1. 引言
近几年来线性回归模型以其简洁易于分析的优点受到研究者们的青睐,最典型的线性回归模型为
,或者等价于
,
其中
是
维响应变量,
是
的设计矩阵,
是
维参数向量和,
是
维独立同分布的随机误差向量。线性回归模型简单来说是一种因素与另外多种因素的依存关系,尤其是在分析多因素的情况下,线性回归模型会显得更加简单和方便。同时线性回归分析可以准确地计量各个因素之间的相关程度与回归拟合程度的高低,提高预测方程式的效果;而实际上一个变量仅受单个因素影响的情况极少,多为多因素影响,尤其在经济,生物等领域,所以通常使用多元线性回归对实际问题进行分析。
对于多元线性回归问题,选取一个适合的模型对数据的分析起着至关重要的作用,全模型的估计结果固然比较好,但对于变量比较多的情况下,全模型就会显得繁琐产生过度拟合的情况,因此在这种情况下,为了后续工作的快速有效进行变量选择是很有必要的,尤其在商业和生物学等领域,人们不得不越来越频繁的处理高维问题,这就使对有效的变量选择产生了巨大的需求。
对于高维线性回归,最小二乘的惩罚方法通过约束模型的回归系数进行变量选择,在过去十年中该方法已经得到广泛发展。从1970年Hoerl和Kennard [1] 提出的岭回归到1996年Tibshirani [2] 将岭回归估计中的L2范数罚正则项替换成L1范数罚正则项得到了The Least Absolute Shrinkage and Selection Operator (LASSO)这一变量选择方法,后来2001年Fan和Li [3] 提出了Smoothly Clipped Absolute Deviation (SCAD)的变量选择方法。自从变量选择的过程被提出后,许多研究者们对其进行了深入的研究总结,Luo和Chen [4] 于2008年对The Extended Bayesian Information Criterion (EBIC)进一步详细阐释,之后在变量选择这一方面还做了大量研究,使其发展渐趋成熟,如Cho和Fryzlewicz (2011)等 [5] [6] [7] ,Zhang K,Yin F,Xiong S [8] 对带有惩罚因子的模型选择做了简单的总结,白玥和田茂再 [9] 于2017年对LASSO、SCAD等方法做了对比,进行了有无分组的讨论。与此同时,为了选出最优模型,运用贝叶斯思想方法进行了贝叶斯模型选择 [10] 研究,在模型先验信息已经得到的情况下,根据其思想可以准确算得模型的后验概率,这也就得到了每一模型的概率,利用贝叶斯因子便能选出概率相对较大的模型以此作为最优模型。
而稀疏模型近几年来在机器学习和图像处理等领域发挥着越来越重要的作用,它具有变量选择的功能,可以解决建模中的过拟合等问题。稀疏模型可以将大量的冗余变量去除,只保留与响应变量相关性最大的解释变量,不仅简化了模型而且还保留了数据集中最重要的信息,有效解决了高维数据及建模中的诸多问题。同时,稀疏模型具有更好的解释性,便于数据可视化、减少计算量等优点被大量使用。
