1. 引言
随着网络技术的不断发展和网络应用范围的不断扩大,对网络的各类攻击与破坏也与日俱增。由于网络攻击手段的多元化、复杂化和智能化,单纯依赖防火墙等静态防御已难以胜任网络安全的需要。入侵检测是保证网络和系统安全的重要手段,来避免由入侵者(如攻击者和黑客)通过一些技术手段对网络和系统来进行的非法操作。随着传输数据爆炸式增长和高速网络广泛运用,传统的入侵检测方法已经过时并且不能满足目前的检测要求。此外,当一个入侵检测系统工作的时候不应该影响网络系统的正常运行,特别是在大数据处理和高速网络环境。由于现在的网络和系统环境复杂,入侵检测系统不仅能有效的检测入侵而且还需要具有自适应机制。针对这个问题,本文给出了一种自适应选择入侵检测策略的方法并给出相应的模型。模型中使用了孤立森林算法和谱聚类算法。
本文组织如下:第一节为相关工作,第二节介绍了模型结构及自适应策略,第三节和第四节主要描述了孤立算法和谱聚类算法,第五节为数据处理,第六节主要是实验和仿真,最后一节为总结和未来展望。
2. 相关工作
关于入侵检测的研究,文献 [1] 阐述了一个入侵检测系统(IDS)的通用模型,它将一个入侵检测系统分为事件产生器、事件分析器、响应单元、事件数据库。当前的入侵检测概述技术和相关问题中提出 [2] ,主要的有基于分类的方法是将所有流量分类为正常或恶意来减少误报和漏报报警。例如,通过规则匹配如源IP地址、目标IP地址、源和目标的端口号等来形成入侵警报 [3] [4] ,缺点是漏报率高。另一类指的是通过管理员及专家系统判断 [5] [6] 。这个方法主要优点是降低了误报率,但是需要专家知识来判断,这个过程消耗时间过长。近年来数据挖掘和机器学习方法已被用于入侵,来改善现有系统的性能 [7] [8] [9] ,利用这些机器学习算法来分类入侵警报,例如使用聚类解决当前的问题。文献 [10] 首先确定两个最佳的初始聚类中心然后利用最大、最小距离的层次聚类算法和DBI指标确定剩余初始聚类中心,解决了k-means算法初始K个中心不容易确定,容易导致局部最优的问题。这些研究大都通过改进聚类算法增强检测效果,一方面增加了算法的复杂度,另一方面这些算法存在参数确定繁琐且不能保证最优和动态改变。在自适应安全方面,文献 [11] 提出了自适应安全机制。自适应安全是指系统采用非固定的安全工作模式,为获得最佳服务性能,能够根据其状态或环境的变化动态调整运行行为和安全规则。文献 [12] 采用哈休控制图来确定系统环境的安全状态,但是只选择了每秒非正常网络连接的个数作为控制图的统计对象,对于系统环境的安全状态还需要进一步确定。文献 [13] 利用agent技术来确定系统可能存在的环境状态,通过关联规则算法和时序序列算法从大量数据挖据若干模式,但是没有考虑到正常/异常库的划分。
3. 自适应策略
3.1. 自适应策略的必要性
目前许多入侵检测系统都是采用一种检测策略,用于检测所有环境,然而在检测强度与范围上没有改变。这使得系统的误报率与漏报率有时比较高,从而降低了入侵检测的可信度。这个问题可以通过自适应策略的思想来改善,检测策略随着环境的改变而调整,不同的环境状态对应不同的检测策略。
3.2. 自适应策略的描述
自适应策略分为状态空间以及策略空间。状态空间是用来描述系统环境,策略空间用来表示可能采用的策略。状态空间的某一环境状态与策略空间的策略存在映射关系。策略
流程图如图1。
3.3. 状态空间与策略空间
环境状态E可以表示为
。
其中表示某
个环境变量,环境状态由多个环境变量组成。典型的环境变量有cpu的使用率,网络连接数等。
状态空间是由若干的环境状态的集合,状态空间C可以表示为
。
策略空间是由各种策略组成的集合,策略空间P可表示为
,其中
表示某个具体的策略。如本文的孤立森林检测方法和谱聚类检测方法。
3.4. 自适应策略选择
安全阈值是用户和系统行为根据某种属性计数,如一种特定类型的网络连接数、企图访问文件数、访问文件或目录次数和访问网络系统次数等。对于安全阈值的判断是在一个特定的时间间隔内进行的。这个时间间隔在时间上可以是固定的,例如,阈值在每天的特定时间重置为0;也可以在一个滑动窗口上运行,例如,每隔1小时进行度量。
