1. 引言
研究森林结构组成和生产力可以帮助林场获悉森林生长状况并制定相应生产决策,也有助于研究森林生态系统碳循环及其对全球环境变化的响应 [1] [2] 。森林调查数据被认为是科学的研究森林结构和生产力的基础数据来源 [3] [4],但因其获取难度较大,不足以支持大范围、长时间序列的森林研究 [5] 。随着遥感对地观测技术的发展越来越多的公开科学数据集可以用来与稀缺的森林调查数据相结合 [6] [7],以实现在更广泛的时空范围上研究和监测森林状态。如高分辨率数字高程模型、光学影像、星载或机载激光雷达等 [8] [9] [10] [11],可以加入对森林类型、森林结构的描述,进而提高全面、准确的探究森林的各个要素的能力。例如,Zhang (2014) [12] 使用森林冠层高度及叶面积指数的遥感资料结合样地清查资料估计了美国加州地区森林地上生物量。De Groeve (2000) [13] 提出了通过森林类型的调查资料估计了蓄积量的方法,并在加拿大魁北克进行了验证。Yanjun Su (2016)结合森林清查资料、ICESat卫星遥感资料、气候资料和地形资料等多种数据估算了中国森林地上生物量的空间分布情况。
根据以往使用多源数据研究森林结构及蓄积量的文献资料来看,综合处理和分析包括森林调查资料、遥感、地形、空间范围等多种数据时往往需要结合使用多种商业软件,如ARCGIS、ERDAS、ENVI、SPSS等 [14] [15] [16] 。然而,交叉使用多种商业软件的学习和使用成本较高;此外,在数据层面讲,不同数据源需要兼顾不同软件的使用要求而不能统一,降低了整个系统的适用能力和灵活性。因此,本研究考虑使用全开源的代码整合成一套利用多源数据综合分析林区森林状况的研究框架,以灵活支持多种数据源、分析方法,应对不同的研究目的。
2. 研究区概述
本文的研究区域,陕西省宝鸡市马头滩林业局位于北纬34.0˚~34.3˚、东经106.9˚~107.2˚的秦岭西部主梁两侧,地跨陕西省宝鸡市渭滨区、凤县两县(区),全区年平均气温13℃,4~9月为暖温期,10~3月为冷温期,全年无霜期在158~225天。平均年降水量700 mm,4~10月份降水占全年总量的90%,5~9月为多雨期,7~9月为主汛期,7~9月降水量占全年的60%。全局总经营面积34,668公顷,均为林业用地,主要树种包括锐齿栎(Quercus aliena)、华山松(Pinu sarmandi)、红桦(Betula albo-sinensis)等,森林覆盖率95.2%。此前关于秦岭地区森林生物量或生产力的研究大多使用叶面积、树木年轮等调查资料 [17] [18] 。本文首次使用森林调查资料结合多源遥感资料的方法研究了秦岭马头滩林业局的森林结构组成和生产力空间格局,并根据调查得到的蓄积量与获取的地形、冠层高度、植被指数等要素之间的关系模拟了2000~2015年该区域的总蓄积量变化过程。
3. 数据和方法
3.1. 研究数据
本研究旨在通过分析森林资源调查资料并结合多源公开科学数据集研究森林结构组成和生产力空间格局及其动态变化。因此,研究所需的数据除森林资源调查资料外,还应加入可以表征森林资源时空分布或对森林资源的时空分布产生潜在影响的遥感数据集,如归一化植被指数(NDVI)、森林冠层高度、数字高程模型(DEM)等。由于各类数据的时空尺度、投影类型、存储格式及数据结构各不相同,应将各类数据分别经过预处理后放入一个统一的框架下进行综合分析。本节将对本研究所涉及的数据逐类说明并介绍相应的预处理方法。
