1. 引言
全球经济发展迅猛,国际市场变化多端,如美国实行宽松的货币和信贷政策,从而导致的美国房地产市场出现泡沫,进而引发影响极深的金融危机,这种影响在世界各地扩散。随着经济格局的变化,逐渐形成了金融一体化的局势,金融风险形式的多样化和复杂性也呈现出来,如何有效地防范和控制金融风险,使得经济发展平稳、有序地增长受到各界的广泛关注。风险不会被消除,但是可以通过风险测量结果分析,从而采取相应的措施来减缓风险。对于投资者而言,高收益、低风险是一个理想的目标,但一般来说,高收益总是伴随着高风险,这时候资产投资组合应运而生,通过分散投资的方法来减少投资风险,从而更好地满足投资者需求,这就是投资组合的优势。
连接函数(Copula)是一种描述变量之间相依机制的工具,能够描述金融市场中不同资产之间的相依结构,被广泛应用于资产组合的风险管理当中。1999年,Embrechts等 [1] 将Copula函数应用到风险管理领域,至此,越来越多的学者将目光投向基于Copula函数的风险度量应用和拓展。张尧庭(2002) [2] 对Copula函数的定义、性质、建模思想等方面做了系统性阐述,指出其在金融风险中的适用性;叶伟等(2015) [3] 基于阿基米德Copula的外汇投资组合进行风险研究;鲁思瑶等(2017) [4] 利用扭曲混合Copula和ARMA-GARCH-t模型分析股票、债券和基金之间的组合风险。但是,很多文献都是基于二元Copula函数进行相关研究,在实际中,我们面对的金融市场通常是多元的情况。投资组合的形式往往是多个不同市场之间进行组合分析,而在研究多元市场情况下,参数估计经常伴随着“维数灾难”问题,在处理高维数据时,多元Copula函数在计算上具有较强的复杂性。近年来,基于Pair-Copula构建模块的藤Copula (Vine-Copula)作为一种新的构建多元联合分布的方法受到越来越多学者的关注。Bedford、Cooke (2001 [5] , 2002 [6] )和Aas等(2009) [7] 提出“藤”的概念,且对Vine-Copula构建作了基本介绍。Hofmann等(2010) [8] 采用D藤Copula结构研究投资组合风险管理问题,指出其对比多变量Copula方法具有更灵活的性质;高江(2013) [9] 选取上证综指、纳斯达克指数、英国金融时报100指数、日经225指数、新加坡海峡指数构建国际投资组合,用藤Copula模型做组合的VaR预测;张高勋等(2013) [10] 运用Pair-Copula方法估计资产组合的VaR,并与传统Copula方法的VaR做比较,发现新方法较传统方法更有优势。
本文选取上证市场的工业指数、商业指数、地产指数和公用事业指数的日收益率数据,对上证市场间行业指数投资组合的风险进行研究。据查阅资料,在现有文献中对这几个数据间的组合分析还不多,因此文章以此为切入点,将Vine-Copula用于上证行业市场的投资组合风险度量,为投资者和风险管理者提供实证参考。
2. 基本理论
2.1. Pair Copula理论
在此,简单介绍copula的基本知识,以二元copula为例。
定义1.1 [11] :若二元函数
满足
1) C的定义域:
;
2)
有零基面且是二维递增的;
3) 对于U中的任意两点
,有
4) 对于U中的任意四个点
,如果
,则
则称函数
为Copula函数。
定理1.1:(Sklar定理) [12] 设二维随机变量
