1. 引言
评论信息已成为消费者制定商品购买决策的重要信息来源,且对消费者的商品购买决策影响非常显著 [1] ,然而,评论信息形式为半结构化或非结构化,商品购买决策时面临前所未有的挑战 [2] 。推荐系统一般使用户评分数据的推荐算法存在数据稀疏、评分信息不能够真实有效地表达用户兴趣等问题。因此以网站商品评论为物品特征描述语料,利用word2vec词向量模型进行评论文本情感分析,获得商品好评率,并筛选商品正向评论文本集,作为商品正向特征的描述文本集,本文使用LDA主题模型提取物品主题特征,在此基础上,结合TF-IDF提取主题关键词特征,作为物品描述文本信息的主题——关键词特征集,以增强主题粗粒度特征对物品的描述能力,提高推荐的准确率。
2. 相关研究
安悦等人 [3] 采取的基于内容的热门话题的个性化推荐,首先利用TF-IDF的文本表示方法对微博中的文本数据进行量化表示;然后利用相似度计算方法计算微博话题与用户之间的相似度,进而给出个性化的推荐列表。单京晶 [4] 提出一种联合K-means的个性化推荐方法,该方法首先对与用户感兴趣的产品特征进行聚类,将具有相似特征的产品聚到一个类别内,然后将与每个聚类中心点最近的产品推荐给用户。李峰刚等人 [5] 在新闻文本分类的文本分类算法中使用LDA进行特征降维;胡勇军等人 [6] 利用LDA模型将特征维度进行扩展,实现对短文本的分类;Chen等学者 [7] 在研究文本间的相似性问题时,使用LDA模型计算文本相似,根据文本相似度将搜索记录数据结果集进行分类。Feng等人 [8] 基于组合的概率主题模型-用户主题模型(UTM)和随机行走与重启(RWR)方法的组合推荐。UTM通过利用用户的偏好概况和项目的内容信息来提供用户、组和项目的潜在框架,它们可以更全面地描述组兴趣和项目特征。然后将该潜在框架与RWR结合,通过检测综合潜在关系来预测群体对未评级项目的偏好程度。Aslanian等人 [9] 提出基于协同过滤和内容推荐的混合推荐算法,介绍了一种新的提取内容特征关系矩阵的方法,然后对协同过滤推荐算法进行了改进,使得该关系矩阵能够有效地集成到算法中。与现有的算法相比,该算法能更好地解决冷起动问题。
3. 基于情感分析和LDA主题拓展的推荐算法
3.1. 用户评论文本情感分析
Word2vec是Google公司在2013年提出的一款以深度学习算法思想为基础将词语表征转化为实数值词向量的高效开源工具。主要是利用深度学习方法训练文本内容将词语转化为词向量形式,从而词语语义相似度可以通过向量空间中词向量相似度表示,也可以对文本处理简化为向量空间中词向量运算。
Word2vec算法主要包含两种语言模型:CBOW (Continuous Bag of Words)和Skip-gram (Continuous Skip-gram Model)。这两种模型都包括输入层(input)、映射层(projection)、和输出层(output)。CBOW根据上下文语境预测目标词语,Skip-Gram根据当前单词预测上下文语境窗口内的词语。
主要步骤:
1) 爬取评论信息经分词、去停用词等预处理;
2) 训练生成word2vec词向量模型;
3) 获取每条评论文本词语的词向量,计算每条评论文本词向量均值,做为每条评论文本的文本向量;
