1. 引言
复杂网络研究是众多科学领域的一个重要分支,大量的学者致力于研究网络的特征、演化过程、拓扑结构与功能之间的关系。其中,社会网络分析近年来成为复杂网络分析中一个新的非常重要的研究方向,尤其随着多种社交媒体的产生与发展繁盛,社会网络分析对于研究事件演化、信息推荐、舆情管控等都具有重要的作用。社会网络中的链接预测主要是通过网络的已知信息,预测没有链接的两个节点发生链接的可能性,这种链接关系可能是已经存在但尚未被发现的,也可能是目前不存在,但是在不久的将来非常可能发生的。社会网络实体之间的关系分析对事件发展具有极其重要的作用,因而链接预测在现实世界中具有非常广泛的应用性,比如社交网络中的好友推荐,电商中的商品推荐,社会安全中的实体识别等等。
链接预测作为社会网络分析的一个重要研究方向,是一个交叉学科问题,涉及社会学、系统学、图形学等等,逐渐发展成为国内外学者的研究热点。经典方法都是将社会网络看作是一个节点和关系的集合,网络中的每个节点对应一个实体,每条边对应着用户之间的一种关系,链接预测就是基于这些实体和关系的特征进行。为了实现快速的关系预测,如何综合社会网络中的多维特征是研究者们一直在探索的问题。本文提出的基于多维相似度属性的社会网络链接预测算法,就是要分析社会网络中节点和边的多维相似度属性,通过机器学习的方法,实现对社会网络有效的链接预测。
2. 相关工作
对社会网络链接预测的现有研究方法主要集中在基于概率模型、基于监督学习和基于相似度三类。
基于相似性的算法是链接预测中最直接有效的方法,但是也具有很多的挑战性。比如节点相似性的定义本身就存在异议,相似性指数的分类更是复杂。相似性通常是通过两个节点之间的共同特征来衡量,共同特征越多,相似性越高,则越有可能存在链接。然而通常情况下,能够直接得到的是网络拓扑结构,节点的属性是隐藏的,纯粹基于拓扑结构的相似性指数往往是比较浅显的,因而基于结构相似性的链接预测准确率高低,往往与结构相似性所提出的指标以及目标网络所具有的拓扑特性的匹配程度相关。Lv等人曾在文 [1] 中归纳了基于网络结构相似性指标的链接预测方法,并将这些指标归类为局部信息、路径、随机游走三大类,是对链接预测相似性指标比较系统全面的分类。现在对基于相似性的链接预测方法的分类有很多种方法,大致是基于两大类特征,即节点属性和路径信息。基于节点主要是基于公共邻居的相似度指标,比如CN、Jaccard、Salton等等 [2] 。基于路径的方法则是主要考虑最短路径、随机游走 [3] 或者page rank这三类。
基于监督学习的链接预测主要是根据特征值对节点进行分类,这样链接预测就是一个典型的二分分类问题,但是这种方法的难点在于特征值的选取,通常做法是以图的拓扑结构来寻找特征值。例如Kashima、Liben等人的方法 [4] [5] 。但是如果社交网络规模较大时,特征值计算的复杂度往往也很高。后来,Doppa等人研究发现,基于节点相似性,考虑拓扑结构特征,可以很好的提高链接预测的准确度 [6] 。
虽然很多研究表明,借助于节点属性的链接预测具有比较好的效果,但是这些属性往往是被看作独立的,于是有部分研究者考虑把节点属性进行有效结合,看是否对链接预测的准确性会有提高,这就产生了基于概率模型的方法,这类方法是系统的将节点和边属性进行结合,构造出一种联合概率分布,得到结构化的数据关系。Lise和Taskar等人的研究证明,此种方法精确度较高 [7] [8] 。
目前,对链接预测的实现都是建立在对已知数据的分析之上,各种预测方法的目标都是相同的,但是分析问题的角度不同 [9] 。基于结构相似性的方法,主要考虑某个方向上的特征,如果所预测网络的特征不明显,预测结果也将不准确。但是这种方法的计算复杂度较低,具有比较好的实用基础。而基于概率模型的方法则考虑了结构信息和节点之间信息,以求达到较为完美的预测效果,这种方法的信息获取较为困难,算法复杂度也较高,在实际应用上有难度。因而本文中提出一种基于多维相似度特征的社会网络链接预测算法,以求选取能够有效融合的多种节点和路径相似性特征,采用机器学习算法,实现链接预测。
3. 相似度特征选择
基于相似性的链接预测,是根据所观察到的网络拓扑信息,构建相似性指标来进行链接预测,是目前链接预测领域的主流方法。为了选择合适的特征,避免特征越多效果越差的现象,本文从基于节点和路径的两大类属性中选择相似度特征进行链接预测。