的联合分布为
,边缘分布分别为
、
,则对
,存在一个Copula函数C,使得
(1)
若
、
都是连续的,那么C是唯一存在的;反之,若
、
是一元分布函数,
为对应的Copula函数,那么(1)式定义的
函数是一个多元联合分布函数,边缘分布为
、
。这个定理描述了Copula函数和边缘分布函数的关系,指出可以通过一个Copula连接函数将一个多维联合概率分布函数同其对应的一维边缘概率分布函数结合起来。
Aas和Czado (2009) [7] 在文章中详细介绍了Pair-Copula的相关理论,认为多元变量联合密度函数按照某种结构可分解为一系列Pair-Copula密度函数和边缘分布函数的乘积。对于n维随机变量向量
,根据条件密度函数性质,X的联合密度函数可表示为
(2)
根据定理1.1,多元变量联合分布函数的密度函数可表示为
(3)
其中,
为n维Copula密度函数,
为边缘密度函数。
进而推导可得,任一条件密度函数可分解为二元Copula与条件密度函数,表达式为:
(4)
其中,
为n维向量v中的任一分量,
为v除去
的
维分量,
为条件边际分布函数。对于任意的j,
是二元Pair-Copula密度函数,有
(5)
2.2. 藤Copula理论
Vine-Copula实质是将传统的多元Copula以藤图的结构形式将多维Copula分解成一系列的二维或者条件二维Copula。正则藤(Regular Vine)最先在2001年由Bedford和Cooke [5] 提出,后在2006年由Kurowicka和Cooke [13] 做了详细的描述。在n元联合分布中,n维变量的藤主要是指一类树的集合,树j
的边是树
的节点,每棵树的边数都取最大。其中,最特殊的两类藤是Canonical-Vine(在文中简称C-Vine)和D-Vine两种藤。C-Vine的每一棵树Tj只有单一的点连接到
条边上,反观D-Vine,树中的任意一个结点最多和2条边相连。图1和图2分别是四维C藤、D藤各类结构的示意图。
按照C-Vine结构分解的n维变量,密度函数为
(6)
按照D-Vine结构分解的n维变量,密度函数为
(7)
其中,
为树的标号,i表示每棵树的边。
2.3. 风险度量工具VaR
VaR(Value at Risk)即在险价值,是风险测度的一个重要工具,用于表示市场正常波动在一定的置信水平下,投资者持有的证券或者资产组合在未来一定时间内可能产生的最大损失。公式表示为
(8)
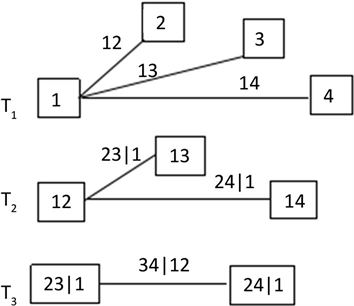
Figure 1. The tree schematic diagram of C-Vine
图1. C-Vine树形示意图
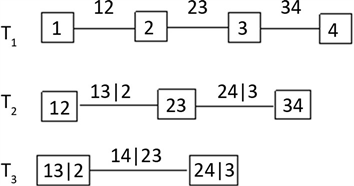
Figure 2. The tree schematic diagram of D-Vine
图2. D-Vine树形示意图
其中,
,表示在
的持有期下某一资产的损失额,
为置信水平。
2.4. 建模步骤
本文通过构建Vine-Copula模型,运用ARCH效应检验、GARCH建模等方法度量上证四大行业板块指数组合的相依性风险。建模步骤如下:
1) 求出各行业指数的日收盘价各自对应的对数收益率,并做出时序图;
2) 为了解四个收益率序列的总体情况,对其做基本描述性统计分析和平稳性检验;