4) 将有标记的评论文本向量按4:1比例分为训练集和测试集,采用SVM分类器,筛选出物品的正向评论、获取物品正向评论率。物品i正向评论率
为物品i正向评论条数
,与物品i总评论条数
比值。
3.2. LDA主题模型
隐含狄列克雷分配主题模型(LDA: Latent Dirichlet Allocation)其实是基于“文本–主题–词”的三层贝叶斯产生式模型,用LDA主题模型对产品的评论内容进行主题词的抽取,用主题维度来代替原来的词项维度,可以较好地降低文本表示的特征维度。本文通过使用主题模型,文本就被投影到k个主题上。
矩阵
,其中
表示文本
在主题
上的概率。
LDA的图模型结构如上图1所示,在LDA模型中,一篇文档生成的方式如下:
1) 文档规模的大小服从Poisson分布,记作
;
2) 文档
主题分布参数的生成
,即狄利克雷分布生成文档
的K维主题向量
,其中狄利克雷分布参数用
表示。这个操作需要重复N次,生成所有文档主题随机分布;
3) 生成文档特征词
:以根据文档的主题向量
的多项式分布
选择该词对应的某一隐藏主题
,接着以多项式概率分布
即
,从主题z中择某一特征词
。
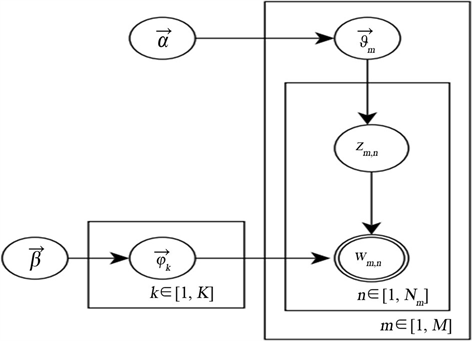
Figure 1. Three layer Bayesian network model diagram of LDA
图1. LDA的三层贝叶斯网络模型图
3.3. LDA主题模型拓展
LDA主题模型对特征维度较高的评论词进行降维处理,对于评论文本信息,在使用LDA主题模型进行降维之后,可以获得每个文本关于主题的概率分布。记
为电影i评论文本信息主题的概率分布。
如果仅仅使用LDA主题模型,虽然对类似的词语进行归类合并,但也只能获取数量有限的K个主题来实现对文本内容的概述。这样的特征较为宽泛,粒度较为粗糙。即
为电影i评论文本信息关于主题的粗粒度特征。如果在对文本进行预处理后,将每个特征词都作为文本的特征,那么就会导致粒度太细致而具有稀疏性。对此,本文通过粗粒度主题特征选取每个主题下m个主题关键词作为细粒度特征,即
为物品i评论文本信息关于主题关键词的细粒度特征。将粗、细粒度特征的结合综合特征记为
,可增强文本描述能力。
对评论文本信息
进行TF-IDF值的计算选取细粒度特征
定义一种运算:
(1)
其中A是
的矩阵,B为
矩阵,R为
的矩阵。
。
矩阵
,矩阵
。
其中
表示词语
在文本
上的
值。矩阵
,其中
,
则
,
即为文本
的细粒度拓展主题关键词特征向量。
3.4. 个性化产品推荐列表
在用户的诸多信息中,评分是用户最简单、量化的偏好,因此在大量的推荐系统研究中均使用评分矩阵来分析用户对物品的偏好,但是不同用户的评价标准不同,只有在研究特定某一用户时,同一用户对不同物品的评分信息能够直接、有效的反映该用户对不同类型物品的喜好程度。
在给具体某用户推荐物品时还需要考虑该用户历史评分,把用户
对物品j的评分用
进行表示,用户历史记录中有打分行为的物品数目为n,用户
对物品j的评分偏好记为
,则计算公式如下:
(2)
除了以数值形式呈现的评分数据,用户的历史评论数据中也包含用户的偏爱信息,在分析具体某个用户的兴趣偏爱时,由于用户的历史评论数据量一般并不是很庞大,很难精准的分析出用户对物品某个特征的喜爱程度,存在数据稀疏的问题,因此本文分析用户对主题的偏爱,主题包含一类相似的特征,用户主题偏爱能够反映用户对同一主题下物品相似特征的喜爱程度,同时能够有效的解决数据稀疏问题。