传统的IDS是让所有的网络环境状态对应于一个策略,不具备自适应性。自适应策略是在构建状态空间和策略空间的基础上,对于环境变量设置阈值。大于安全阈值的情况,采用孤立森林的方法检测;在小于等于安全阈值的情况下,采用谱聚类的方法进行检测。
4. 孤立森林的检测方法
南大周志华老师在2010年提出一个异常检测算法Isolation Forest,在工业界很实用,算法效果好,时间效率高,能有效处理高维数据和海量数据。算法起源于08年的一篇论文《Isolation Forest》 [14] ,这
论文由澳大利亚莫纳什大学的两位教授Fei Tony Liu, Kai Ming Ting和南京大学的周志华教授共同完成,而这三人在2011年又发表了《Isolation-based Anomaly Detection》 [15] ,这两篇论文算是确定了这个算法的基础。孤立森林是由许多孤立树组成,最后综合所有孤立树的结果。
4.1. 孤立森林用于入侵检测
具有线性时间复杂度,对内存要求较小,能够处理极大的数据量和大量不相关属性的高维问题。这与入侵检测实时性、能够处理大量数据的要求相吻合,所以可以应用于入侵检测当中。
4.2. 孤立森林原理
异常数据相对于正常数据是少而且不同,所以可以使用称为孤立树(iTree)的二叉树结构来有效分割实例。由于易于分离,异常数据更有可能与iTree的根源接近,而正常数据更有可能在iTree较深端被隔离。iForest由多个iTree组成,异常数据就是那些在孤立森林中具有短的平均路径。
4.3. 详细说明
4.3.1. 异常森林构建
算法步骤如下图2 [15] :
1) 从训练数据中随机选择
个点样本点作为子样本,放入树的根节点。
2) 随机指定一个属性(attribute),在当前节点数据中随机产生一个切割点p——切割点产生于当前节点数据中指定维度的最大值和最小值之间。
3) 以此切割点生成了一个超平面,然后将当前节点数据空间划分为2个子空间:把指定属性里小于p的数据放在当前节点的左孩子,把大于等于p的数据放在当前节点的右孩子。
4) 在孩子节点中递归步骤2和3,不断构造新的孩子节点,直到孩子节点中只有一个数据(无法再继续切割)或孩子节点已到达限定高度(height limit)。
IF采用二叉树去对数据进行切分,数据点在二叉树中所处的深度反应了该条数据的“疏离”程度,整个算法总体可以分为训练和预测两步。
孤立树训练阶段:
对于每个孤立树,从总数据中无放回抽取n个数据进行训练,之后随即选取一个特征,在这个特征值所有范围内随机选择一个值,对样本进行划分。小于这个值划分到节点的左边,大于等于该值的划分到节点右边,然后再对左右两个数据集重复上面的过程,直到满足终止条件一数据不可分(只有一个数据样本或全部样本相同)或达到树的高度
。
用同样的方法,随机选择不同的样本训练得到多个树。
预测阶段:
把测试数据在每个iTree上沿着对应的条件分支往下走,直到达到叶子节点,并记录这过程中经过的路径长度h(x),即从根节点,穿过中间的节点,最后达到叶子节点所走过的边的数量,最后计算出异常分数。
4.3.2. 异常分数计算
先沿着一棵iTree,从根节点开始按不同特征的取值从上往下,直到到达某叶子节点。假设iTree的训练样本中同样落在 x 所在叶子节点的样本数为T.size,则数据x在这棵iTree上的路径长度h(x),公式(1):
。
公式中,e表示数据x从iTree的根节点到叶节点过程中经过的边的数目,C(T.size)可以认为是一个修正值,它表示在一棵用T.size条样本数据构建的二叉树的平均路径长度。一般的,C(n)的计算公式(2)
如下:
。
可用ln(n − 1) + 0.5772156649估算,这里的常数是欧拉常数。数据x最终的异常分值 [15] Score(x)综合了多棵孤立树的结果公式(3):
。
公式中,E(h(x))表示数据x在多棵 iTree的路径长度的均值,