3.1. 基于节点属性的特征选择
1) 公共邻居
(1)
计算出两个节点x,y的公共邻居节点,并以此计算x和y节点的相似度。通常我们认为两个节点的邻居集合重复度很高时,即使两者之间没有直接连接的边,也可以认为x和y很可能存在某种关系,它们建立关系的可能性很大。
2) Salton指标
(2)
这个指标又被称为余弦相似度,是在CN指标基础上加入了两个节点度的信息。
3) Sorensen指标
(3)
这个指标是在Salton指标基础上进行的改造,常常被用作生态社区数据。
4) adamic_adar指标
(4)
这个指标通过赋予少数链接的邻居更多权重,来改善公共邻居的作用。思想是每个邻居节点在相似度计算中的贡献是不同的,度小的公共邻居节点的作用比度大的节点更重要。
5) RA(resource_allocation)指标
(5)
这个指标是基于网络资源动态分配思想产生,通过计算两个节点间能够传输的资源数量来度量他们之间的相似性。
6) HPI指标
(6)
根据定义,该指标的分母是由较小的节点度决定的,因而度大的节点更容易与其他节点有较高相似性,也就是说与枢纽节点相连接的链接会被分配较高的相似度分数。
7) HDI指标
(7)
这是类似于HPI的相反效果的枢纽指标。
8) LHN指标
(8)
这个指标给有许多共同的邻居的节点对分配高相似性。但是相比较与CN系数,该系数不会无限制的变大。
9) PA (Preferential Attachment)指标
(9)
这个指标被称作优先连接机制,它忽略了网络结构信息对相似度的影响,仅仅考虑了节点的度。一个节点的度越大,也就是与其他节点产生链接多,那么这个节点将来与未连接节点产生链接的可能性越大。
10) Jaccard指标
(10)
Jaccard方法的主要思想是两个节点拥有的共同邻居占它们所有邻居节点的比例越高,那么他们未来发生联系的可能性越大。
3.2. 基于路径的特征选择
相对于基于节点的相似度特征选择,基于路径的方法需要考虑网络的整体拓扑信息,因而有两个致命的缺点:第一,计算一个全局相似度指标是非常费时的,并且在网络规模巨大时,这种计算方案是行不通的;第二,全局的拓扑信息有时是不可获取的,特别是当使用一个分散的方式来实施算法时。因此,如何选择既容易计算,并且链接预测准确率又高的相似度指标就显得尤为重要。
1) 最短距离
基于路径的方法中最简单的指标。如果两个节点之间的最短路径越短(除去直接连接的边),则它们越容易产生作用,越可能连接。
2) Katz方法
Katz是一种计算节点声望的方法。它给予短路径更高的权重,然后计算全部的加权路径和,定义为
(11)
其中,
是图中节点x和y之间所有长度为L的路径的集合,
(
)为衰减系数。 越小,则该方法越接近公共邻居算法,原因是路径越长,对和的贡献越小。
3) 本地距离
定义为
(12)
其中,ε为参数,A为邻接矩阵,如果节点x和y直接相连,则
,否则
。
4. 实验结果与分析
4.1. 实验数据集
在本实验中,数据集分为两大类:仿真数据集和真实数据集。其中,仿真数据集主要模拟了erdos_renyi模型,BA模型,随机生长模型,森林火灾模型。真实数据集则是来自斯坦福官网的SNAP数据集,包括了wiki-Vote,ca-GrQc,ca-HepTh,p2p-Gnutella08这4个数据集。原始数据txt下载后如图1所示。
由于真实的数据集数据量很大,为了使算法性能达到最佳,对数据集进行如下预处理:
1) 数据集全部作为无向图处理;
2) 将数据集的真实节点从1开始重新编号;
3) 将真实网络删去10%的边(连接边的两个节点的度至少为1,否则有的指标会产生除零异常),边数记为n,记下每条边对应的节点对,作为测试集label为1的样本。剩下的节点对全部都未连接,作为训练集label为0的样本。
4.2. 评价指标
1) 正确率:正确预测的样本数占整个样本数的比率。
2) 识别准确度
(13)
TP (True Positives):表示正确肯定的分类数。
TN (True Negatives):表示正确否定的分类数。
FP (False Positives):表示错误肯定的分类数。
FN (False Negatives):表示错误否定的分类数。
