1. 引言
计算流体力学(CFD)在航空工业中扮演着越来越重要的角色。随着近些年的发展,CFD能够模拟出许多现实的场景。但是对于复杂系统,需要采用高精度的算法。龙格库塔间断有限元算法是一种高精度的流场算法,具有能够捕捉间断,处理网格悬点等优点 [1] 。然而由于计算量大,往往需要花费很长的时间完成流场求解。
人们提出了许多方法来减少CFD求解时间,并行计算就是其中一种很好的方法。CPU并行加速在工业应用上已经非常成熟,然而建立大规模CPU并行计算集群非常昂贵。因此GPU是一种更好的选择。近年来,GPU在科学计算上表现出了重大的潜力。CUDA是Nvidia公司2007年推出的GPU并行计算平台和编程模型 [2] ,实验表明,能够显著提高计算性能。
Klöckner A等人在单个GPU上构建了高效的高阶间断有限元解算器,并在三维四面体网格上求解了麦斯威尔方程,与同一代的CPU相比达到了近50倍的加速比 [3] ;何晓峰等在单个GPU上,使用RKDG方法对二维欧拉方程进行了加速 [4] ,与CPU相比获得了25倍的加速比;Dawei Mu等人在单个GPU上,使用间断有限元方法对三维弹性地震波方程进行了加速 [5] ,并与CPU并行程序进行了比较,在单精度下相比1个、2个、4个、8个CPU并行程序获得的加速比分别为12.9、6.8和3.6。本文在此基于多GPU对RKDG方法进行加速。论文结构安排如下,我们首先介绍了龙格库塔间断有限元方法和CUDA程序概述,然后介绍了单GPU以及多GPU上基于CUDA的间断有限元方法求解,最后分别在一个、两个和四个GPU上进行了求解,统计了耗时,并与CPU结果进行了比较。
2. 龙格库塔间断有限元求解
本文中,我们考虑二维双曲方程,格式如下:
其中
,
,
ρ,P,H和E分别为密度,压强,单位体积的总焓和单位体积的总能。
选择解函数和试探函数空间如下:
K表示三角形剖分单元,
表示单元K上次数不高于N的多项式。在三角形单元K上取基函数
,则解函数
可表示为:
,
本文处理三阶精度的间断有限元方法,选取三角形单元K上的一组正交基函数如下 [6] :
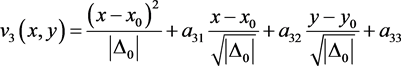
上式中正交基函数的系数
由待定系数法求得。由于基函数在单元K上是正交的,所以单元质量矩阵
为对角阵。计算过程中通量采用间断有限元方法离散,原双曲方程可以写成半离散形式如下:
使用三步Runge-Kutta方法对上式进行迭代求解稳定解。
3. GPU加速
3.1. Cuda概述
CUDA是显卡制造商Nvidia公司2007年推出的并行计算平台和编程模型,开发人员可以使用c/c++语言来为CUDA架构编写程序。CUDA提供host-device的编程模式以及非常多的接口函数和科学计算库,通过执行大量的线程来达到加速效果。CUDA通过线程格来管理线程。线程格包含多个线程块,线程块包含多个线程。线程格和线程块可以是一维、二维或者三维结构。本文使用一维线程块结构,其线程类似于一个二维的像素数组,如图1所示。
线程索引号为:
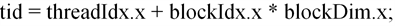
其中threadIdx.x表示线程块中的线程编号,blockIdx.x表示线程格中线程块的编号,blockDim.x表示每个
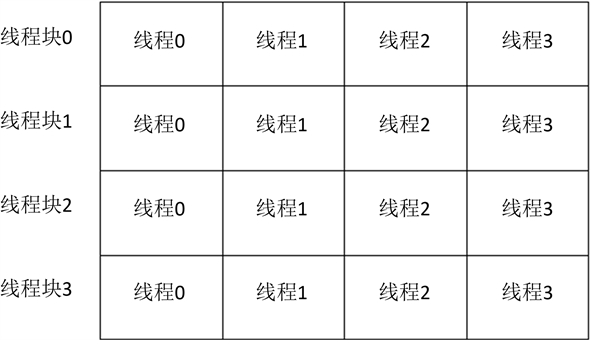
Figure 1. Two-dimensional organazition of blocks and thread
图1. 线程块集合与线程集合的二维组织形式
线程块中的线程数。
3.2. 单GPU加速
单GPU加速时,由于CUDA支持大量的线程,因此选取CUDA线程数等于三角形网格个数。每个线程根据自己的全局索引号计算相应的网格单元即可。另外,还需要在GPU与CPU之间进行数据传输,所以程序的流程图如下:

上式中kernelFun即为核函数,将其循环迭代到流场收敛为止。
我们通过核函数依次求解时间步长、计算守恒量、处理边界条件、计算体积分守恒残差、计算通量、计算单元各条边上的积分残差、最后执行Runge-Kutta时间推进。
3.3. 多GPU加速
在多GPU下,首先将网格进行区域划分,划分后一个GPU对应计算一块区域。划分后可以不对网格进行处理直接计算;也可以先处理网格,将本地网格进行重排序,并重新生成邻接信息等。以图2的网格为例进行说明,我们将它沿中间划分成两个区域。
若直接计算,需要在每个计算节点上储存所有网格单元信息,即需要储存全部8个单元。计算时,只处理属于分配给相应节点的网格,第一个计算节点只计算单元编号为1、2、5、6的流场变量值。这样没有打乱网格单元的邻接关系,操作方便。但是,需要储存所有的三角形单元信息并传输到GPU上,浪
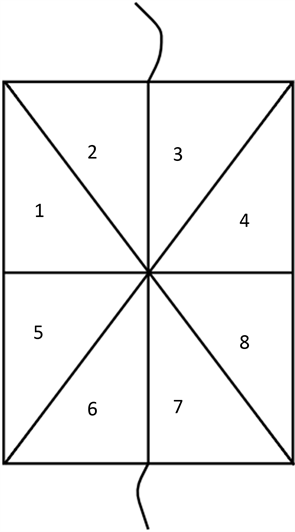
Figure 2. Triangle unstructured mesh
图2. 三角形非结构网格示例
费内存。GPU个数的增加并不能增大问题求解的规模,没有充分利用多个GPU计算的优势。同时,划分后每个区域的单元编号不再都是连续的,因此每个GPU上处理的单元在内存上也不是连续的。当warp请求访问位于不同地址的数据时,数据是非连续的,无法合并访问,大大影响访存的效率 [7] 。
若先将网格进行处理,在每个计算节点上,去除掉其他节点对应的网格,比如第一个计算节点上只需要储存编号为1、2、5、6的单元,所需的储存空间小了一倍。将分配到此节点的网格单元重新连续编号,即将5、6号单元重新编号为3、4,这样每个节点上的网格单元都是连续存储的,并重新生成单元其他信息,再进行计算。缺点是处理网格会稍微麻烦,但是节约了内存,还提高了访存效率,总体上,效率会远高于前一种方式。因此本文采用这种方式。
计算过程中,需要在网格边界处进行信息交换,采用MPI进行通信 [8] 。MPI是目前最流行的用于并行编程的消息传递接库标准。该模型底层是一组处理器,每个处理器有独立地址空间而且只能访问本地的指令和数据。各个处理器的不同进程间交互必须通过消息传递操作来实现。MPI定义了点到点通信、集合通信、并行I/O等操作。
在信息交换时,我们先将数据从GPU拷贝到CPU,再通过MPI在CPU之间交换,最后将数据拷贝回GPU。由于本文处理的是定常问题,因此不需要每一个时间步步都进行交换。同时MPI采用非阻塞通信,上一个时间步发送和接收消息,到下一个时间步才使用MPI_WaitAll来同步信息的交换。由于cuda核函数也是异步进行的,因此这样可以较好的覆盖CUDA的计算和MPI消息传递,提高并行效率。
4. 数值实验
求解naca0012翼型在来流马赫数0.4,攻角5˚下流场收敛时的密度。网格规模为37,360个三角形单元,如图3所示。
分别在CPU以及不同个数GPU上进行了计算,CPU使用Intel Xeon X5690 (主频3.47 Hz),GPU使用Nvidia Tesla k20 GPGPU,含有2496个流处理器。GPU个数等于网格划分后的区域个数,两个GPU
对应的网格划分结果如图4所示,四个GPU对应划分后的四个区域如图5所示。计算耗时统计如表1所示。结果表明,GPU个数并不影响最终的流场解,流场解的密度等值线如图6所示。
结果显示,单个GPU对比单个CPU获得了33倍的加速比。采用不同GPU个数相对CPU加速比如图7所示。发现随着节点个数的增加,加速比逐渐增加,能够很好的处理大规模的计算。但是由于多个

Figure 4. Mesh divided into two parts
图4. 网格划分为两个区域

Figure 5. Mesh divided into four parts
图5. 网格划分为四个区域

Table 1. System resulting data of standard experiment
表1. CPU及GPU上运行时间统计
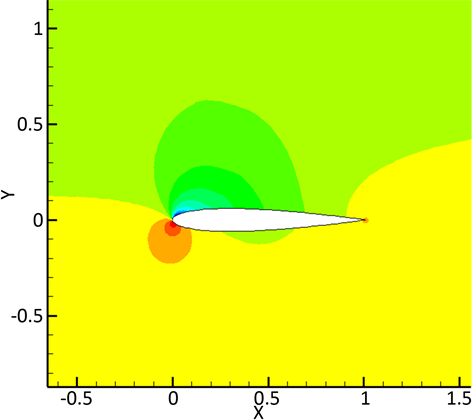
Figure 6. Density contour map of solution
图6. 解的密度等值线图
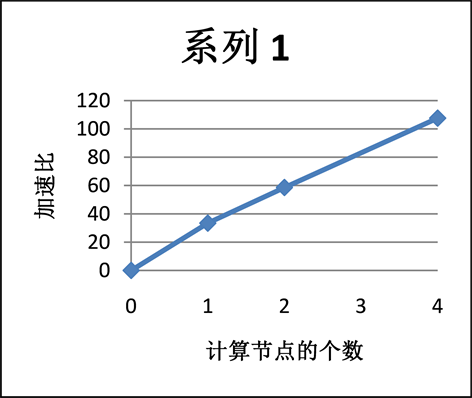
Figure 7. Speedup ratio of different numbers of GPU relative CPU
图7. 不同GPU个数相对CPU加速比
节点计算会需要节点之间的协调和通信等耗时操作,因此加速比并没有和节点个数成正比关系。
5. 结论
本文基于CUDA采用多GPU对龙格库塔间断有限元方法进行了加速。分别测试了一个、两个和四个GPU,并取得了较好的加速效果。充分利用了多个GPU的特性,可以克服规模增大后单个GPU显存不足的情况。同时,本文针对定常问题,采用数据交换的下一个时间步同步并处理交换的信息,减少了通信的代价,增加了并行效率。