1. 引言
中国是一个传统农业大国,对钾肥的需求量非常大,钾盐是制作钾肥的重要原材料之一同时也是重要的工业原料,中国非常短缺,主要原因是钾盐资源的勘探不明。四川盆地下中三叠统嘉陵江组和雷口坡组广泛发育难溶性固态钾盐——杂卤石(K2SO4∙MgSO4∙2CaSO4∙2H2O)是制造钾肥的原料之一。1991年发现的农乐杂卤石矿床表明四川盆地三叠纪钾盐具有良好的勘探开发前景。因此,加大四川盆地海相钾盐的勘探开发力度有助于缓解我国钾肥缺乏的困境,提供重要的工业原材料。地球物理测井方法具有纵向速率高,解释精确、快速的特点,是我国主要用以识别划分固态钾盐的主要方法之一。2014年,陈科贵、李利等人归纳总结了四川盆地南充盐盆固态钾盐的测井响应特征并对南充盐盆盐岩层位进行了重新梳理 [1] ;2014年,陈科贵、李春梅等提出了用交会图法来识别固态钾盐矿物 [2] 。但是传统测井方法识别过于依赖个人主观因素,速度也慢,识别误差较大,很难对杂卤石进行精确的划分和区别。2016年,陈科贵等将模式识别法引入到钾盐领域 [3] [4] ,建立BP神经网络模型和支持向量机模型开展杂卤石层识别,识别正确率达80%以上,效果良好;2017年,陈科贵、李进等人提出了改进的支持向量机杂卤石识别法 [5] ,也取得了不错的效果。
判别分析是在分类确定的条件下,根据某一研究对象的各种特征值判别其类型归属问题的一种多变量统计分析方法,目前在气候分类、农业区划、土地类型划分等方面有着广泛的应用。笔者将判别分析中的Fisher判别法引入到钾盐勘探领域,以测井理论和数学统计理论为基础,开展固态钾盐杂卤石的识别与储层的划分。Fisher判别分析法相对于传统测井识别法具有操作简单,识别速度快,样本数据要求低等优点,并且可以有效地减小人为因素引起的误差,提高识别精度和速率。为了进一步提高固态钾盐岩性划分的精度,我们基于前人的研究经验,提出了主成分分析——Fisher判别方法识别杂卤石。研究表明,该方法相对于传统测井识别法具有更广阔的勘探应用前景。
2. 研究区概况
川中地区位于四川盆地川西凹陷带中东部,构造上为一次级凹陷 [6] 。四川盆地三叠纪地层钾盐矿物广泛分布,岩性复杂,主要的钾盐矿物有杂卤石、无水钾镁矾、硫锶钾石,钾石膏等。研究区是四川盆地盐类沉积最广的次级盐盆,主要含盐构造有广安构造、南充构造、合川大石桥构渠县鲜度构造及大英构造。川中三叠系地层钾盐沉积受苏皖运动和印支运动的影响,在海退期沉积石膏、杂卤石等蒸发岩类,其中杂卤石在广安构造地区和龙女寺构造地区沉积情况较好 [7] 。但是川中地区的杂卤石多与其他岩石矿物互存 [8] [9] ,常伴随有硬石膏、岩盐、泥岩、碳酸盐岩等矿物发育,传统的测井方法很难判别区分杂卤石。
3. 杂卤石测井响应特征
四川盆地的发育的固态钾盐主要为杂卤石 [10] [11] ,杂卤石隶属高电阻率难溶含钾矿物,含有结晶水,密度(DEN)高值的区间为2.72~2.78 g/cm3。常规的杂卤石测井响应特征为:自然伽马(GR)相对较高;声波时差(AC)一般为55~95 us/ft,高补偿中子(CNL)相对高值。在沉积作用下,四川盆地的杂卤石分布于石膏、硬石膏和盐岩之中,形态主要有层状、浸染状、团块状、星点浸染状或板块状四种。因杂卤石含有大量的K,故在自然伽马测井能谱曲线上,杂卤石层的响应是非常明显的,反映为高K,低Th和U。因为研究区的地层条件,杂卤石层中杂卤石与石膏互相黏连,且还有别的黏土矿物的存在,种类多含量大,给杂卤石的区分造成了不便。因此,笔者以钾盐矿物的测井响应特征为基础,测井解释方法原理和数学统计理论为指导,开展交会图法和PCA-Fisher判别分析法钾盐矿物定性识别研究,最后用准确的岩心分析资料验证识别结果,比较两种方法的优缺点。
4. 杂卤石交会图识别标志