本研究使用的森林资源调查资料为宝鸡市马头滩林业局2008年森林资源二类调查小班因子数据表。资料记录了区内各林班的面积、地形特征、优势树种及蓄积量,共计4293条。
DEM数据在本研究中用于分析林区中不同海拔的森林结构组成,以及地形要素与森林结构组成和生产力的潜在关系。研究收集的DEM数据为SRTM (Shuttle Radar Topography Mission) 90 m分辨率数字高程模型,数据来源于中国科学院计算机网络信息中心国际科学数据镜像网站(http://www.gscloud.cn)。
全球1 km分辨率森林冠层高度资料在本研究中被用来表征林班尺度的平均树高。森林冠层高度资料根据从ICESat卫星搭载的星载激光雷达获取的数据并加入森林类型、高程及气候变量模拟得到 [19],目前可从美国橡树岭国家重点实验室开放下载(https://webmap.ornl.gov/wcsdown/dataset.jsp?ds_id=10023)。该资料文件格式为具有投影信息的TIFF栅格图像。
植被指数资料来自于数据来源于中国科学院计算机网络信息中心国际科学数据镜像网站(http://www.gscloud.cn)的中国500m NDVI月合成产品,该产品是由MODIS NDVI数据计算得到,计算方法为取月内每天最大值。
3.2. 数据处理与分析方法
对林班森林资源调查表的统计分析使用的是基于Python语言的Pandas数据分析库。Pandas是一种开源数据分析程序库,可通过Python编程调用,其主要功能包括表格数据的读写、汇总统计、筛选排序、运算及可视化。详情可见Pandas官网http://pandas.pydata.org/。
为使林班调查资料与其相应的空间位置对应,本研究从马头滩林业局获取了马头滩林业局林班位置地形图,并使用QGIS 2.1对地形图配准、矢量化及投影变化,最终生成ESRI Shapefile格式的马头滩林业局林班位置矢量地图。QGIS是一款开源免费的地理信息系统软件,灵活支持多种数据类型及地理空间数据库;在其空间分析框架下还可插入社区贡献的数据分析模型,可极大的方便了地学研究者数据处理和分析的工作(详见http://www.qgis.org/)。
林班空间位置文件(ESRI shapefile格式)在以下分析中将会与各种格式的数据综合分析,因此需要对各林班地理位置或范围的信息和各类林班属性信息实现数据结构对应统一。在本文中,林班空间位置文件用GeoPandas库处理,其数据结构可以与森林调查数据统一并通过林班号关联。
本研究考虑到基于林班尺度森林调查数据尺度最小且最为可信,因而将所有获取的高程数据、树高数据和植被指数数据统一到林班尺度。以上获取的遥感资料以不同形式的栅格数据格式储存,像元空间分辨率也大小不一,此外,由于林班空间范围信息是矢量格式,在此就涉及到栅格形式和矢量形式的统一问题。本文首先使用Rasterio接口(https://mapbox.github.io/rasterio/)对各种格式的栅格数据读取、拼接、裁剪,再通过RasterStats接口(http://pythonhosted.org/rasterstats/)将落在各林班空间范围内的像元汇总到各林班的属性表中。
对森林调查资料和遥感资料的回归分析在本研究中使用的工具为StatsModels [20] 统计分析库(http://pythonhosted.org/rasterstats/)。StatsModels库同样是开源的Python代码库,可以进行各种形式的回归分析并对不同回归模型进行评估。此外,该程序还可实现通过形如“y = x1 + x2”的表达式简单直观的构建模型,便于进行模型的比较和选择。
