1. 引言
国内对于海外仓的研究资料,仍仅限于跨境电商方面的研究。对于传统商贸公司的海外仓的研究稀少,而此类海外仓由于运输时间过长和库存管理方法原始等因素,存在严重的库存管理问题。本文通过对仓库的需求预测方法的探索,找到适合各设备的短期需求预测方法。从而达到优化海外仓库存的目的,降低库存成本并满足市场需求。
有关预测的理论已经相对完善,但新的预测技术仍然层出不穷,仅时间序列预测的技术就超过60种,因此决策者面临的是信息过剩的问题,需要考虑的是选择什么样的技术最适合自己的数据。
常见的需求预测,根据预测方法进行分类,可以分为定性预测和定量预测两大类。定性预测是指在数据资料不足且难以获得时,凭借预测者的知识、经验来对未来发展变化的趋势和特点做出主观判断。其优点是简便易行,不需要复杂的公式和工具,但缺点也同样明显,主观性太强,不同预测者差别很大,且无法测试预测的精度。定性预测的方法很多,如集体讨论法、德尔菲法、市场研究法等。定量预测适用于原始数据比较充裕或者数据来源多且稳定的情况,选择和建立适当的模型,并根据模型估计出对象未来的发展变化趋势。定量预测需要大量的历史预测值作为依据,建立适当的数学模型,推断或估计预测目标的未来值。定量预测的优点是预测精度高,缺点是对数据的质量要求高。定量预测的方法很多,如回归分析法、时间序列法等。
2. 需求预测
2.1. 预测方法介绍
1) 定性预测
定性预测的主体是人,依据专业知识和获取的资料,结合个人的经历和经验进行相应规律的探寻。定性分析的优点是充分考虑决策人的宝贵经验,并且不需要太多的历史数据,但缺点在于只能得到比较宏观的预测数据,而对具体的型号和地区的销售预测往往偏差较大。
常用的定性分析方法有:
一般预测法:从基层销售人员或者销售渠道收集未来一段时间内对客户购买的预测,并进行汇总,进而形成全区域或全公司的预测数据。
集体讨论法:充分发挥集体智慧的优势,由企业内部不同级别的管理者和工作人员在公开的会议上针对A一个具体的需要预测的问题进行集中讨论和自由交流,最终综合各个人员的意见得出结论。集体讨论法可以避免个人进行预测时的偏差,但也存在容易被高层管理者意见主导的可能。
德尔菲法:又称专家调查法,是通过对专家背靠背(不见面,不协商)的匿名方式进行预测的一种方法。它具有广泛性、匿名性、收敛性和反馈性的特点。德尔菲法可以用于新产品的需求预测,在经过不少于三轮的预测后可以得到比较满意的预测结果。
类比法:一些全新的产品没有历史销售记录,可以用类比法进行预测,在一种已知产品的基础上对另外一种产品的需求进行推导。类比法又可以分为纵向类比法和横向类比法。纵向类比是参考历史上其他时期的销售数据来判断市场趋势,横向类比是参考同一时期其他产品的市场销售数据来进行预测。使用类比法可以一定程度上避免产品的风险和不确定性。
市场研究法:邀请专业的第三方专业市场调研机构进行对本企业的情况进行市场调研,在调研的基础上对企业未来销售情况进行预测。
2) 定量预测
a) 移动平均法
移动平均法是最简单的预测方法,预测值是历史销售数据的平均值,随着时间的推移,预测值也会不断进行更新 [1] 。运用移动平均法进行预测可以减少由于订单的突然波动对预测结果的影响。通过判断历史各期数据对最终预测结果的影响程度是否相同,移动平均法还可以进一步分为简单移动平均法和加权移动平均法。
简单移动平均法的公式为:
式中,
是对将来第t期的预测值,
是过去时期的实际数据,其中
是最近一期的实际数据,
是n个时期以前的实际数据。简单移动平均就是利用离当前最近的n个时期的实际数据来预测下一时期的值,n选取的不同会影响预测的效果。
