可以达到很高的建模精度,但是根据长期预测,产量趋近于
,不符合现场实际。主要原因是样本数据点少,贫信息,只能反映中、短期产量变化规律。对于长期预测,则需要更多的数据点。这也同时说明任何模型的建立,都必须以实际规律为基础。
6. 结论
1) GM(1,1)幂模型适合少样本、贫信息的不确定系统,能满足多种形状序列的建模。同时GM(1,1)幂模型与Arps产量递减模型在形式上存在共性,可以用来预测油气产量,建模精度高。
2) 在油田现场,受各种因素的影响,测试的数据带有一定的“噪声”,因此在建模过程中,不仅要追求建模精度,更要分析模型是否能反映实际生产规律。尤其是长期预测,要随时用最新的测试点更新模型。