3) 对收益率序列做ARCH效应检验,检验序列的异方差性,根据检验结果建立GARCH类模型;
4) 考虑t分布和偏t (skew-t,以下简称st)分布拟合序列的残差分布,并最终通过标准化GARCH-t和GARCH-st建模后的残差序列,进行概率积分变换,得到各样本的累积分布,再用K-S检验进行筛选;
5) 建立Vine-Copula模型,并通过极大似然值、AIC和BIC准则选择合适的C-Vine或D-Vine结构;
6) 利用蒙特卡罗方法计算在给定置信水平下投资组合的VaR,并做Kupiec返回检验。
3. 实证分析
3.1. 数据的选取和基本分析
本文选取上海股票市场四个行业板块指数组合:上证工业指数(000004)、上证商业指数(000005)、上证地产指数(000006)、上证公用事业指数(000007)为研究对象,数据日期区间为金融危机后2009年1月04日~2017年8月25日,共2103个日收盘价数据,其中样本段选取三分之二数据作为样本内建模数据,跨度为2009年1月04日至2015年1月26日,剩下的三分之一作为VaR检验部分,数据来源于网易财经(http://money.163.com/)。主要采用日收益率作为本文研究的对象,计算公式为
(9)
其中,
为第t日的收益率,
为第t日的收盘价,
为第
日的收盘价。
为了对样本数据有一个直观的了解,首先对日收益率数据进行时序图描述分析,如图3所示。从收益率时序图可以看到,四个行业板块指数收益率波动均具有“集群”现象,表现为收益率序列的波动随着时间的改变而变化,一般地,大的波动紧跟着大的波动,小的波动紧跟着小的波动。同时说明该序列存在条件异方差的迹象,不具有随机波动的特征。另外,可以直观看到在序列的最后阶段,即2014年底、2015年初出现了较为强烈的波动,这一变动反映了现实中2015年A股市场的混乱引发的金融市场的动荡情形。纵观四个收益序列图,上证四个行业指数收益率的波动值均在0.1%内,可见四个资产组合都具有收益稳定、投资风险小的特点。
接着,对选取的样本数据进行基本的统计描述和平稳性检验。
观察表1数据,各样本的偏度值均为负数,说明上证各行业指数对数收益率均存在左偏现象,所有指数的峰度值都大于正态分布的峰值3,说明样本均具有“尖峰厚尾”的特点,并不服从正态分布。进一步分析,4个样本收益率的Jarque-Bera统计量都非常大,且各自对应的P值均接近0,说明在95%的置信水平下显著,再次验证了样本收益率序列不服从正态分布的假设,应考虑其他的分布情况。另外,根据ADF单位根检验结果,可知检验统计量的P值都低于0.05,拒绝“收益率存在一个单位根”的原假设,说明上证市场四个对数收益率都是平稳的,不存在伪回归问题。
3.2. 实证研究
3.2.1. GARCH模型的选取和估计
由于基本统计描述分析发现收益率序列均不服从正态分布的假设,故本文考虑用t分布和偏t分布对
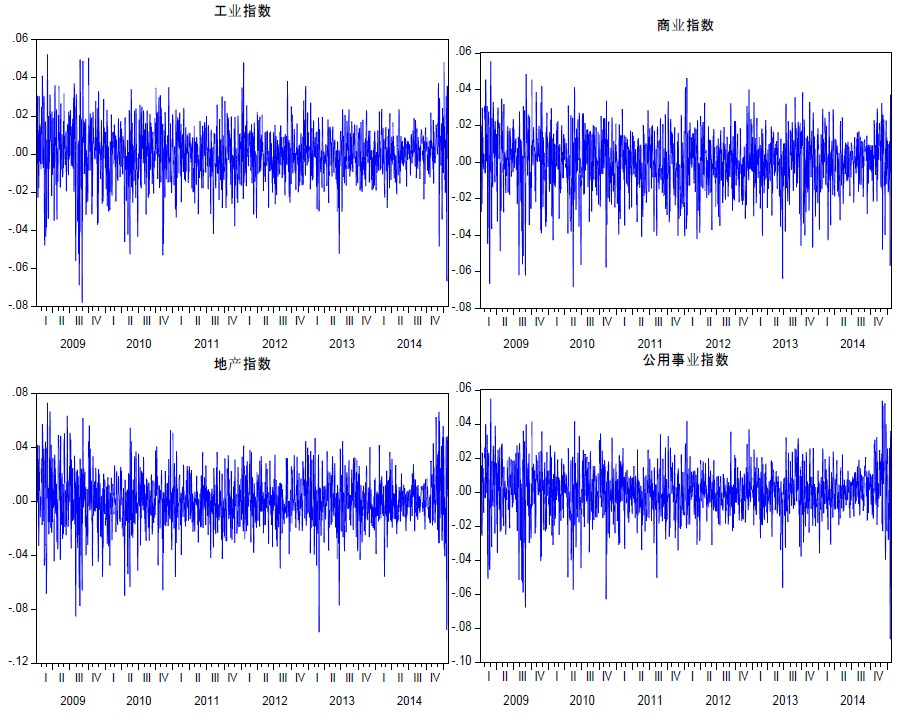
Figure 3. Time series diagram of the yield rates of the four assets
图3. 四种资产的收益率时序图

Table 1. Statistical description of each sample
表1. 各样本的统计描述
注:括号内部的值为P值。