给简单移动平均中每个组成因素赋予不同的权重,并且令权重之和为1,即可得到加权移动平均的公式:
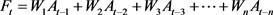
式中,
是这n个时期实际数据的权重,并且
。一般而言,距离当今最近的时期会赋予较高的权重,距离较远的时期赋予较低的权重。权重值选取的不同会影响预测的结果。
移动平均法简便易行,但它的缺点在于移动周期的选择会影响到平滑波动的效果,加大移动周期会使得最终的预测值对数据变动不敏感。另外,移动平均是基于过去的水平得来,不能很好地反映出总的趋势。最后,如果同时预测未来多期数据,由于后一期预测是基于前一期的预测得到,因此如果前一期的预测存在误差,会导致误差的累加,从而影响预测的准确性。
总的来说,移动平均法适合于预测未来时间相对较短、上下波动不大、趋势较为稳定的产品销售数据。
b) 指数平滑法
移动平均法的主要缺点在于需要持续输入大量的历史数据,而在许多预测当中,距离当前最近的数据远比很久以前的数据重要 [2] 。在指数平滑中,仅需要三个输入就可以实现对未来的预测:最近一期的预测值,最近一期的实际值,以及平滑常数α。α决定了平滑的水平,也决定了对于预测量和实际量之间差异的反应速度。指数平滑法能够提供更加快捷和准确的预测方法。
在短期预测中最有效的方法就是指数平滑法,该方法只需要得到很小的数据量就可以连续使用 [3] 。指数平滑法在同类预测方法中被认为是最精确的,当预测数据发生根本性变化时还可以进行自我调整。指数平滑法适用于从不太平稳到十分稳定的时间序列,平滑常数需要进行调整以适应不同程度的稳定性。
简单指数平滑法的公式如下:
式中,
是对第t个时期的预测值,
是对之前一个时期做的指数平滑预测值,
是前一个时期的实际值。
指数平滑法考虑了一定时间段内销售量的权重,然后利用移动平均法计算考虑了权重以后的销售量,从而得到最终的预测数据。指数平滑法相对比较简单,只需要一个实际销售数据和上一个时期的预测数据就可以进行计算,一般用于比较平稳的时间序列。
如果在A一特定时间范围内获取的数据信息有较为明显的上升或下降的表现,那么这也会导致预测值和实际需求之间出现不相符的情况,这就可以通过添加趋势修正值在一定程度上改进指数平滑的预测结果,也就是Holt指数平滑模型,其公式为:
其中,
,
,
是对t时期的指数平滑预测值,
是t时期的趋势,
是对t时期包含趋势的预测值,
是对前一个时期包含趋势的预测值,
是前一个时期的实际值,α是平滑系数,δ是趋势平滑系数。
另外,若时间序列数据中体现出季节性的影响,还需要添加修正季节的因素,讲季节性与数据中A一段特定时间相联系,这就是Holt-Winters指数平滑模型。
在实际的预测活动中,需要根据历史数据的特征进行合适模型的选择,不同的选择带来的预测效果也不尽相同。
c) ARMA算法
ARMA模型中文全称为自回归移动平均模型,是研究时间序列问题中一类重要的方法,是目前最常用的拟合平稳序列的模型 [4] 。ARMA模型将序列值表示为过去值和过去扰动项的加权和,其理论模型如下:
其中,
是时间序列值,ε为扰动项。AMRA模型认为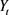 主要是受过去p期的序列值和过去q期的误差项的共同影响。
主要是受过去p期的序列值和过去q期的误差项的共同影响。
当时间序列为非平稳序列时,需要用ARIMA模型进行建模。ARIMA模型本质上与ARMA模型相同,是通过差分的方式将非平稳序列转化为平稳序列,再进行建模。
利用ARMA模型做时间序列分析流程如下图1所示 [5] 。
2.2. 机顶盒需求预测