3) 识别精确率
(14)

Figure 1. Original text of the SNAP dataset
图1. SNAP数据集原始文本示意图
4) 反馈率(召回率)
(15)
5) 真正类率(灵敏度)
(16)
6) 假正类率(特异性)
(17)
7) ROC曲线
ROC曲线,是一个图形化说明二进制分类器系统的性能的工具,它的判别阈值是变化的。纵轴为灵敏度,横轴为特异性。曲线的绘制真正类率(TPR)创建对假正类率(FPR)在不同的阈值设置。该曲线下的积分面积能衡量模型的优劣,ROC下的积分面积值越接近1则该模型效果越好。以图2为例,最左侧曲线下面积明显最大,因此其分类效果最好,右侧粗线次之。如果ROC曲线下面积在1~0.85,则认为分类器表现优秀,在0.85~0.7,认为表现良好,0.7~0.5认为有待改善,小于0.5,那可以认为分类器效果比随机猜测还要差。
4.2. 验证算法
本文将链接预测问题转化为一个分类问题来求解,使用的分类算法包括:最近邻节点算法(KNN)、朴素贝叶斯(NaiveBayes)、多层感知器神经网络(MLP)、支持向量机(SVM)、决策树(DT),依次来验证所选择特征的有效性,以及基于机器学习算法在此问题中的可行性。
4.3. 实验结果
4.3.1. 仿真数据实验结果
1) Erdos_Renyi模型
在如表1描述的5000节点的Erdos_Renyi模型上进行实验,结果如表2、图3所示,实验效果没有随着拓扑结构变得稠密而有很大改进,如图4所示,MLP,SVM,DT算法表现良好,NB表现不稳定,KNN算法表现不佳,此模型最优算法为DT,所有算法正确率均能达到半数以上。

Table 1. ER model generation network
表1. ER模型生成网络说明
Table 2. Experimental results of ER model
表2. ER模型实验结果

Figure 3. The relationship between the number of the connected edges and the recognition results
图3. 连接边的数量与识别结果的关系
2) BA模型
BA模型具有两个特性:1) 增长性,是指网络节点的数量不断增多;2) 优先连接机制,是指网络当中的新节点更倾向于和那些连接度较大的节点相连接,本文使用网络的说明如表3所示。
在如表3描述的5000节点的BA模型上进行实验,结果如表4、图5所示,随着图越来越稠密,测试集正确率也随之有小幅提升,从图6中可以得出,SVM和MLP都有优秀表现,MLP表现要更好一些,KNN在稀疏时表现一般,稠密时表现良好,DT和NB则表现不稳定。
3) 随机生长模型
在每一个时间t,从网络中随机添加节点,并形成一个新的完整的图,本文中使用的网络如表5中所述。
在5000初始节点的随机生长模型上,如表6和图7所示,随着图越来越稠密,测试集正确率也随之有小幅提升,SVM表现最好。ROC曲线面积,MLP和SVM都表现优秀,难分伯仲,DT表现良好,但是会随着更加稠密而略有下降,KNN表现一般,NB则表现不稳定,如图8所示。因此,该模型链接预测最好的方法是MLP。
4) 森林生长模型
森林生长模型的图模型,在某一个时间,在图中添加新的顶点,本文中所使用网络如表7所述。
Table 3. BA model generation network
表3. BA模型生成网络说明
Table 4. Experimental results of BA model
表4. BA模型实验结果

Figure 5. The relationship between the output and the recognition results
图5. 出度与识别结果的关系
如表8与图9所示,在5000初始节点的森林火灾模型中,随着图越来越稠密,测试集正确率整体变化不大,ROC曲线面积,整体略有下降,其中MLP一直表现最好。各模型结果如图10中所示,MLP和SVM都表现优秀,DT,KNN表现有待提升,NB表现不稳定。因此,该模型链接预测最好的方法是MLP。
Table 5. Random growth model generation network
表5. 随机生长模型生成图说明