边缘分布进行拟合,在实证过程中,通过各股市的收益率波动图发现四个股市收益率均存在波动集聚效应,且存在条件异方差。结合描述性统计分析,综合考虑,本文采用GARCH-t和GARCH-st对实际数据进行自相关、波动集聚的异方差性拟合过滤,确定工业指数、商业指数、公用事业指数均选择GARCH(1,1)模型,地产指数选择GARCH(1,2)模型,最终得到GARCH-st模型的参数估计结果如表2所示。由于在后期K-S检验中GARCH-t作为边缘模型拟合的数据不通过[0,1]分布检验,为节省篇幅,故在此不附上GARCH-t结果图。
Table 2. Estimation results of GARCH-st model
表2. GARCH-st模型估计结果
注:α0是常数项,α1是ARCH项系数,β1是GARCH (-1)项系数,β2是GARCH (-2)项系数,括号内是z检验的P值。
由表2可知,四个模型中的参数值对应的P值都近似为零,说明各模型中各参数都非常显著。并对四个模型分别做残差平方自相关检验以及ARCH-LM检验,发现模型对应的Ljung Box-Q统计量都十分小,对应P值显著不为0,可知序列经四个GARCH模型拟合之后,消除了异方差,且已不存在ARCH效应。其中,系数
反映了外部因素对内部市场收益率的影响,系数
表示的是证券市场对数收益率波动对自身的影响,这种影响呈正比,表现为其长记忆性。通过模型估计结果可知,商业指数受外部市场的影响最大,地产指数对自身的影响最长远。
3.2.2. [0,1]均匀分布检验
根据Copula函数的定义,可知要构建Copula函数,变量须服从[0,1]上的均匀分布。对四组GARCH-st模型中得到的标准化残差序列进行概率积分变换,得到各样本序列的累积分布,再通过K-S检验验证累积分布序列是否服从[0,1]均匀分布。K-S检验原理是将原假设设为待测样本服从某一特定分布,在给定的显著性水平下,比较检验统计量KS与临界值
大小,若
,此时记
,表示接受原假设,可认为待测样本服从这一特定分布。检验结果见表3。
由表3的K-S检验结果可知,概率积分变换后的4个序列的h值都为0,表明检验结果和经概率积分变换后的序列都服从[0,1]均匀分布;KS统计量均小于
临界值,表明样本序列符合给定的理论分布;相应p值均大于5%的显著性水平,表明检验结果不拒绝“样本数据符合[0,1]均匀分布”的原假设;结合这三方面进行判断,可以肯定检验结果不拒绝序列服从[0,1]分布的原假设,可进一步建立Copula函数。
3.2.3. Vine-Copula函数建模
构建Vine-Copula函数的一个必要步骤就是选择合适的藤结构,在此对常用的C藤和D藤进行对比分析。首先,对标准化残差概率积分变换后的序列进行相关性研究,计算投资组合指数之间的Kendall’s tau秩相关系数,结果见表4。
通过相关系数表4,可以看到4组样本的秩相关系数值之间,公用事业与其他指数相关值较大,因此,初步判断,存在明显的关键性变量以确定C藤的初始节点,所以初步拟选择C藤。对每一组样本的Kendall秩相关系数值求和,并以和大小进行排序,将排序大小为依据确定C藤的根节点,如表4所示,则C藤的顺序为(2,3,4,1),为了进行对比,D藤结构也设为(2,3,4,1)。
为了进一步明确藤结构的选择,比较得出更合适的Vine copula结构,将通过模型的AIC和BIC最小化,以及似然值最大化的原理进行确定。