本部分结合A公司2015年新推出的A款机顶盒在坎帕拉地区的销售情况,对上一节介绍的预测方法进行说明。T2机顶盒于2015年5月在非洲地区上市,历经两年多的销售,期间由于新一代产品的冲击销量逐年下降。下表1给出了T2机顶盒在非洲坎帕拉地区的销售情况,全部销售均由坎帕拉仓库负责出库和配送。
其中,2017年2月,由于仓库断货,无法统计当月实际销售情况或客户购买需求。在进行销售预测分析时,该异常值会影响预测模型的精度和结果,因此,本文以前后两个月的均值作为当月的实际需求代替异常值。
从需求统计图2中可以看出,Decoder-T2机顶盒刚上市阶段即为销售的高峰,随着其他新产品的陆续上市,该款机顶盒的销量逐渐下滑,整体趋势较为平稳。下面,本文将分别利用移动平均法、指数平滑法,以及ARMA法对Decoder-T2机顶盒的需求情况进行预测。
2.2.1. 移动平均法
从不同n取值预测结果来看(表2,表3、图3),各个曲线都较为平稳,平滑了实际销量波动的影响,n的不同取值总体来说差异不是很大,这与真实值本身的平稳性有关。在真实值波动较大的前8个月时间内,各移动区间的离差较大,预测的准确性较差。当实际销量趋于平稳之后,n的取值对预测的影响

Figure 1. ARMA (ARIMA) modeling flowchart
图1. ARMA (ARIMA)建模流程图

Table 1. Statistical table of sales in kampala warehouse of decoder-T2
表1. Decoder-T2机顶盒坎帕拉仓库销售情况统计表
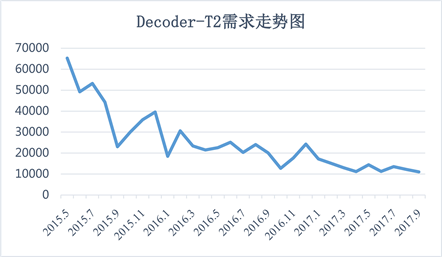
Figure 2. Sales number of decoder-T2 in kampala warehouse
图2. Decoder-T2机顶盒坎帕拉仓库销售情况
Table 2. Forecasting results of different intervals
表2. 不同移动区间的预测结果
Table 3. Forecasting results of different intervals
表3. 不同移动区间的预测结果(续)
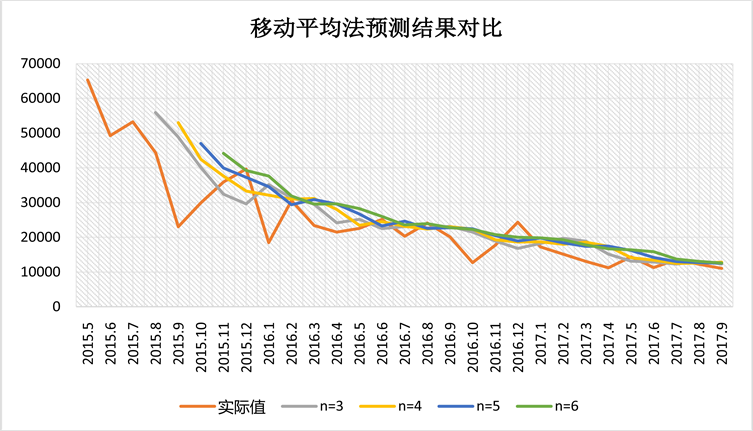
Figure 3. Comparison of deviation variation trend
图3. 离差变化趋势对比
较小,反映在离差趋势图像上各个曲线的趋势相近且取值相近。总的来说,从平均离差的数值上观察,n = 6时预测的结果相对较好。
2.2.2. 指数平滑法
指数平滑法中平滑常数a的选取对于预测结果有着非常的影响,在环境相对稳定的环境下,适合选择较小的a值;当环境变化较快时,需要选择大一些的a值,以适应环境的变化。本文分别选取平滑常数a为0.1,0.3,0.5和0.7四种情况,用指数平滑法对机顶盒销售数据进行分析和预测,平滑结果如表4和表5所示。
从分析结果(图4和图5)中可以看出,a = 0.1对数据的拟合效果较差,这可能是因为销售数据前期波动太大,致使a取值必须偏大才能适应环境的快速变化。预测结果图反映出a取值为0.3,0.5和0.7时的预测效果相当,在实际值趋于平稳后三者都有很良好的表现。综合而言,从离差的结果来看,a选择0.7预测效果更好一些。因此,我们选择a = 0.7对机顶盒数据进行预测。
2.2.3. ARIMA法
首先判断数据的平稳性,对序列的平稳性检验有两种方法,一种是根据时序图和自相关图的特征做出判断,该方法非常直观,操作简单,但是带有主观性,不同人对图形的判断结果可能出现偏差。另一种是构造检验统计量进行平稳性检验,目前最常用的方法是单位根检验。