交会图法是一种常用的岩性识别技术。将两种或多种数据在平面图上交会,根据其交会点的坐标可以比较大致地定出岩性变化的范围。在地球物理测井方法中,经常用五条常规测井曲线——自然伽马(GR)、中子密度(CNL)、声波时差(AC)、密度(DEN)、深侧向电阻率(RLLD)来反映岩性的变化。杂卤石具有放射性,自然伽马及自然伽马能谱测井信息是识别其最有效的信息之一,而电阻率曲线,孔隙度曲线又能很好的分辨泥岩及其他蒸发岩。考虑到不同岩性的电性特征存在差异,因此我们建立了深侧向电阻率(RLLD)和三孔隙度(AC、DEN、CNL)、自然伽马(GR)的曲线交会图,开展研究区固态钾盐矿物的识别。(图1)。
通过分析对比图中杂卤石与泥岩层各方面特性,可以看到杂卤石声波时差相对较小,密度较大;而泥岩层声波时差相对较大,密度较小。因此识别杂卤石的重叠图中,杂卤石出现幅度差的差异越大,就代表杂卤石越纯。使用交会图法可以较好的区分出岩盐,绿豆岩和杂卤石。但是对于泥质杂卤石,膏质杂卤石,杂卤石膏岩不是很好识别,主要是因为杂卤石的含量不高,岩性分界线很难划分。交会图对于大部分岩性都能进行大致的区分,但是很多岩性重叠,且容易受到主观因素的影响,使区分难度大大增加。
5. PCA-Fisher判别分析法
Fisher判别分析的基本思想是通过投影,使得总体在所有多维空间的样本点投影到一维空间上。对于投影的要求是不同分类的组与组之间类间离差尽可能大,同类分组的类内离差尽可能小,然后利用方差分析的方法推导出判别函数,此次研究我们使用的是线性判别函数。
5.1. PCA主成分分析原理
主成分分析是一种统计分析方法,核心思想是找出几个彼此之间互不相关的综合变量在力求数据信息丢失最少的原则下,对高维变量空间进行降维,使这些综合变量能够尽可能地代表原来变量的信息量。
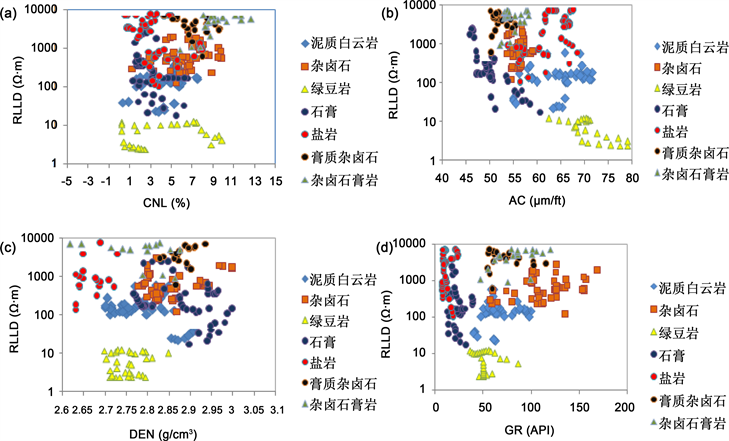
Figure 1. Rendezvous method for identifying rock minerals
图1. 交会图法识别岩石矿物。(a) CNL与RLLD交会图;(b) AC与RLLD交会图;(c) DEN与RLLD交会图;(d) GR与RLLD交会图
假设
为原变量,
为新变量,做线性组合为
,主成分分析数学模型为 [12] [13] [14] :
其中:
和
(
)相互无关; ;
;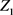 是
是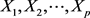 的一切线性组合中方差最大者;
的一切线性组合中方差最大者;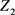 是与
是与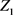 不相关的所有
不相关的所有 的所有线性组合中方差最大者;……;
的所有线性组合中方差最大者;……; 是与
是与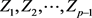 不相关的
不相关的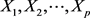 的所有线性组合中方差最大者。
的所有线性组合中方差最大者。
主成分的求解主要就是确定 (
(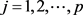 )在主成分
)在主成分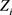 (
(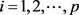 )上的系数
)上的系数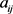 ,计算过程如下:
,计算过程如下:
1) 计算相关系数矩阵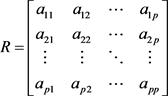 ,
,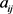 (
( )为原变量
)为原变量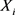 和