同时,为了选择更为合适的Pair-Copula函数,本文不设定某一特定的Copula类型,而是通过在20个copula类型中进行选择,包括Gaussian Copula、Student-t Copula、Clayton Copula、Gumbel Copula、Frank Copula、Joe Copula、BB1 Copula、BB6 Copula、BB7 Copula、BB8 Copula和它们的旋转Copula [14] 。
表5结果显示,C藤结构和D藤结构的AIC值和BIC值相比,后者均大于前者,且前者的似然值大
Table 4. Kendall’s tau rank correlation coefficient of standardized residual probability integral transformation sequence
表4. 标准化残差概率积分变换序列Kendall’s tau秩相关系数
Table 5. Results of Pair-Copula fitting of rattan structures
表5. 藤结构的Pair-Copula拟合结果
注:par为相应二元copula函数的参数,par2为相应二元copula函数的自由度。
于前者,说明C藤结构的Pair-Copula方法要优于D藤结构的Pair-Copula方法,更适合描述本文中上证市场四个行业板块之间的高维相依性。
接着,结合各个资产之间相应的Pair-Copula,做出更直观的树形结构图,在此给出C-Vine的树状图4。根据图4各上证板块之间的连接Pair-Copula,可以发现板块两两之间均存在不对称的尾部相关性。结合表5和图4,从Tree1来看,公共事业与工业之间显示出较高的无条件相依性,且两者的相依结构均适合用Student-t Copula模型刻画,这说明两者具有对称的上下尾相关性,而公共事业与商业、地产之间适合用SBB1 Copula描述,说明它们之间存在不对称的上下尾相关性。Tree2中,在公共事业资产条件下,商业和工业可用student-t Copula刻画,表现对称的上下尾条件相依性。Tree3中,在公共事业资产条件下,商业和工业与工业和地产之间的相依结构适合用Student-t Copula模型描述,说明两者之间存在着对称的上下尾相关性。
3.2.4. VaR风险度量和模型检验
在进行资产组合风险度量过程中,本文将工业指数、商业指数、地产指数和公用事业指数四种资产按照0.25:0.25:0.25:0.25等比重来进行求解,利用蒙特卡罗模拟法计算在投资总额一致的情形下,上证市
场四个行业指数分别在不同的置信水平下的VaR。此处采用每日滚动窗口进行动态仿真模拟,首先用建立的样本模型GARCH-st-C-Vine-Copula模型随机生成服从[0,1]均匀分布的四个组合序列,根据偏t模型的逆分布,反推出残差序列项,进而在GARCH模型中计算出仿真的收益率,最后计算出组合的VaR。本文重复以上步骤5000遍,考察置信水平为99%、95%下组合的风险值。
在99%和95%的置信水平下,上证股指行业板块组合使用2015年1月27日到2017年8月25日的样本数据,即样本外631天数据,计算出的样本外的金融资产组合在C-Vine Copula模型下的VaR值,所得如图5所示。
同时,本文以基本的模块Student-t Copula、SBB1 Copula和SBB8 Copula为内部结构构建C-Vine Copula模型,可充分刻画金融风格资产联合分布的分布情况。为了对模型有效性进行说明,进一步,对模型进行后验分析,结果如表6所示。