单位根检验的原理是判断检验序列中是否存在单位根,因为存在单位根的序列是非平稳序列 [6] 。我们利用R语言中tseries软件包中的adf.teA命令对机顶盒的销售数据进行单位根检验 [7] ,检验结果如表6所示:
由检验结果可知,p值小于0.1,认为输入的时间序列符合平稳性特征,因此我们采用ARMA模型进行建模与预测。下一步的工作是要选择合适的ARMA模型,即需要寻找合适的p和q的值来给模型进
Table 4. Exponential smoothing results of different a value
表4. 不同a取值下的指数平滑结果
Table 5. Exponential smoothing results of different a value
表5. 不同a取值下的指数平滑结果(续)
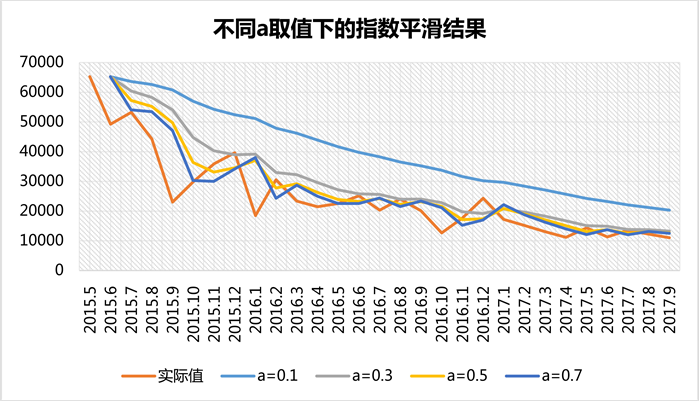
Figure 4. Forecasting result of different smoothing factor
图4. 不同平滑系数下的预测结果
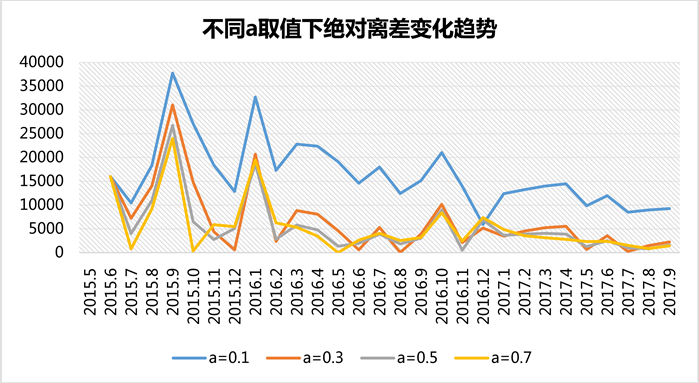
Figure 5. Absolute deviation variation trend of different smoothing factor
图5. 不同平滑系数下的绝对离差变化趋势
Table 6. Test result about roots of unity of decoder sales data
表6. 机顶盒销售数据单位根检验结果
行定阶。我们采用R语言中的“acf”和“pacf”这两个函数来进行判断 [8] 。
ARMA模型中p和q的选取可以参考以下原则(表7)进行识别:
结合自相关图(图6)和偏相关图(图7)可以看出:自相关表现出拖尾特征,偏自相关表现出1阶截尾特征,因此可以考虑用AR (1)模型拟合销售序列,即对原始序列建立ARMA (1, 0)模型。
为确保预测的精确性,下面将结合定量的方法对模型进行准确识别。在此可以选用AIC准则进行判断,AIC信息准则是衡量统计模型拟合优良性的一种标准,又称赤池信息量准则,它建立在熵的概念基础上,可以权衡所估计模型的复杂度和此模型拟合数据的优良性。
我们将ARMA (p, q)中所有p小于等于4,q小于等于3的情况进行组合,计算AIC值,并从其中选取AIC值达到最小即最优的模型(表8)。
Table 7. Identification principles of ARMA model
表7. ARMA模型的识别原则
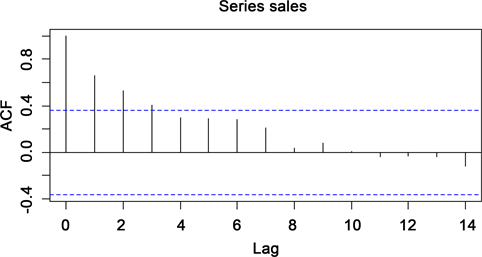
Figure 6. Self-correlation chart of decoder sales data
图6. 机顶盒销售数据自相关图
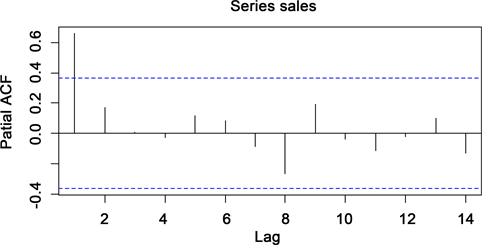
Figure 7. Partial self-correlation chart of decoder sales data
图7. 机顶盒销售数据偏自相关图
由计算结果可以看出,当p = 1,q = 1时,ARMA模型的AIC值最小,因此采用ARMA (1, 1)对模型进行定阶。
通过计算,ARMA (1, 1)模型的参数估计结果如下(表9):
下面对模型进行参数检验,参数检验包括两个部分:参数的显著性检验,以及残差的正态性和无关性检验(表10)。