和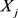 的相关系数。
的相关系数。
2) 解特征方程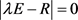 ,求出特征值,并按从大到小排列
,求出特征值,并按从大到小排列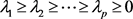 ;分别求出对应特征值
;分别求出对应特征值 的特征向量
的特征向量 使
使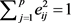 。
。
3) 计算第k个主成分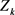 的贡献率
的贡献率 ,主成分
,主成分 (
(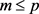 )的累计贡献率
)的累计贡献率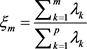 。如果m个成分的累计贡献率≥80%,则说明m个成分包含了p个成分的大部分信息,则主成分的个数就为m。
。如果m个成分的累计贡献率≥80%,则说明m个成分包含了p个成分的大部分信息,则主成分的个数就为m。
5.2. Fisher判别分析求解方法
设有m个样本 ,每个样本都有
,每个样本都有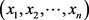 个指标。而样本的均值常量分别为
个指标。而样本的均值常量分别为 。所以从样本中抽出ni的样本,所以可以得到 [15] [16] :
。所以从样本中抽出ni的样本,所以可以得到 [15] [16] :
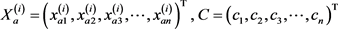
设判别函数为: 。
。
计算组内样本均值和总样本均值,并且分别求出组内差e与组间差b。
 (E为组内离差平方和)
(E为组内离差平方和)
 (B为组间离差平方
(B为组间离差平方

为了使离差比λ达到最大,所以要使得e的值趋近于1,所以即成立为一个在cTEc=1的条件下,使得cTBc的取得最大值的问题。
根据极值存在条件,在有约束的条件下,运用拉格朗日乘子法,令 ,可求得
,可求得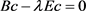 进一步对其整理可以得出
进一步对其整理可以得出 ,λ和c分别为
,λ和c分别为 的最大特征值和对应的特征向量,从而求出判别函数。
的最大特征值和对应的特征向量,从而求出判别函数。
6. 建立PCA-Fisher判别分析模型
PCA-Fisher判别分析模型是通过建立数学分析的模型进行岩性划分。首先以测井响应中的主要相关变量GR、CNL、AC、CAL、DEN、Rt和自然伽马能谱中Th、K、U的测井曲线作为输入进行PCA主成份分析,找到可以代替原变量的主变量。然后以筛选出的主变量测井曲线值作为输入建立Fisher判别分析模型开展研究区钾盐层段岩性识别。最后,以准确的录井结果验证模型的性能,并改进模型(表1)。
6.1. 测井数据归一化
为了有效的避免数据量纲和量纲单位对实验数据的影响,我们对上述数据进行归一化处理,使得数据处于在同一个数量等级测试。我们发现GR,AC,CNL,DEN,U,Th,K测井曲线做线性归一化,Rt曲线做对数归一化最为合适,图2为Rt曲线线性归一化和对数归一化对比图。
6.2. 建立PCA分析模型
用SPSS软件处理归一化后的测井数据,求出样本数据的特征值、方差贡献率和累积方差贡献率。表2为变量的方差分析表。
通过分析上述表格可得出中子密度(CNL)、声波(AC)、密度(DEN)、自然伽马(GR)和深浅双侧向电阻率(Rt)五个主成份变量对于结果的累计贡献率影响最大,达到了89.993%,基本包含了大部分的信息变量,

Table 1. Part of the learning sample
表1. 为部分学习样本
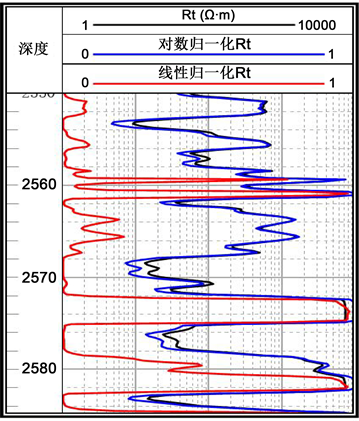