本文主要基于稀疏性较强的线性回归模型,对多种模型选择方法做一模拟比较,文章第二部分主要介绍惩罚因子模型选择方法,第三部分则主要介绍贝叶斯模型选择方法,第四部分主要进行数据模拟对多种方法进行对比,第五部分则主要进行实例分析。
2. 惩罚因子模型选择
模型选择是统计领域中的前沿问题,以线性回归模型为基础对多种模型选择方法做一简单介绍。考虑线性回归模型
(1)
其中
是
维响应变量,
是
的设计矩阵,
是
维参数向量和,
是
维独立同分布的随机误差向量。
用最小二乘的方法得到参数
的估计值为
(2)
对于线性模型而言,变量选择即是模型选择,对于传统的变量则方法有Lasso,岭回归和SCAD等方法,由于变量的个数较多,对后面的计算产生很大影响,所以运用这些方法进行变量选择是很有必要的,而这些传统的变量选择方法都是基于增加惩罚项的思想进行运算的。
惩罚因子法是目前比较流行的模型选择的方法,且运作效率较高,可以同时做到变量选择和参数估计,在参数估计时惩罚因子法可以通过压缩部分系数为零来实现模型选择。这部分主要介绍惩罚最小二乘实现模型选择,即实现下式最小化
(3)
其中
为惩罚项,
为调整参数,惩罚项
的选取不一样则出现了多种模型选择方法。
2.1. 岭回归
岭回归是Hoerl和Kennard [1] 提出的,主要解决变量之间多重共线性的问题,如果变量之间存在多重共线性,则岭回归提供了一种较为稳定的方法,改进了最小二乘方法。
由于线性回归模型中自变量可能存在着多重共线性的问题,所以最小二乘方法所估计的参数
不是很稳定,岭回归则给
加了一个正常数矩阵
,这样
接近奇异性的程度就会比
要轻的多,由此便得到了岭回归的参数估计
(4)
这一估计还等价于以下优化问题,通过利用
惩罚函数来改进最小二乘估计,得到参数的估计
(5)
其中
为调整参数,
是
的单位矩阵;而调整参数
主要通过最小化GCV准则得到
(6)
其中
;调整参数 也可以通过岭迹图对调整参数进行选择,这种方法存在较强的主观因素。虽然岭回归得到参数估计
是
的有偏估计,但一定程度上解决了变量之间的多重共线性的问题。
也可以通过岭迹图对调整参数进行选择,这种方法存在较强的主观因素。虽然岭回归得到参数估计
是
的有偏估计,但一定程度上解决了变量之间的多重共线性的问题。
2.2. LASSO方法
LASSO方法是Tibshirani [2] 在The nonnegative garrote (NG) [11] 方法的基础上发展而来的,也是岭回归的一特殊形式。对于NG方法,其参数估计为
(7)
这里的
为非负向量,是下面二次凸优化的解
(8)
其中
,
是参数最小二乘的估计值,
为调整参数。
而LASSO方法的思想与NG方法类似,都是将部分系数进行压缩到零来实现模型选择。LASSO是在
的约束下进行的参数估计,等价于添加
惩罚函数优化以下函数得到参数估计,即
(9)
其中
为调整参数,通常是通过十折交叉验证的方法选择。
相比于岭回归来说,LASSO方法对重要变量的系数压缩较轻,提高了参数估计的准确性。LASSO方法计算复杂度较小,具有参数估计的连续性和渐近正态性这一良好的oracle性质 [12] 。
2.3. SCAD方法
SCAD [3] 方法是由Fan和Li (2001)提出的,其惩罚函数是对称且非凹的