本文所展示的地图和各式统计图均由Python语言结合相应开源绘图代码库生成,因此本文所提出的分析框架可以直接实现对所分析数据和结果的可视化。其中,基础绘图库为Matplotlib [21] (https://matplotlib.org),Seaborn 应用程序接口(https://seaborn.pydata.org/)用于美化图面的线型、配色等外观要素,而地图的投影和绘制使用Cartopy [22] (http://scitools.org.uk/cartopy/)。
4. 结果
4.1. 蓄积量分布
通过将林班尺度的调查数据和林班位置进行对应,本研究展示了马头滩林业局单位面积蓄积量的空间分布规律。如图1所示,单位面积蓄积量变化范围为10至118 m3/hm2,且南、北部大而中部小,如东北部2、10、11号林班单位蓄积量大于110 m3/hm2,南部115、116号大于96 m3/hm2,而中、西部50、76、55号林班单位蓄积量则小于50 m3/hm2。结合依据DEM数据得到的林班平均海拔高度分布图(图2)可以发现,林班尺度上的单位蓄积量应受地形要素的影响。马头滩区域地形呈现中部横贯东西为脊而南北两侧为坡的地形,中部海拔高而南、北坡海拔低,与单位蓄积量分布规律相反。如图3,经相关性分析可见,马头滩区域林班平均海拔高度与单位蓄积量之间存在显著的负相关关系(p < 0.01),其Pearson相关系数为−0.38。
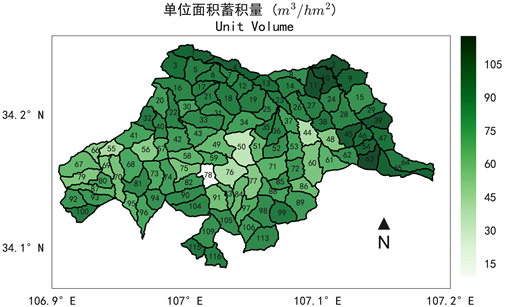
Figure 1. Spatial distribution of unit volume in Matoutan Forest
图1. 单位面积蓄积量空间分布图

Figure 2. Mean elevation (m) for each compartment
图2. 各林班平均海拔(m)高度图

Figure 3. The relationship between unit volume and mean elevation
图3. 单位面积蓄积量与林班平均海拔高度关系图
4.2. 森林结构组成
根据森林调查数据记录的地类和优势树种信息并结合林班海拔高度可以从海拔高度这一维度宏观的揭示马头滩森林结构组成。本研究首先将林班根据其平均海拔高度以100 m为间隔分为不同的区间,而后在各区间内将不同森林类型的面积汇总统计。从图4可见,马头滩区域范围内海拔2000 m以下区域主要为栎类为优势树种的阔叶林,而从海拔2000 m开始出现以桦类为优势树种的森林,且栎类逐渐减少而桦类逐渐增加。马头滩区域内针叶林分布面积少于阔叶林,并且从图4还可以的看到云杉为优势树种的森林主要分布在2000 m以上的海拔较高区域而华山松主要分布在较低海拔区域。以上所述即可从调查数据这一方面基本概括出马头滩森林结构组成的主要部分,而通过遥感资料获得的森林冠层高度信息可以与此对比。如图5所示,森林冠层高度在马头滩南、北坡较大,最高可达36 m,而在中部山脊较小,平均仅为24 m,同样揭示出马头滩森林结构组成与海拔分布有关。
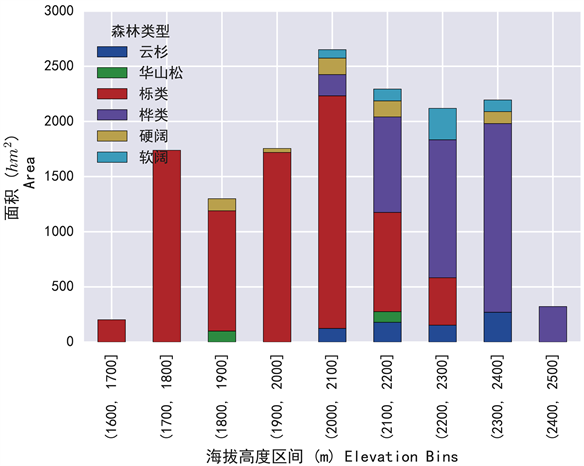
Figure 4. Forest types in different elevation bins
图4. 不同海拔高度区间内的各森林类型面积分布
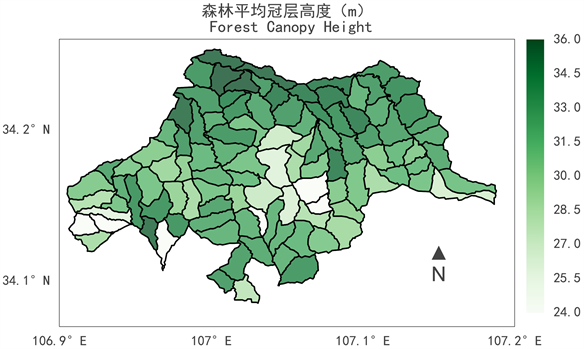
