1. 引言
数据缺失是数据分析处理中的常见问题,广泛存在于社会科学、流行病学、统计学、生物学、计算机科学等领域。一个典型的数据缺失的例子是机器学习领域的推荐系统 [1] [2] [3] :要求从不完全的用户评价数据中为给定用户自动推荐感兴趣的商品列表。
大多数算法和统计学方法对数据的推断是建立在训练数据无缺失的情况下,如果将缺失数据直接作用于这些方法并不合适。因此对缺失数据的处理的一种常见的做法是将有缺失的记录丢弃, 但这会减少可能本来就不多的样本数,从而达不到相应的估计精度。此外,数据中有缺失的记录和无缺失的记录可能彼此之间存在显著差异,这意味着丢弃缺失的记录会直接影响到统计推断的结果,使估计出现严重偏差或无效,甚至得到相反的结果。
对缺失数据的处理,目前已有不少的研究 [4] [5] 。其中基于EM的缺失数据处理方法 [6] 是一种通用的不完全数据下的极大似然估计(简称EM方法,下同),该方法具有良好的收敛性以及每次迭代都能使似然函数值单调不减的良好性质。并且在满足随机缺失的假定下,该方法被证明可以从不完全数据中得到无偏估计 [7] 。因此大多数与缺失数据有关的问题中都会结合EM算法来分析。
国内对EM算法的理论研究较少,主要集中在应用研究方面:李顺静运用EM算法补齐重庆市居民的交通起止点调查表中的缺失数据,很好的展现了该算法的价值 [8] ;谷海彤等利用EM插补算法计算缺失值的插补值,并作为多重插补的初始值,得到的贝叶斯线性回归的DA多重插补结果比EM插补误差更低 [9] 。
本文工作主要分成两部分:首先利用EM方法对缺失率分别为10%、20%、30%的随机缺失数据进行自动补齐,在此基础上,将该方法应用于实际调查数据-康华医院妇产中心调查问卷中的缺失数据进行插补,并分析了当二级指标的权重不同时,补齐数据相对于未补齐数据的总体满意度变化情况。
下文内容安排如下,第1节介绍了EM方法基本原理和计算步骤,并给出了个算例。第2节介绍EM算法补齐实验室缺失数据中的应用,分析比较了EM算法在不同随机缺失率下的性能,并将EM算法应用于实际调查数据的处理,最后第3节给出了论文结论及下一步工作。
2. EM算法
EM算法由Dempster等于1977年提出,是期望最大化法的简称,通过迭代来计算极大似然估计或者后验概率分布。由于EM算法具有良好的收敛性和每次迭代都能使似然函数值单调不减的优良性质,所以许多与缺失数据有关的问题中都会结合EM算法来分析 [10] 。EM算法过程首先用缺失值由估计值替代,之后对完整数据进行参数估计,然后根据上述的参数估计值反过来再估计缺失值。EM算法包含两部分,E步是求期望,即在给定观测数据的条件下求缺失值的条件期望,并用计算出的条件期望对缺失数据进行插补;M步是做极大化估计,对M步之后的完整数据集的参数进行极大似然估计 [11] 。具体如下:设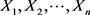 为n维正态分布总体
为n维正态分布总体 的随机样本,完全数据的两个充分统计量为:
的随机样本,完全数据的两个充分统计量为:
 (1)
(1)
 (2)
(2)
假定μ和Σ均为未知,则缺失的估计需要进行如下计算:
1) 给出μ和Σ的估计初始值。可以通过计算未缺失数据的列均值来作为每列缺失数据的初始值 [12] ,然后通过总体协方差公式求得Σ,即作为Σ的极大似然估计初始值;
2) E步:通过计算条件数学期望来求含缺失值的每一个向量 。若用
。若用 表示缺失的分量,
表示缺失的分量, 表示已知的分量,对
表示已知的分量,对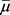 和
和 进行相应的分块变化,则
进行相应的分块变化,则 的条件正态分布的均值:
的条件正态分布的均值:
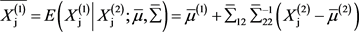 (3)
(3)
且 和
和 的条件正态分布的均值分别是:
的条件正态分布的均值分别是:
 (4)
(4)
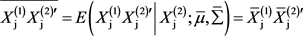 (5)
(5)
并用计算出的结果,求出充分的估计量 。
。
3) M步:计算 的最大似然估计校正值
的最大似然估计校正值 :
:
 (6)
(6)
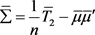 (7)
(7)
4) 重复以上的2~3步,直至 收敛为止。
收敛为止。
EM算法使用于大样本,在现实生活中有很高的使用价值,该方法能够通过在已获得的数据条件下,能稳定、可靠的找到最优值。缺点是计算复杂难度较大。利用EM算法来补齐如下4 × 3的矩阵,其中缺失值数据位于第一行第一列以及第四行第一、二列。
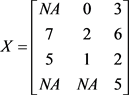
经过上述EM迭代算法步骤,经R语言编程可得:
 ,
, 
迭代算法补入的两个数据:第一行第一列为5.672,第四行第一、二列数据为别为6.539,1.461。
3. EM算法的应用案例
本文实证研究分为两部分:第一部分是比较多变量在10%、20%、30%三种不同缺失率下,用EM算法补齐三层神经网络训练参数的随机缺失数据,计算其相对误差。第二部分分别用多重插补以及EM算法对康华医院妇产中心调查问卷中的缺失数据进行插补,并给出未补齐数据、用多重插补补齐数据以及用EM算法补齐数据的患者满意度的计算公式,探讨当二级指标的权重不同时,用两种算法补齐数据相对于未补齐数据的总体满意度增加率。
3.1. 案例一——关于网络训练参数的随机缺失补齐
本案例选用的数据集为:用6000个样本数据,构造三层神经网络,隐层有120个节点,学习率为0.0005,传递函数为双曲正切函数,共训练300轮而得到的4 × 3的不含缺失值的矩阵,其中40代表测试次数,三个属性依次为最小训练误差( )、测试误差(
)、测试误差( )、训练时间(
)、训练时间( )。为验证不同缺失率下EM算法补齐数据的精度,通过随机缺失的方式来构造10%缺失率、20%缺失率以及30%缺失率的三个不同矩阵,记为
)。为验证不同缺失率下EM算法补齐数据的精度,通过随机缺失的方式来构造10%缺失率、20%缺失率以及30%缺失率的三个不同矩阵,记为 其三个矩阵含缺失值的数目分别为12个,24个和36个,缺失位置如图1。
其三个矩阵含缺失值的数目分别为12个,24个和36个,缺失位置如图1。
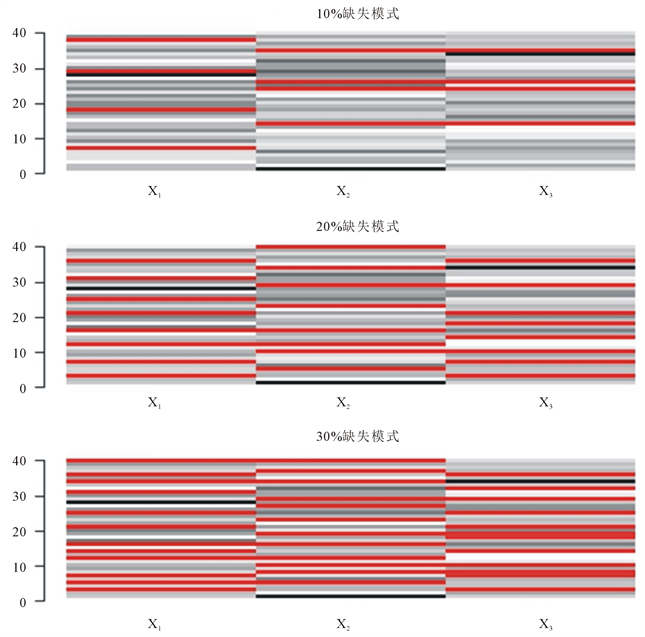
Figure 1. Missing location of different missing ratios
图1. 不同缺失比率的缺失位置图
多元正态性检验
在做EM算法补齐数据之前,需对各变量进行正态分布检验。面对多元正态性检验问题,由于多元正态随机向量 ,那么P与μ的马氏距离(
,那么P与μ的马氏距离(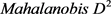 )的平方服从自由度为p的卡方分布。
)的平方服从自由度为p的卡方分布。
 (8)
(8)
首先通过多元正态性检验的Q-Q图来判断变量是否服从正态分布,用R中qqplot函数分别画出 各自的QQ-plot,如图2中的四张图所示,发现点大部分都落在斜率为1,截距项为0的直线附近,故认为其数据近似服从多元正态分布。
各自的QQ-plot,如图2中的四张图所示,发现点大部分都落在斜率为1,截距项为0的直线附近,故认为其数据近似服从多元正态分布。
进一步验证变量的正态性,采用了R中的mshapiro.test函数,通过对 数据集中的三个变量做正态性检验,得到的各自P值如表1,结果显示p值都大于0.05,故认为其四个数据集中的变量均服从正态分布。
数据集中的三个变量做正态性检验,得到的各自P值如表1,结果显示p值都大于0.05,故认为其四个数据集中的变量均服从正态分布。

Table 1. Normal test p-value table