表示单棵iTree的训练样本的样本数,
表示用
条数据构建的二叉树的平均路径长度,它在这里主要用来做归一化。
从异常分值的公式看,如果数据x在多棵iTree中的平均路径长度越短,得分越接近1,表明数据x越异常;如果数据x在多棵iTree中的平均路径长度越长,得分越接近0,表示数据x越正常;如果数据x在多棵iTree中的平均路径长度接近整体均值,则打分会在0.5附近。
5. 谱聚类的检测方法
5.1. 谱聚类用于入侵检测的可行性
数据挖掘是从海量的数据中挖掘出潜在知识的过程,聚类方法是一种无监督的学习技术,可以在无标记的数据集上建立入侵检测模型,非常适应于实际情况。谱聚类算法具有可伸缩性好、能够处理不同形状的数据集、能够处理高维数据等特点,非常适合应用于入侵检测。
5.2. 谱聚类算法
谱聚类 [16] 是把聚类问题转化为对图的划分,把数据看成空间的点,将点之间的相似度量化为相应顶点连接边的权值,最后得到一个基于相似度量的加权图。之后采用基于图论的划分方法使得划分后的子图内部权值和尽量大,不同子图之间权重和尽量小,从而实现聚类。
由于图的划分属于一个NP问题,解决方法是将其转换为求解相似矩阵得到的拉普拉斯矩阵的谱分解。
第一步:根据高斯函数来得到数据的相似矩阵。
第二步:求解拉普拉斯矩阵L。
第三步:求出矩阵L前k个特征值与之对应的特征向量。
第四步:将这些特征向量按照行标准化,形成特征矩阵F。
第五步:将矩阵F的行向量转化为单位向量,得到矩阵Y。
第六步:将Y每一行看作是空间的一个点,用其他聚类算法(如K-means算法),得到K个聚类
K-means算法步骤:首先从n个数据对象任意选择k个对象作为初始聚类中心;而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止。一般都采用均方差作为标准测度函数。k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。
5.3. 正常/异常库划分
因为正常行为记录数目远远大于异常行为数目,正常行为记录的聚类应该比较大分布密集,因此将聚类中数目大于N的聚类为正常聚类,其他的为异常,经过一定形式变换,形成正常行为库和异常行为库。
6. 数据预处理
6.1. 标准化正交处理
对原始数据进行标准化处理。经过处理的数据符合标准正态分布,即均值为0,标准差为1,转化函数式(4)为:
其中
为所有样本数据的均值,
为所有样本数据的标准差。这样可以去除多组数据之间的差异性,从而使得多组数据可以进行比较。
6.2. 离散数据连续化
两种属性类型:normal设为0,error为1。
3种类型如protocol_type:tcp,udp,icmp.
Tcp: protocol_type1 = 1, protocol_type2 = 0, protocol_type3 = 0;
Udp: protocol_type1 = 0, protocol_type2 = 1, protocol_type3 = 0
7. 实验仿真
实验环境在PC机上(内存为4G,CPU为CORE-i53470,操作系统为Windows 7),采用python编程。
7.1. 系统状态与安全阈值
系统状态描述如图3所示。
安全阈值设定:可以把30分钟内的网络连接数设为20次 [17] 。
7.2. Isolation forest检测
tcpdump抓包如图4所示。
使用wireshark查看tcpdump抓到的包,可以看到针对同一个主域名,包含了大量的子域名请求,而
这些子域名负责携带外发数据。然而pcap这种特殊的文件格式并不能直接作为iforest检测算法的输入数据,所以需将其转化为iforest算法所能够识别的文本文件。对其进行特征处理,从中提取解析的dns域名,srcip个数,dstip个数,报文长度等特征。
数据输入如图5所示。
数据输出如图6所示。
根据iforest算法中的异常分数为1得到可能为异常dns查询信息(dns流量中可能潜在攻击,比如dns tunnel),如图7所示。