Figure 2. Linear normalization and logarithmic normalization comparison diagram
图2. 线性归一化和对数归一化对比图
Table 3. Part of the sample main component score
表3. 部分样本主成分得分
因此我们可以以这五个作为输入建立fisher判别分析模型(表3)。
6.3. 建立Fisher分析判别模型
首先根据岩心,薄片,录井资料,我们在川中研究区优选了120个测试样本。样本的选取原则:尽量不选择岩层较薄和岩层界点附近的样品,这些地方的样品受到围岩和其他方面的影响较大,对于岩石指示并不明显。通过对变量的主成分分析发现CNL、AC、DEN、GR和Rt五个主成份变量的方差累积贡献率达到了89.99%,这5个主变量的测井信息可以较好的反映岩性变化。在判别的过程中,需要对测井数据进行归一化预处理,即通过变换处理将数据的输入和输出限制在[0,1]的区间内。大多数测井曲线如GR、AC、DEN和CNL进行线性归一化即可,但Rt为非线性对数曲线,需要先进行对数变换。从交会图可以看出绿豆岩、石盐的测井曲线差异较大,利用Fisher判别时为了减少分类数量,仅对难区分其他5种岩性进行判别。选择研究区的学习样品,经过典则判别函数对样品进行投影,建立的典则判别函数F1、F2:

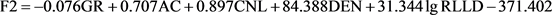
从建立的典则判别函数交会图3上可以看出该方法能较好的将几种岩性分开,特别是白云岩、石膏等岩性,表明该方法具有较好的岩性识别能力。
判别过程中,需要建立分类判别函数,表达式如下:

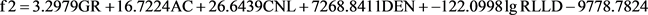


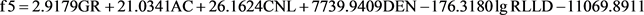
f1、f2、f3、f4、f5是fisher判别分析法得到的岩性概率函数。分别对应杂卤石(1)、石膏(2)、白云岩(3)、膏质杂卤石(4)、杂卤石膏岩(5)。将建立的模型样本带入上述岩性概率函数中计算,得到的f值与所对应岩石类型进行比对,得出岩性判断结果。通过对120个测试样本进行测试(见表4),发现杂卤石的判别率达到了88.9%,膏质杂卤石

Figure 3. Canonical function rendezvous
图3. 典则函数交会图
和杂卤石膏岩的判别性较差,但是整体的判别正确率达到了82.9%,准确率较高。
以研究区富集有杂卤石的X井为例,将建立的fisher判别模型进行实际应用,开展研究区杂卤石的定性识别(如图4),并与录井结果进行对比,评价模型的性能。从图上可以看出,Fisher法识别杂卤石与录井结果符合度较高,模型性能较好,但是在岩石交界面处仍然有较大的误差。这是因为岩石交界面处杂卤石多于其他岩石矿物相结合,岩性复杂,导致识别准确率降低。
7. 结论
1) 通过交会图法的研究和分析,我们发现交会图法虽然简单明了,但是其岩性判断图形重合,不明显,导致识别难度较大,速度较慢,如果将多种岩性一起进行识别,判断的正确率就会大大降低。
2) Fisher判别法不受人为因素的影响,具有方法简单,可操作性强等优点,可直接利用测井解释软件进行自动解释,判别速度较快,准确率较高。以主成分分析处理后的测井数据为基础,数学统计理论为指导,建立Fisher判别分析模型开展研究区的钾盐层段定性识别,整体的判别正确率达到了82.9%,准确率较高。
3) 和交会图法相比,Fisher判别分析模型识别正确率和识别速度都有了较大的提高,更加适用于在
复杂的岩层中寻找杂卤石等含钾矿物,所以该方法有较高的应用价值。
基金项目
国家自然科学基金项目“四川盆地油钾兼探的地球物理评价方法研究”,编号“41372103”和“国家重点研发计划课题”,编号“2017YFC0602804”联合资助。
NOTES
*通讯作者。