表1. 正态性检验p值表
通过EM迭代算法的原理,在R语言进行编程,首先计算不含缺失值的列均值来作为初始数据来补齐,并得到Σ的极大似然估计初始值,然后计算条件数学期望来求含缺失值的每一个向量 ,并计算充分的估计量
,并计算充分的估计量 ,通过极大似然估计法不断校正
,通过极大似然估计法不断校正 ,直到收敛。迭代算法补入的三个矩阵的数据与其
,直到收敛。迭代算法补入的三个矩阵的数据与其
本来的数据相对误差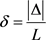 ,
,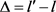 表示误差
表示误差 表示插补的值,l表示真值,计算出当数据缺失率为
表示插补的值,l表示真值,计算出当数据缺失率为
10%,20%,30%时 [13] ,计算的相对误差均值为别为0.0947,0.0371,0.0413,均小于0.1,可见EM算法在处理低缺失率的数据集的效果比较稳定,且精度比较好,相对误差的箱线图如图3。
3.2. 案例二——康华医院患者满意度调查数据补齐
3.2.1. 调查背景与目的
EM算法常用于医学研究中,尤其是临床医学中很常见,因为在临床医学需要对同一试验单位进行多次重复观测,而在这个过程中由于各种原因经常导致试验观测数据缺失,如动物的意外死亡,记录仪器发生故障,或是被调查者拒绝回答相关调查项目等。对于缺失值通常的做法是删去具有缺失的观察记录,但这样会造成信息的损失以及分析结果的偏性 [14] 。为了保证信息的完整,必须对缺失数据进行适当的处理。EM算法相比别的算法的优势在于,以“补缺”的方式将含有缺失值的“不完全资料”转化为“完全资料”,从而提高了估计精度。
东莞康华医院由东莞康华集团投资建成,是目前全国首家最大规模的民营三甲医院,2017年,医院为进一步提高医院患者满意度,严抓医疗服务质量,开展第三方患者满意度调查,以检验与提升医院各项服务工作。医院患者满意度调查具体目的如下:
1) 了解医院患者总体满意度水平;
2) 了解医院各环节服务满意度水平;
3) 了解医院各科室服务满意度水平;
4) 收集医院患者反馈的意见与建议;
5) 发现医院服务存在的问题与不足;
6) 为进一步提升医院服务提出相应建议。

Figure 3. Box plot of relative error for different missing rate datasets
图3. 不同缺失率数据集相对误差的箱线图
3.2.2. 调查对象与方法
本次调查对象为调研期间到达康华医院就诊的患者,包括门急诊患者、住院患者和出院患者 [15] 。具体为:门急诊患者(调查当天在医院接受门诊或急诊服务的患者),住院患者(调查期间在医院接触住院服务,且住院时间在1天以上的住院患者),出院患者(调查前三个月内接受过医院服务的住院患者,且调查时已出院)。
根据医院患者满意度调查对象,项目调查采取定量问卷调查的形式,并分别采用现场访问、病房访问以及电话访问三种方法进行。具体如表2。
3.2.3. 调查内容与说明
本项目调查内容采用医院节点服务满意度调查,即从患者进入医院到离开医院期间所接触的服务出发,了解患者对其所接触服务点的满意度评价 [16] ,从而为医院整改提供具体化的建议。其中门诊整体各节点服务的一级指标为总体满意度,二级指标分别为:就医环境、窗口服务、接诊服务、医技服务和护理服务。住院整体各节点服务的一级指标为总体满意度,二级指标分别为:环境后勤、医生服务、护理服务和医技检查。根据这些指标体系以及各个科室的不同服务,建立了包含健康管理中心、门诊患者、血透中心患者、重症医学科患者、住院妇产中心以及住院患者6种不同的调查问卷。
3.2.4. 数据描述与整理
总的数据集包含健康管理中心、门诊患者、血透中心患者、重症医学科患者、住院妇产中心以及住院患者在内的6个科室的现场访问的样本数据以及包含住院妇产中心和住院患者在内的2个电话访问的样本数据。为了充分利用好现场访问和电话访问这两个类型的样本数据,了解患者在医院的整个满意度调查 [17] ,本案例只挑选了住院妇产中心(电访)这个数据集来补齐数据。