根据wireshark对“vxcache.com”抓包分析,可以看出一段Label的字节数为0 × 80——即128字节。而DNS请求的数据结构中队Label的长度 [18] 是有限制的:Labels must be 63 characters or less (参考RFC882 [Page 30])。Label被允许的最大长度只有63字节——即0 × 3f,只要大于这个值,即为异常。
7.3. 谱聚类
在选取的KDD数据集中有43个属性,但是有些属性对于入侵检测是无关的,Srinivas Mukkamala [19]
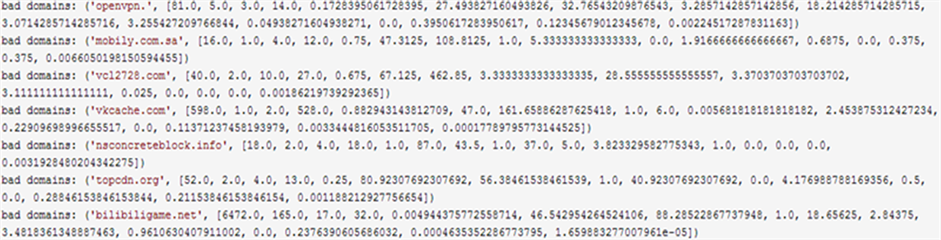
Figure 6. Abnormal DNS query information
图6. 异常DNS查询信息图
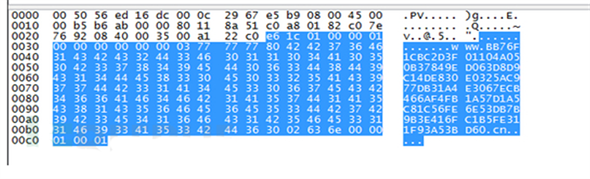
Figure 7. Analysis of abnormal DNS query information
图7. 异常DNS查询信息分析图
等人利用svm方法通过实验指出在KDDcup1999数据集中有duration,src_bytes,dst_bytes,urgent,count,srv_count,same_srv_rate,dst_host_count,dst_host_srv_count,dst_host_same_srv_rate, dst_host_same_src_port_rate,protocol_ type 和 service,其中既包含了数值型属性,也包含了符号型属性。本文的实验也是基于这13个特征,采用MATLAB 7编程。
7.3.1. 谱聚类效果
原始数据如图8所示。
聚类之后如图9所示。
由图可以看出正常行为数量远大于异常行为数量。
7.3.2. 谱聚类算法与k-means算法比较
Kddcup99数据集包括四种攻击数据集和正常数据集如表1所示。
KDD CUP1999数据集是当前入侵检测领域权威的测试数据集。数据是来源于1998年DARPA入侵检测评估计划,并包含约4,900,000个数据实例。 对于每个TCP/IP连接,有41个特征。一些特征是基本的(如:持续时间,协议类型等),而其他特征是通过使用一些领域知识获得的(例如:失败的登录尝试次数等)。在所有41个特征中,有8个离散特征和33个连续特征。攻击分为四大类:
DOS (拒绝服务),如死亡ping攻击;U2R (User to Root),如弹出攻击;R2U (远程用户),如访客攻击;PROBING,例如端口扫描攻击。
选择7996个实例作为来自原始数据的训练集。在这个训练集有7249个正常实例和747次攻击事件。选择了四组数据,表2为测试数据集的数据量。
检测率和误报率,这是评估入侵检测指标的标准。在实验中,检测率被定义为系统检测到的入侵实例的数量除以在测试集中入侵实例数量;在测试集中。误报率定义为总数错误分类为入侵的正常实例的数量除以正常情况的总数,算法比较如表3所示。

Table 1. Attack Types and Number in Data Sets
表1. 数据集中攻击类型和数目
Table 2. The amount of data in the test data set
表2. 测试数据集中数据量
Table 3. Comparison of algorithm performance
表3. 算法表现比较
从表3可以看出,在检测率方面谱聚类算法优于k-means算法。因为k-means算法适合处理容易分类的数据,而那些难以分类的数据可以通过谱聚类算法进行处理,所以在入侵检测当中谱聚类具有更好的性能。
8. 总结与未来工作
本文针对传统入侵检测适应性差等问题,通过对系统环境描述来选择检测策略,将孤立森林算法与谱聚类算法相结合应用于入侵检测,最后实验表明提高了入侵检测效果。但是对系统行为记录及其分布作进一步的研究,使不同类型的行为记录能更好区分,划分出的正常/异常库能够更加准确反映系统状态。
参考文献