Table 6. Experimental results of random growth model
表6. 随机生长模型实验结果
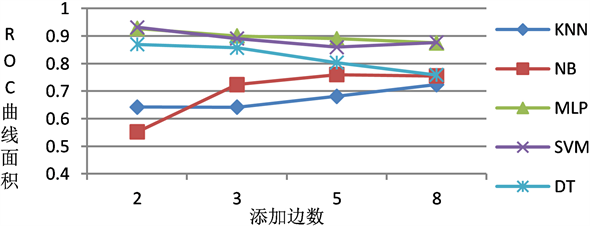
Figure 7. The relationship between the number of added edges and the recognition results
图7. 添加边数与识别结果的关系
Table 7. Forest growth model generation network
表7. 森林生长模型生成图说明
Table 8. Experimental results of Forest growth model
表8. 森林生长模型实验结果
4.3.2. SNAP数据实验结果
在仿真模型取得不错的结果以后,针对斯坦福大学的SNAP实验数据,进行了以下实验。
1) CA-GrQc
在表9中描述的CA-GrQc数据集上进行测试,结果如表10、图11所示,测试集正确率和ROC曲线下面积,五种方法表现都十分优秀,由于MLP的测试集正确率和ROC曲线下面积都为第二好,所以此数据集链接预测最优方法为MLP。

Figure 9. The relationship between the number of selected nodes and the recognition results
图9. 选择节点数与识别结果的关系
Table 10. Experimental results of CA-GrQc network
表10. CA-GrQc网络实验结果
2) CA-HepTh
在表11中描述的CA-HepTh数据集上进行测试,结果表12,图12所示,测试集正确率KNN相对最低,为0.86,其他四种方法表现都在0.9以上,五种方法都十分优秀。ROC曲线下面积,五种方法表现也都十分优秀。由于MLP的测试集正确率和ROC曲线下面积都为最好,所以此数据集链接预测最优方法为MLP。
3) Wiki-Vote
在表13描述的Wiki-Vote数据集上进行测试,结果如表14、图13所示,发现测试集正确率NB相对最低,为0.84,其他四种方法表现都在0.9左右,五种方法都十分优秀。ROC曲线下面积,五种方法表现也都十分优秀。由于MLP的测试集正确率和ROC曲线下面积都为最好,所以此数据集链接预测最优方法为MLP。
4) p2p-Gnutella08
在表15描述的p2p-Gnutella08数据集上进行测试,结果如表16、图14所示,测试集正确率相比前三种有所下降,其中MLP和DT在0.75以上,表现良好,其余三种在0.7以内,有待提高。ROC曲线
Table 12. Experimental results of CA-HepTh network
表12. CA-HepTh实验结果
Table 14. Experimental results of Wiki-Vote network
表14. Wiki-Vote实验结果
Table 15. P2p-Gnutella08 network
表15. p2p-Gnutella08网络图说明
Table 16. Experimental results of Wiki-Vote network
表16. Wiki-Vote实验结果
下面积,KNN和NB在0.75左右,表现良好,DT表现优秀,MLP和SVM都在0.91,表现优秀。由于MLP的测试集正确率和ROC曲线下面积都为最好,所以此数据集链接预测最优方法为MLP。
5. 结束语
本文首先概括分析了现有社会网络链接预测方法,尝试挖掘多维相似性特征,并使用机器学习的方法进行链接预测。通过大量实验验证了此方法的可行性。基于多维相似度属性的方法是现在常用的链接预测方法,但是相似度属性的选择是一个难点,选择不好则会出现维度越多反而效果更差的现象,如何选择相辅相成的特征,尝试进行主成分分析可能是下一步的一个工作重点,另外,如何将机器学习的方法达到实用,与并行、大数据等技术进行融合,并且考虑真实社交网络的动态变化,是链接预测实际应用的一个关键。
基金项目
北京市自然科学基金(4172016,4152054);北京市教委科研计划一般项目(KM201710011006)。