用户主题偏爱度的获取方法是将每个用户历史评论集合作为该用户的评论文档,如用户
的评论文档记作
。使用LDA主题模型将所有用户的评论文档进行降维,可以获得用户评论文档关于主题的K维分布向量
。如果用户无历史评论信息或者评论文本数据过于稀疏的情况下,
均设置为1。在LDA主题扩展时是将同一物品的评论作为同一文档,研究物品评论主题分布,用户兴趣分析时是将同一用户的评论文本作为同一文档,研究用户评论主题分布,但原始语料是相同的,描述物品也相同,所以主题维度K的选择应该等同3.3节物品评论的主题维度K。
推荐系统中物品特征提取、降向量维规格化后,需要计算物品之间相似度,计算不同产品之间相似性的方法有很多种。如余弦相似性、皮尔森相关系数和欧氏距离等,欧氏距离是直观且被广泛使用,它表示N维欧氏空间中两个点之间的距离,本文利用欧氏距离计算项目的相似性。
(3)
在个性化推荐中目标用户
历史记录中包含物品j,其评论文本
的主题拓展特征向量可以表示为
,同理对目标用户
历史记录中不包含的物品i,其评论文本
的主题拓展特征向量也可以表示为
,物品i和物品j评论文本主题拓展特征向量的欧几里德距离相似度:
(4)
已知用户
的主题偏爱向量为
,用户
对物品j的评分偏好记为
,在为用户
进行个性化推荐时,在物品评论文本相似度计算中加入用户主题偏爱和评分偏好权重后的物品相似度计算公式为:
(5)
其中
是物品i的正向评论率,是物品i正向评论条数与其总评论条数比值。
4. 实验及结论
实验数据采用爬虫技术从豆瓣电影网站(https://movie.douban.com)采集共1000部电影,8,233,422条评论信息,并获取用户对电影评分数据。其中部分电影及用户评论信息分别如表1、表2所示。实验训练测试样本4:1,为300名目标用户推荐N部电影,与评测数据对比,计算推荐准确率、召回率信息。

Table 1. Part of films’ information
表1. 部分电影信息
Table 2. Part of users’ information
表2. 部分用户评论信息表
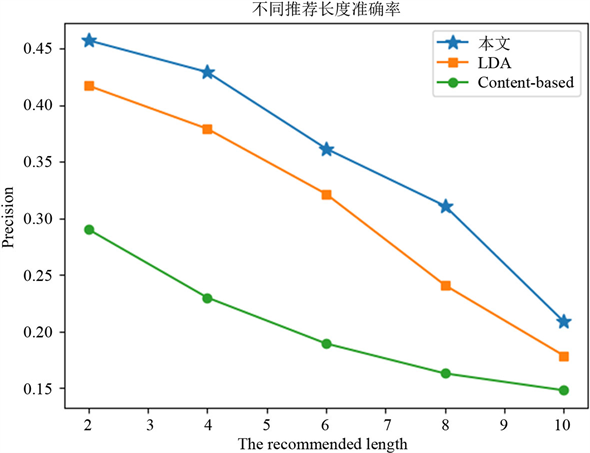
Figure 2. Recommended precision under different recommended lengths
图2. 不同推荐长度下推荐准确率
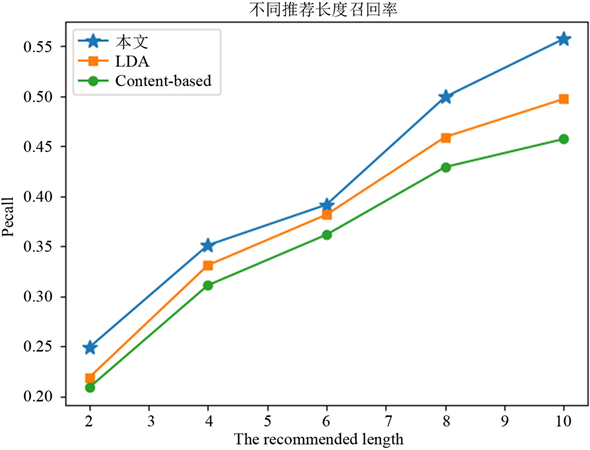
Figure 3. Recommended recall under different recommended lengths
图3. 不同推荐长度下推荐召回率
本文算法与基于内容的推荐算法和基于LDA主题模型的推荐算法做比较。Top-N不同推荐长度下推荐准确率、召回率对比分别如图2、图3所示,在比较不同算法在相同的推荐长度下,采用本文基于评论文本LDA主题扩展的个性化推荐算法推荐相对基于评论LDA主题推荐和基于内容的推荐算法在推荐长度相同的情况下,准确率和召回率均有所提高。可见用户评论文本中包含有效的用户观点,同时基于LDA推荐算法和LDA主题扩展推荐算法之间的比较也能说明主题扩展特征词加强了文本的描述力,提高了推荐的准确性。