(10)
其中
是惩罚项,其一阶导数为:
(11)
通过数值模拟和实证分析等方法,Fan和Li建议
取3.7,调整参数
则通过CV方法取得最优值。
Fan和Li (2001)的文章提出SCAD方法也具有良好的oracle性质:1) 稀疏性:模型选择的结果将一些不重要的变量系数变为零或真模型中变量系数为零的经过选择之后其估计值接近于零;2) 渐近正态性:模型选择后的参数估计渐近服从正态分布。而且SCAD方法较岭回归方法而言,减少了选择模型的预测方差,较Lasso方法而言,减轻了过度压缩系数的情况,减少了参数估计的偏差。
3. 贝叶斯模型选择
除了通过利用惩罚因子来压缩系数的方法进行模型选择外,还可通过计算模型的概率,由概率的大小进行模型选择,贝叶斯模型选择便是利用这一点。
同样对于上述线性回归模型,含有
个预测因子
,为了进行模型选择,我们首先利用二进制变量进行理解。令
为
维二进制变量,其中
为示性变量,如果变量
被选入模型中则
,否则
。根据不同变量的选入情况,只利用被选入变量做简单的线性回归,由此可知整个模型空间有
种可能的选择,得到每一模型的概率。
对于模型概率的计算,其关键即为得到模型的后验概率,在数据
给定的情况下,得到模型后验概率
(12)
这里
是模型
的边缘似然概率,
是模型中的参数,
是
在模型
条件下的先验密度函数,
是似然概率,
是模型
的先验概率。将比值
定义为贝叶斯因子,通过贝叶斯因子可以快速的找到概率最大的模型,这一模型就是贝叶斯模型选择的结果,即
(13)
为了进一步研究分析模型选择的结果,将对多种模型选择的方法进行比较研究,其具体分析将在第四部分数据模拟中加以说明。
4. 数据模拟
这一部分将以多元线性回归为基础,对带有惩罚因子的多种模型选择与贝叶斯模型选择方法在不同情况下进行模拟对比,主要研究模型选择在稀疏模型下的情况。
模拟1:对于线性回归模型
(14)
给出8个预测因子,即
,并且每个变量数据均由正态分布产生,即
,而这里正态分布里面的方差矩阵S的第
个和第
个的相关系数取
,此次模拟中回归系数选择为
,而
的选择是从0.1变化到0.9。
根据样本容量
和随机误差服从正态分布中的方差
的取值不同,分成四种情况进行模拟:情况一:
;情况二:
;情况三:
;情况四:
。对于每种情况,我们重复进行1000次试验,且最后结果由模型损失Model Error (ME)
来表现,为了便于观测结果,将对模型损失取对数进行观测,图1是此次模拟的结果。
模拟1结果表明:由于岭回归根据GCV选取
后将全部变量选入,岭回归的模型损失最小。其次是SCAD方法,并且
的不同对结果影响不太大。当
较小时,SCAD和LASSO方法相差不大,但当
较大时SCAD方法优于LASSO。这说明SCAD方法与岭回归结果相差甚小,且可以较好的将不重要的参数去除掉,具有良好的稀疏性性质,减少了后期计算量。
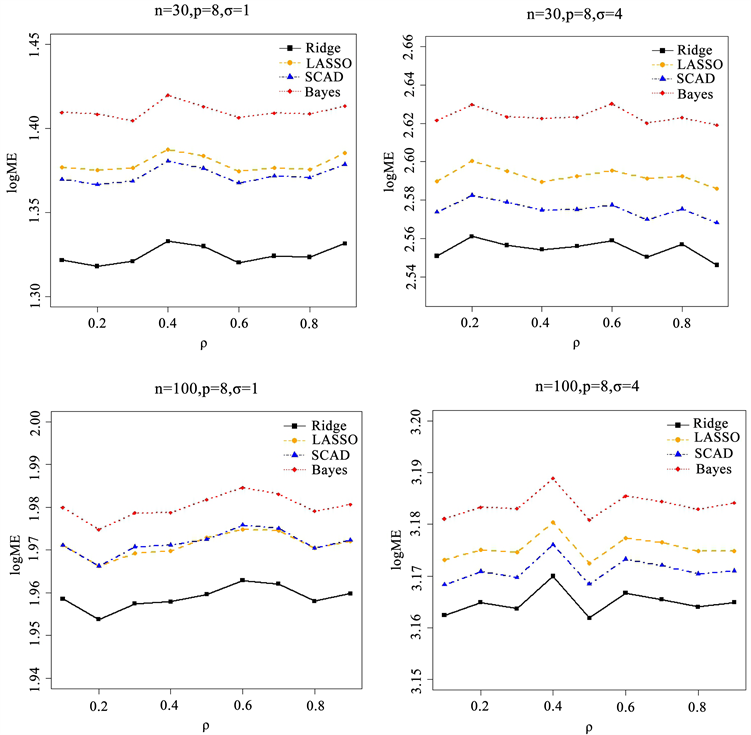
Figure 1. Variation of different correlation coefficients under sparse models