Figure 5. Spatial distribution of forest canopy height
图5. 森林平均冠层高度分布示意图
4.3. 植被指数分布
植被指数NDVI用来表征马头滩区域地表植被覆盖状况的空间分布及其随时间的变化情况。马头滩林区森林覆盖度高,夏季NDVI值基本均在0.90~0.97之间,冬季由于落叶树种叶片枯萎凋落而常绿树种凋落较少,因此从冬季植被指数的空间分布上可以较为明显的表示树种的差异。如图6所示,二月份马头滩林区NDVI值在0.30~0.54之间,高值出现在南、北坡而低值集中在中部高海拔区域,此外,最北部海拔最低处NDVI值又较中海拔区低,此趋势与森林调查资料展示的单位面积蓄积量空间分布趋势相一致,说明NDVI能较好反映出森林覆盖密度的空间分布规律。本研究通过分析2008年各月的NDVI遥感资料,发现林班尺度的NDVI在年内各月的变化同样可以指示其单位面积蓄积量的大小。例如图7所示的处于同一纬度和海拔高度上单位蓄积量却有较大反差的39号和55号林班的NDVI随时间的变化:夏季五月到九月植被茂盛,单位蓄积量大和小的林班在植被指数上并没有明显差别,但是冬季十一月到次年四月39号和55号林班的NDVI则表现出明显的差别,其中一月差异可达0.2。如果从曲线下方围成面积的角度观察图7可以更加清晰的看到单位蓄积量不同的两个林班在NDVI上所表现出的不同。将2008年调查得到各林班单位面积蓄积量与2008年NDVI总和做相关性分析可以得到其Pearson相关系数为0.27,p < 0.01。

Figure 6. Spatial distributions of NDVI in February
图6. 二月份NDVI空间分布

Figure 7. Seasonal cycle of NDVI for compartment 39 and 55
图7. 39号、55号林班NDVI在2008年各月变化
4.4. 蓄积量模拟
从以上论述不难发现,林班尺度的单位面积蓄积量与地形要素、森林结构组成、植被指数的季节循环都有关系,那么可以通过建立回归模型对马头滩区域内单位面积蓄积量进行模拟。同一套遥感资料可以提取并衍生出不同的值作为回归模型的解释变量,例如,在将DEM的值汇总到林班上时可以去林班面积内多个高程值得平均值、最大值、范围值等。经过对不同模型的筛选,本研究确定的回归模型包括了归一化植被指数年内12个月之和(X1)与森林类型(X2)的联合作用,以及森林冠层高度汇总到林班时的平均值(X3),其中,对森林类型数据(X2)的处理采用“哑变量”方法,即将属于某类型的林班设为1而将不属于该类型的林班设为0。模型表达式为:
回归模型结果如图8所示,模型的R2为0.395,调整R2为0.350。为对模型进行验证,留取总数10%的林班作为验证数据集。考虑到马头滩林区林班编号在空间上具有连续性,为使抽样样本覆盖全林区范围,本研究采用的抽样方式为从编号的第5号林班开始,每隔9号抽取一个直到结束,共11个样本,占总体的10%。验证数据集R2为0.58,p < 0.01。
4.5. 模拟过去蓄积量变化
根据森林调查调查得到的马头滩林区总蓄积量为197.3万m3,而根据上文的回归模型模拟的单位面积蓄积量再乘以林班区域面积后所得的总蓄积量为196.8万m3,二者相差不足1%,因此认为利用以上得到的回归模型模拟研究区总蓄积量的变化是较为合理的。本研究处理了从2000年到2015年所有可获取MODIS NDVI产品的年份共16年的MODIS NDVI遥感资料,依此模拟了过去16年马头滩林区森林总蓄积量。结果如图9所示,过去16年马头滩林区总蓄积量呈现出明显的增长趋势,从最低的2001年不足195万m3增长到2013年附近的203万m3。呈现出增长趋势的主要原因应为马头滩林业局封山育林,稳步推进天然林保护工程。