住院妇产中心(电访)包含41个样本,问卷包含25个能体现打分的有效问题,其中有9个问题的回答缺失率超过30%,而这些问题如,第5题(3、您对医院订餐、送餐和饭菜情况是否满意?),第8题(1、您对护士响应呼叫与帮助的及时性是否满意?)这种很多患者没有体验过,所以没有评价,对于这种大比例缺失的情况填补价值不大,故对这9个问题予以删除。删除过9个问题后,得到了一个41行,16列的数据集,16个问题用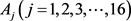 来表示,如表3,此时每个问题的缺失情况如图4。
来表示,如表3,此时每个问题的缺失情况如图4。
3.2.5. 缺失数据处理方法——多重插补和EM算法
康华医院患者满意度调查数据中,由于被调查者未能体验到医院的某些服务,导致数据缺失,与其他任何观测变量或未观测变量都不相关。对数据做了MCAR检验,p值为0.059,故接受原假设,认为该数据为完全随机缺失。
对于MCAR的缺失模式,运用多重插补的方法,利用SPSS对缺失变量进行插补。通过对每个缺失值都构造20个插补值,产生了20个完全数据集,计算了每个数据集的均值和方差的点估计值,并求出了各个变量用于评价多重插补的指标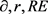 的值,详细的归因模型如表4。
的值,详细的归因模型如表4。
Table 2. Summary of sampling methods at Kanghua Hospital
表2. 康华医院抽样方法汇总
Table 3. Questionnaires and labels for part of the questionnaires
表3. 妇产中心部分问卷题目及标号
Table 4. Multiple Imputation attribution model
表4. 多重插补的归因模型
未补齐之前的初始数据的含缺失值的各变量的平均均值和平均标准差为4.299,0.875,而构造了20个完整插补数据集后,通过比较每个完整数据集的平均均值和平均标准差,按照平均均值和平均标准差越接近未补之前的平均均值和平均标准差的原则,从而选取了第15个数据集作为多重插补的最终结果,其平均均值和平均标准差分别为4.23,0.90。将多重插补的结果与用EM算法编程得到的结果相比如表5。
3.2.6. 妇产中心总体满意度评价
回到医院做调查问卷的本意,是希望通过问卷的形式了解患者对医院各项服务的满意度情况,以一级指标为总体满意度为因变量S,自变量为二级指标:环境后勤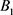 、医生服务
、医生服务 、护理服务
、护理服务 和医技检
和医技检
查 ,且
,且 ,则S与
,则S与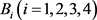 的关系可表示为:
的关系可表示为:
 (9)
(9)
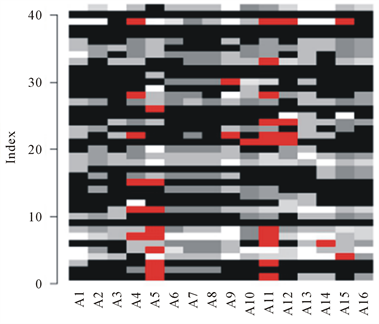
Figure 4. Missing locations for different variables
图4. 不同变量缺失位置
Table 5. Multiple imputation and EM algorithm complete data results
表5. 多重插补和EM算法补齐数据结果
其中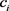 表示各自变量前面的系数。
表示各自变量前面的系数。
由于问卷调查数据的补齐是无监督信号的,所以不能通过对比补齐的数据和标准答案的相对误差精度来比较方法的优劣。可利用上文对缺失数据的处理的基础,用三级指标的均值来作为二级指标数据,得到未补齐数据、用EM算法补齐数据、用多重插补补齐数据各自的二级指标数值,并得到对应的总体满意度公式:
未补齐数据的公式:
 (10)
(10)
用EM算法补齐数据后的公式:
 (11)
(11)
用多重插补补齐数据后的公式:
 (12)
(12)
EM算法补齐数据相对于未补齐数据的总体满意度增加率:
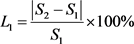 (13)
(13)
以及多重插补补齐数据相对于未补齐数据的总体满意度增加率:
 (14)
(14)
当自变量前的系数及各二级指标的权重为 时,计算出
时,计算出 为0.356%,即EM算法补齐数据后的总体满意度相对于未补齐数据的总体满意度增加了0.356%,而
为0.356%,即EM算法补齐数据后的总体满意度相对于未补齐数据的总体满意度增加了0.356%,而 为0.253%,即多重插补算法补齐数据后的总体满意度相对于未补齐数据的总体满意度增加了0.253%,EM算法补齐数据后的增加率比多重插补算法补齐数据后的增加率提高了0.103%。
为0.253%,即多重插补算法补齐数据后的总体满意度相对于未补齐数据的总体满意度增加了0.253%,EM算法补齐数据后的增加率比多重插补算法补齐数据后的增加率提高了0.103%。
当自变量前的系数及各二级指标的权重为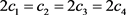 时,计算出
时,计算出 为0.174%,即EM算法补齐数据后的总体满意度相对于未补齐数据的总体满意度增加了0.174%,而
为0.174%,即EM算法补齐数据后的总体满意度相对于未补齐数据的总体满意度增加了0.174%,而 为0.172%,即多重插补算法补齐数据后的总体满意度相对于未补齐数据的总体满意度增加了0.172%,此时EM算法补齐数据后的增加率和多重插补算法补齐数据后的增加率相差无几。
为0.172%,即多重插补算法补齐数据后的总体满意度相对于未补齐数据的总体满意度增加了0.172%,此时EM算法补齐数据后的增加率和多重插补算法补齐数据后的增加率相差无几。
当自变量前的系数及各二级指标的权重为 时,计算出
时,计算出 为0.162%,即EM算法补
为0.162%,即EM算法补
齐数据后的总体满意度相对于未补齐数据的总体满意度增加了0.162%,而 为0.216%,即多重插补算法补齐数据后的总体满意度相对于未补齐数据的总体满意度增加了0.216%,EM算法补齐数据后的增加率比多重插补算法补齐数据后的增加率降低了0.054%。
为0.216%,即多重插补算法补齐数据后的总体满意度相对于未补齐数据的总体满意度增加了0.216%,EM算法补齐数据后的增加率比多重插补算法补齐数据后的增加率降低了0.054%。
4. 小结
本文是基于EM算法实证分析,第一个案例通过比较多变量在10%、20%、30%三种不同缺失率下,用EM算法补齐三层神经网络训练参数的随机缺失数据,得到三者的相对误差均小于0.1,验证了EM算法的在低缺失率情况下的高准确性。第二个案例分别用多重插补(基于logistic回归)以及EM算法对康华医院妇产中心调查问卷中的缺失数据进行插补,并给出未补齐数据、用多重插补补齐数据以及用EM算法补齐数据的患者满意度的计算公式,探讨了当二级指标的权重不同时,用两种算法补齐数据相对于未补齐数据的总体满意度增加率。从实证结果可得到:1) 当权重不同时,EM算法补齐数据后的增加率相比于多重插补算法补齐数据后的增加率可增可减;2) 用EM算法补齐数据后的增加率和多重插补算法补齐数据后的增加率都不大,原因可能有对于二级指标护理服务下面的8个问题,由于每个问题的缺失率超过了30%,故没有用算法补齐,导致计算 中的
中的 系数都一样,还有本调查问卷的打分体系是0~5分,所以用算法补齐后的数据与均值相差不大。
系数都一样,还有本调查问卷的打分体系是0~5分,所以用算法补齐后的数据与均值相差不大。