图1. 稀疏模型下不同相关系数变化情况
模拟2:继续沿用模拟1中的线性模型
此次模拟我们主要考虑系数稀疏性不强,但有一些接近于0的情况。这里取
,分别对
和
这两种情形下观察
的变化情况变量系数设置为
,其中
从0变化到1.5,其他设置与模拟1相同。而结果在图2中展现。
由模拟2可以看出模拟结果虽然与模拟1类似,但是
的大小对结果有影响。当
和
均较大时,随着
的增加,SCAD模型损失越来越小,而且模型损失也接近全模型的模型损失。这说明对于随机误差和回归变量的相关性加强,SCAD方法不但能够较为准确的选取重要变量,将不重要的变量去除掉,而且损失也小于其他的惩罚方法。SCAD的优势更为明显,它不但可以较好的将不重要的参数去除掉。
5. 实例分析
这一部分我们主要对麦考斯 [13] 等的著作中采用的内膜—中膜厚度及其影响因素的数据集进行分析,这一数据是法国波尔多地区的多家医院于1999年利用超声技术对受试者进行的测量,收集了一些主要风险因素信息。这一数据中含有8个预测因子,即
,110个观测值,其中内膜—中膜厚度(measure)作为响应变量
,令
表示为会诊时的年龄(AGE),体重(weight)等8个预测因子,由此可以得到响应变量与预测因子之间的关系
而模型选择的目的就是为了选出最优模型,最终进行预测,使预测的结果更为准确。为了达到我们的目的,所以这里选用前100个观测值为训练集,即
,后10个观测值为测试集,以此分析不同模型选择方法之间的差异。
此次结果放在下面两表中,其中表1为各个预测因子之间的相关系数,表2是对内膜—中膜厚度数据分析结果的总结。由表1可以看出部分变量之间存在很强的相关关系,变量之间存在共线性问题,由此我们可以看出对婴儿出生体重的影响虽然由8个预测因子影响,但是数据特征信息主要集中在几个变量上,进而就可以简化模型,减少计算量。从表2中可以看出岭回归和SCAD方法在此稀疏模型中表现良好,但SCAD可以较好的去除不重要变量,贝叶斯模型选择则过度筛选变量,造成信息丢失的情况,总体来看SCAD方法与岭回归得到的全模型的预测结果相差较小。
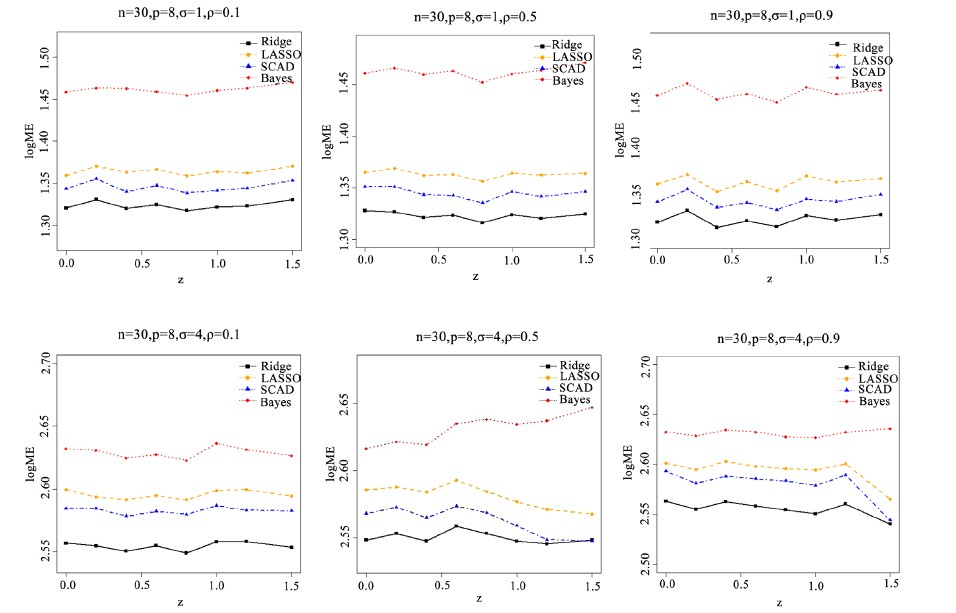
Figure 2. Coefficient variations in almost sparse models under different conditions
图2. 几乎稀疏模型不同情形下系数变化情况

Table 1. Correlation coefficient matrix of prediction factors
表1. 各预测因子之间的相关系数矩阵
Table 2. Analysis of intima-media thickness data
表2. 内膜–膜中厚度数据分析
6. 总结
本文主要对带有惩罚因子的岭回归、LASSO、SCAD三种模型选择和贝叶斯模型选择进行了简单的介绍,并通过数据模拟和实例分析对多种方法进行了对比分析,得到在稀疏模型的前提下,岭回归表现较好,SCAD可以较好地去除不重要变量。而本文主要基于线性回归模型进行研究,所以后面主要工作可以对其他更为复杂的模型进行研究。