5. 讨论
原始多源遥感资料分辨率的不同以及所涉及的研究尺度问题为本研究带来了较大的不确定性。其中,马头滩林区林班面积,也即是森林调查资料可以区分的最小面积在2~3平方公里左右。遥感资料中最粗为森林冠层高度产品的1 Km分辨率,最细为高程资料的90 m分辨率。为结合森林调查资料和多源遥感数据进行统一的分析,本研究将研究尺度通过区域汇总的方法上升到林班尺度。这种方法虽然避免了因为插值方法造成的不确定性和复杂性,但是在升尺度的过程中损失了细节信息。基于本文提出的框架具有尺度选择灵活性的特点,在今后的研究中可以通过比较尺度差异对蓄积量估计结果和不确定性的影响进行更加详细的分析。此外,资料本身的不确定性也会影响到整个分析过程。例如森林冠层高度资料的验证结果为RMSE = 6.1 m,R2 = 0.5 [19],且该资料对冠层高度较高的区域有所低估,这与本文得到在较高蓄积量(冠层高度一般也较大)的区域被明显低估的结果也有所照应。
大量研究表明,对森林蓄积量的估算准确性的提升方法除了纳入更多源、更多维度维度、更高质量的数据外还可以通过比较选择更为合适的统计模型,如回归树模型、支持向量机、KNN、人工神经网络等 [23] [24] [25] 。Gleason et al. (2012) [2] 讨论了线性回归、随机森林和支持向量机回归在使用激光雷达数据对森林地上生物量的估算中的性能比较,结果显示支持向量机回归对估算结果具有显著提升。本研究在估计森林蓄积量过程中使用的多元回归模型较为简单,意在突出研究的整体框架而非重在讨论不同估计森林蓄积量的模型。由于本文发展的研究框架对不同模型算法具有支持 [26] [27],随后的研究中也将会着重比较统计模型对森林生产力估算精确度的影响。

Figure 8. Relationship between estimated and observed
图8. 模拟的单位面积蓄积量与观测对比关系

Figure 9. The estimated annual total volumes from 2000 to 2015
图9. 2000年至2015年模拟的总蓄积量变化情况
6. 结论
本文提出了一种充分挖掘和利用现有林业局森林资源调查资料的分析框架,通过结合森林调查资料及多种遥感资料展示了秦岭马头滩林业局蓄积量、森林类型、森林冠层高度等多种要素的空间格局,并根据2000~2015年的遥感资料估算了马头滩林区总蓄积量的动态变化过程。结果显示:马头滩林业局森林资源主要分布在南、北部,单位面积蓄积量随海拔高度呈递减趋势;高海拔区域主要分布以桦类为主的森林且平均森林冠层高度较小,而中低海拔则以栎类占多数且森林冠层高度大;马头滩林区近16年总蓄积量呈增长趋势,从195万m3增长到超过201万m3。本研究发展的研究框架通过对马头滩林区的研究可看出具备了较为完整的处理数据、分析数据、统计模拟、结果展示等相应的能力,全部处理和分析过程除地形图的配准和矢量化需要人工干预,其它功能均可自动完成。由于其代码不受商业软件版权限制、数据源来自公开数据、算法不针对地域有过多参数化调整,因此适用于在各具有森林调查数据的林区开展多种灵活的林业研究。
基金项目
国家自然科学基金(31570473)。
参考文献
NOTES
*通讯作者。