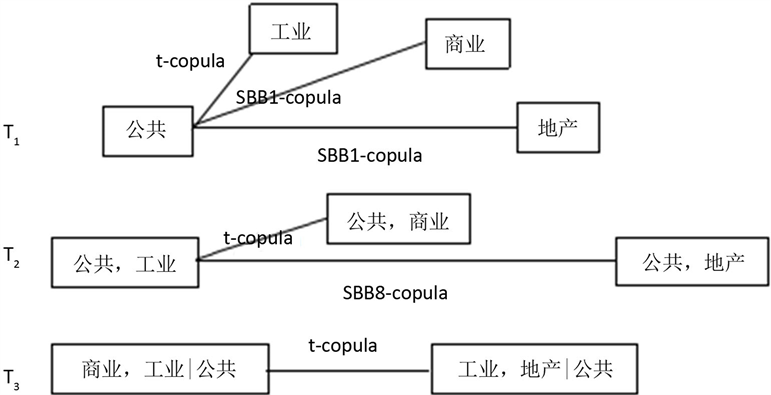
Figure 4. Dependency structure diagram of C-Vine Copula model
图4. C-Vine Copula模型的相依结构图
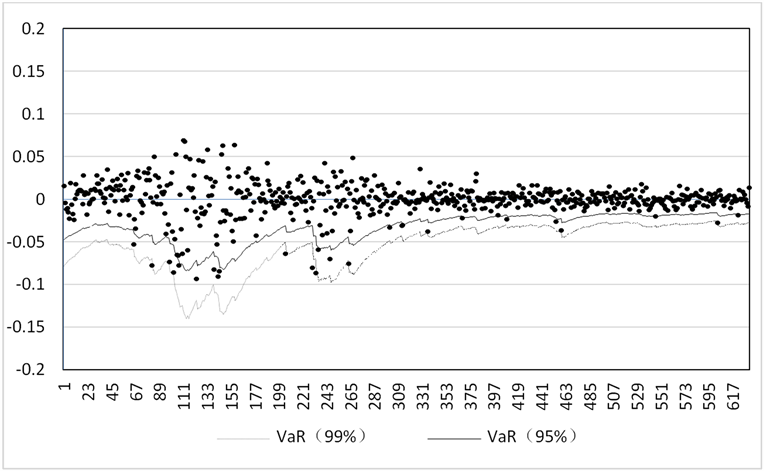
Figure 5. The VaR result based on the C-Vine Copula model
图5. 基于C-Vine Copula模型的VaR结果
Table 6. Kupeic test based on failure rate of GARCH-st-C-Vine Copula model
表6. 基于GARCH-st-C-Vine Copula模型失败率的Kupeic检验
其中,
,
,从表6可以看出,模型的检验值LR小于临界值,且LR统计量对应的P值均大于0.05,接受原假设,即回测失败率不显著不同于实际失败率,同时可以看到期望的失败天数均大于实际失败次数,综上,说明模型具有合理性,VaR值具有效性,另外,在99%置信水平下的结果与95%置信水平下的结果对比发现,在99%的置信水平下的结果最接近期望值,LR值最小,可见在此水平下的VaR值更有效。
4. 结论
本文运用GARCH-st-C-Vine-Copula模型对我国上证股票市场行业指数中的工业指数、商业指数、地产指数和公用事业指数进行实证分析,研究了四个资产组合之间的相依性风险,得到以下结论:
1) 工业指数、商业指数、地产指数和公用事业指数四个资产组合的对数收益率均具有“波动集聚”的特点,且为平稳序列,四个资产组合的对数收益率均具有“尖峰厚尾”的特征,并不服从正态分布,不能用正态分布来拟合其边缘分布,考虑了t分布和偏t分布,最后选择符合条件的偏t分布。
2) 在实证分析中描述了四个资产组合各自的日对数收益率序列的基本特征之后,并做了相关的检验,最终工业指数、商业指数、公用事业指数三者对数收益率序列选择GARCH(1,1)模型,地产指数对数收益率序列选择GARCH(1,2)模型。
3) 在藤Copula模型的构建中,对比C藤与D藤在四个资产组合的AIC和BIC、极大似然值,发现在工业指数、商业指数、地产指数和公用事业指数四个资产组合中,C-Vine Copula更适合。
4) 选择在偏t分布假设下的GARCH模型,结合C-Vine Copula模型,分别计算在99%、95%置信水平下的VaR,并通过Kupiec返回检验对模型进行后验测试,说明了本文模型构造的有效性,并发现了不同的置信水平下,99%下的VaR值精度更高。
总体而言,基于Student-t Copula、SBB1 Copula和SBB8 Copula的具有尾部特征的Pair-Copula作为模型C-Vine Copula的构建部分,能够有效地预测上证股指行业板块的金融风险。本文研究为投资者和风险管理者提供了一定的借鉴性,投资者可以通过调整不同资产配置来进行投资,风险管理者可对当前市场股市之间的非线性、非对称关系有更深入的了解,为其在发布风险预警、制定规则等决策时提供一定的参考价值。
基金项目
国家自然科学基金项目(71762008);国家自然科学基金(61763008)。