从残差的无关性检验结果和残差QQ图可以得出,残差具有无关性,且符合正态性假设。因此,认为ARMA (1, 1)模型能够较好地拟合数据(图8)。
Table 8. AIC value of different ARMA (p, q) model combined
表8. ARMA (p, q)模型p/q不同组合下的AIC值
Table 9. Parameter Estimation of ARMA (1, 1) model
表9. ARMA (1, 1)模型参数估计结果
Table 10. Residual error independence results
表10. 残差无关性检验结果
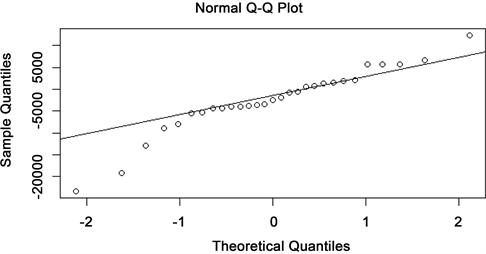
Figure 8. Test result of residual error normality
图8. 残差正态性检验结果
最后,我们利用得到的模型对2017.10,2017.11,以及2017.12月这三个月该款机顶盒产品的销售情况进行预测,预测结果如下(表11)。
2.3. 不同预测方法效果对比
在上一节中,我们分别采用了移动平均法、指数平滑法,以及ARIMA模型对T2机顶盒产品的需求进行了预测和探索,并总结出在各方法下的最优参数与最优模型。本节将对这三种方法在T2机顶盒需求预测的表现进行对比,我们分别利用移动平均法、指数平滑法和ARIMA法对2017年10月的需求数据进行预测,得到的预测结果如下(表12和图9)。
从A公司获取得知,2017年10月坎帕拉地区T2产品的实际销售为9861台。
从预测结果中可以看出,移动平均法对于趋势的表现并不明显,对于趋势的反应较慢,该方法适用于保守型企业对于需求的预测,其优点是持有足够的库存以应对市场可能发生的变化,但其缺点也同样明显:如果不能及时销售,会造成资金的积压,甚至在激烈的市场竞争中有形成呆滞库存的风险。ARIMA模型对于趋势的反应很快,但如果预测不准会有缺货的风险,可能导致客户的流失。指数平滑法介于两者之间,既反应了市场的趋势,又相对平稳保守些以应对市场变化。因此,指数平滑法更适用于A公司坎帕拉地区T2机顶盒的需求预测。
Table 11. Sales Forecasting of decoder in three months by ARMA model
表11. ARMA模型对机顶盒三个月销售情况预测
Table 12. Prediction results of decoder sales data in 2017/10 by three forecasting methods
表12. 三种预测方法对机顶盒2017.10销售情况预测
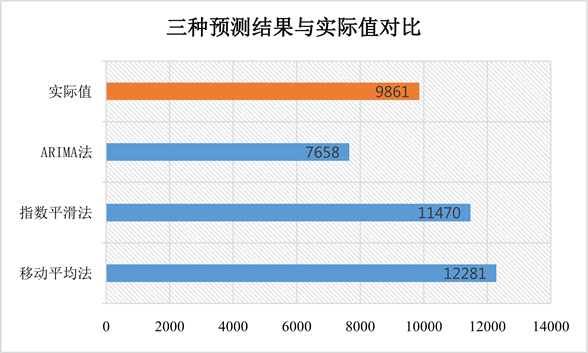
Figure 9. Comparison chart between the three predicting result and real value
图9. 三种预测结果与真实值的对比图
3. 小结
本文主要研究了当前较为常用的三种预测手段:移动平均法、指数平滑法、以及ARIMA法,针对A公司坎帕拉地区2015年5月到2017年9月的实际销售数据进行拟合。结果表明,三种方法均能对历史数据实现较为贴近的拟合。随后,本文引入2017年10月坎帕拉地区T2机顶盒的销售数据,与三种方法预测值进行对比,对比结果为:ARIMA模型对趋势的反应过度,移动平均法对趋势的反应过慢,指数平滑法介于两者之间,能够较好地完成对T2机顶盒销量的预测。